 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances and Trends in Multimodal Deep Learning: A Review
Paper and Code
May 24, 2021
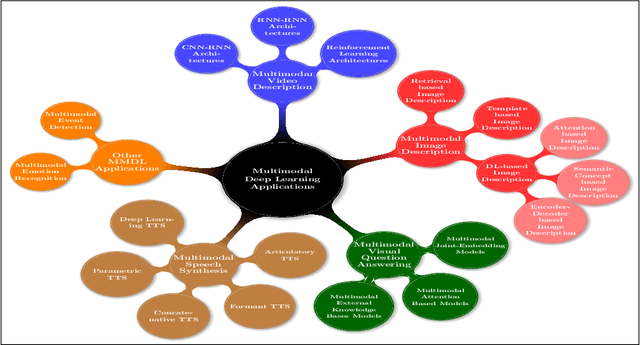

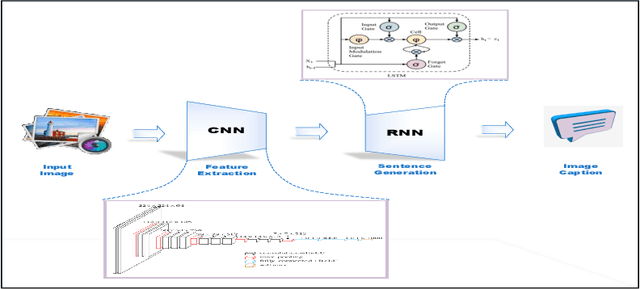
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of past and current baseline approaches and an in-depth study of recent advancements in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning applications is proposed, elaborating on different applications in more depth. Architectures and datasets used in these applications are also discussed, along with their evaluation metrics. Last, main issues are highlighted separately for each domain along with their possible future research directions.