 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Integrated Actuation-Perception Framework for Robotic Leaf Retrieval: Detection, Localization, and Cutting
Aug 09, 2022
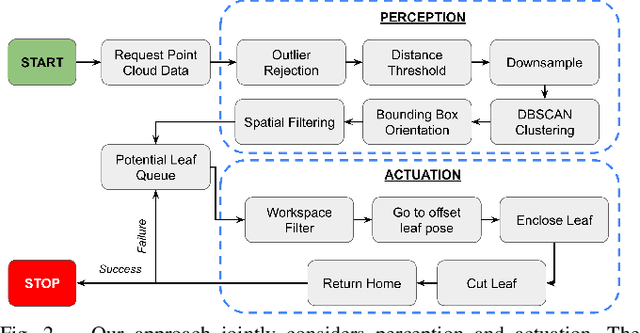


Contemporary robots in precision agriculture focus primarily on automated harvesting or remote sensing to monitor crop health. Comparatively less work has been performed with respect to collecting physical leaf samples in the field and retaining them for further analysis. Typically, orchard growers manually collect sample leaves and utilize them for stem water potential measurements to analyze tree health and determine irrigation routines. While this technique benefits orchard management, the process of collecting, assessing, and interpreting measurements requires significant human labor and often leads to infrequent sampling. Automated sampling can provide highly accurate and timely information to growers. The first step in such automated in-situ leaf analysis is identifying and cutting a leaf from a tree. This retrieval process requires new methods for actuation and perception. We present a technique for detecting and localizing candidate leaves using point cloud data from a depth camera. This technique is tested on both indoor and outdoor point clouds from avocado trees. We then use a custom-built leaf-cutting end-effector on a 6-DOF robotic arm to test the proposed detection and localization technique by cutting leaves from an avocado tree. Experimental testing with a real avocado tree demonstrates our proposed approach can enable our mobile manipulator and custom end-effector system to successfully detect, localize, and cut leaves.
BabyNet: A Lightweight Network for Infant Reaching Action Recognition in Unconstrained Environments to Support Future Pediatric Rehabilitation Applications
Aug 09, 2022
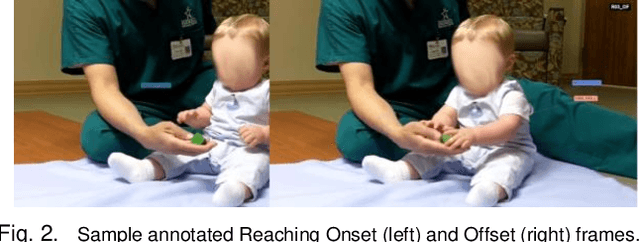
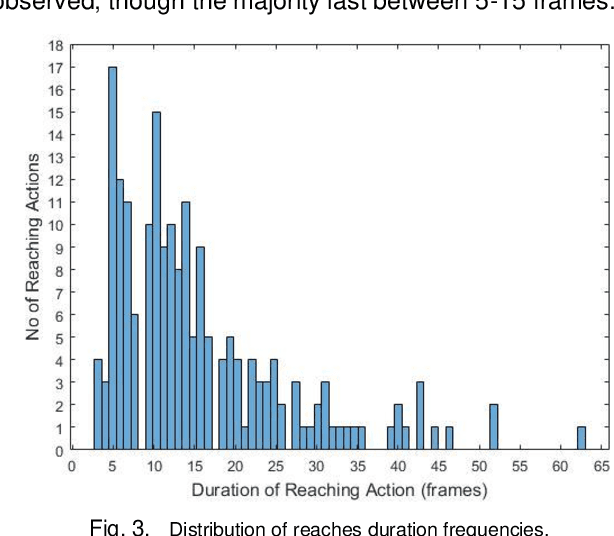
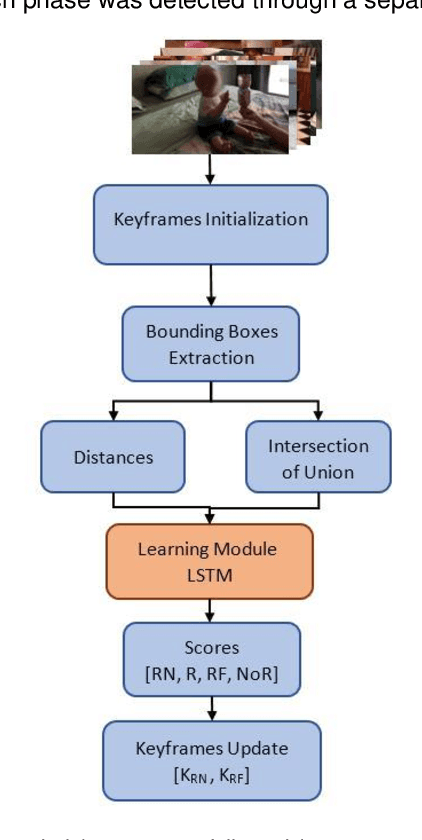
Action recognition is an important component to improve autonomy of physical rehabilitation devices, such as wearable robotic exoskeletons. Existing human action recognition algorithms focus on adult applications rather than pediatric ones. In this paper, we introduce BabyNet, a light-weight (in terms of trainable parameters) network structure to recognize infant reaching action from off-body stationary cameras. We develop an annotated dataset that includes diverse reaches performed while in a sitting posture by different infants in unconstrained environments (e.g., in home settings, etc.). Our approach uses the spatial and temporal connection of annotated bounding boxes to interpret onset and offset of reaching, and to detect a complete reaching action. We evaluate the efficiency of our proposed approach and compare its performance against other learning-based network structures in terms of capability of capturing temporal inter-dependencies and accuracy of detection of reaching onset and offset. Results indicate our BabyNet can attain solid performance in terms of (average) testing accuracy that exceeds that of other larger networks, and can hence serve as a light-weight data-driven framework for video-based infant reaching action recognition.