 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Generative Learning for High-Resolution Medical Image Generation
Jun 19, 2024



Integration of quantum computing in generative machine learning models has the potential to offer benefits such as training speed-up and superior feature extraction. However, the existing quantum generative adversarial networks (QGANs) fail to generate high-quality images due to their patch-based, pixel-wise learning approaches. These methods capture only local details, ignoring the global structure and semantic information of images. In this work, we address these challenges by proposing a quantum image generative learning (QIGL) approach for high-quality medical image generation. Our proposed quantum generator leverages variational quantum circuit approach addressing scalability issues by extracting principal components from the images instead of dividing them into patches. Additionally, we integrate the Wasserstein distance within the QIGL framework to generate a diverse set of medical samples. Through a systematic set of simulations on X-ray images from knee osteoarthritis and medical MNIST datasets, our model demonstrates superior performance, achieving the lowest Fr\'echet Inception Distance (FID) scores compared to its classical counterpart and advanced QGAN models reported in the literature.
Semantic Consistency and Identity Mapping Multi-Component Generative Adversarial Network for Person Re-Identification
Apr 28, 2021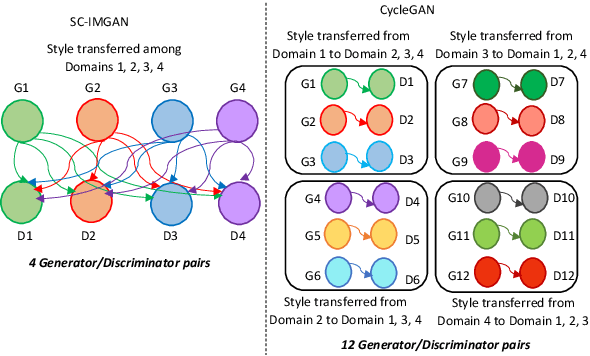
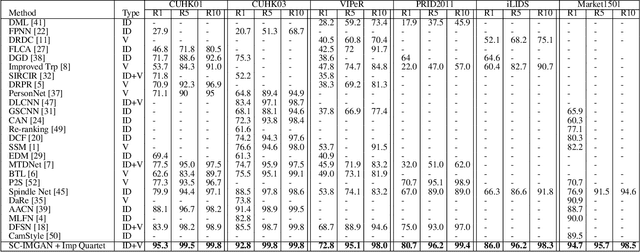
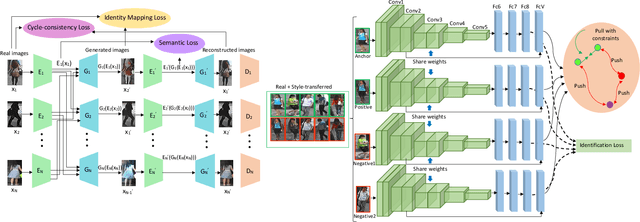
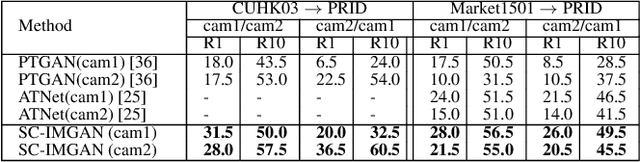
In a real world environment, person re-identification (Re-ID) is a challenging task due to variations in lighting conditions, viewing angles, pose and occlusions. Despite recent performance gains, current person Re-ID algorithms still suffer heavily when encountering these variations. To address this problem, we propose a semantic consistency and identity mapping multi-component generative adversarial network (SC-IMGAN) which provides style adaptation from one to many domains. To ensure that transformed images are as realistic as possible, we propose novel identity mapping and semantic consistency losses to maintain identity across the diverse domains. For the Re-ID task, we propose a joint verification-identification quartet network which is trained with generated and real images, followed by an effective quartet loss for verification. Our proposed method outperforms state-of-the-art techniques on six challenging person Re-ID datasets: CUHK01, CUHK03, VIPeR, PRID2011, iLIDS and Market-1501.
* Accepted in WACV 2020
Pose-driven Attention-guided Image Generation for Person Re-Identification
Apr 28, 2021
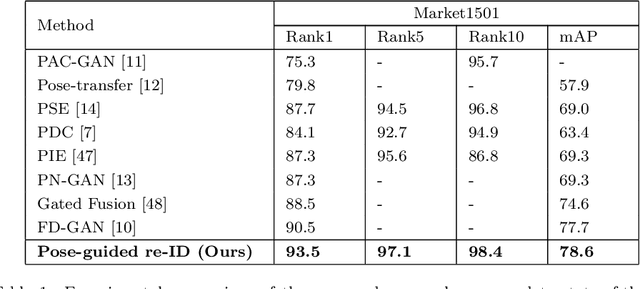

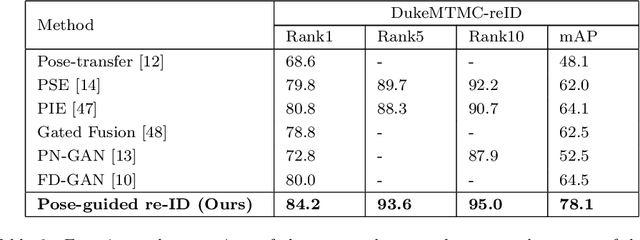
Person re-identification (re-ID) concerns the matching of subject images across different camera views in a multi camera surveillance system. One of the major challenges in person re-ID is pose variations across the camera network, which significantly affects the appearance of a person. Existing development data lack adequate pose variations to carry out effective training of person re-ID systems. To solve this issue, in this paper we propose an end-to-end pose-driven attention-guided generative adversarial network, to generate multiple poses of a person. We propose to attentively learn and transfer the subject pose through an attention mechanism. A semantic-consistency loss is proposed to preserve the semantic information of the person during pose transfer. To ensure fine image details are realistic after pose translation, an appearance discriminator is used while a pose discriminator is used to ensure the pose of the transferred images will exactly be the same as the target pose. We show that by incorporating the proposed approach in a person re-identification framework, realistic pose transferred images and state-of-the-art re-identification results can be achieved.
End-to-End Domain Adaptive Attention Network for Cross-Domain Person Re-Identification
May 07, 2020

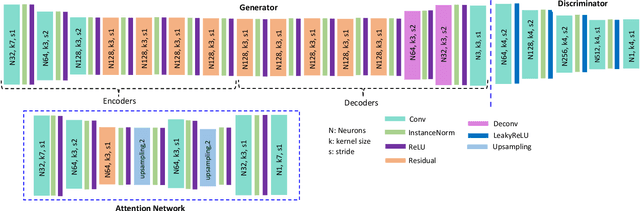

Person re-identification (re-ID) remains challenging in a real-world scenario, as it requires a trained network to generalise to totally unseen target data in the presence of variations across domains. Recently, generative adversarial models have been widely adopted to enhance the diversity of training data. These approaches, however, often fail to generalise to other domains, as existing generative person re-identification models have a disconnect between the generative component and the discriminative feature learning stage. To address the on-going challenges regarding model generalisation, we propose an end-to-end domain adaptive attention network to jointly translate images between domains and learn discriminative re-id features in a single framework. To address the domain gap challenge, we introduce an attention module for image translation from source to target domains without affecting the identity of a person. More specifically, attention is directed to the background instead of the entire image of the person, ensuring identifying characteristics of the subject are preserved. The proposed joint learning network results in a significant performance improvement over state-of-the-art methods on several benchmark datasets.
A Deep Four-Stream Siamese Convolutional Neural Network with Joint Verification and Identification Loss for Person Re-detection
Dec 21, 2018
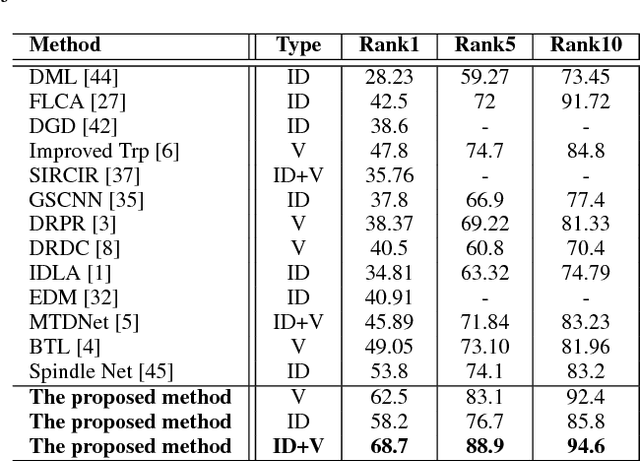
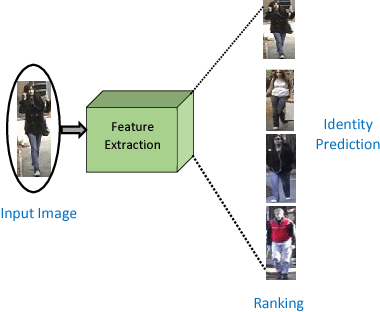
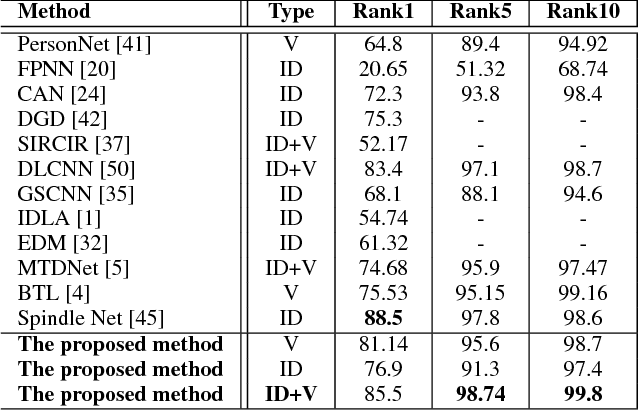
State-of-the-art person re-identification systems that employ a triplet based deep network suffer from a poor generalization capability. In this paper, we propose a four stream Siamese deep convolutional neural network for person redetection that jointly optimises verification and identification losses over a four image input group. Specifically, the proposed method overcomes the weakness of the typical triplet formulation by using groups of four images featuring two matched (i.e. the same identity) and two mismatched images. This allows us to jointly increase the interclass variations and reduce the intra-class variations in the learned feature space. The proposed approach also optimises over both the identification and verification losses, further minimising intra-class variation and maximising inter-class variation, improving overall performance. Extensive experiments on four challenging datasets, VIPeR, CUHK01, CUHK03 and PRID2011, demonstrates that the proposed approach achieves state-of-the-art performance.