 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning for Scalable Downlink Power Control in Cell-Free Massive MIMO
May 25, 2026In cell-free massive multiple-input multiple-output systems, downlink power control is essential to ensure uniformly high service quality across users. Existing methods range from centralized iterative approaches requiring global channel knowledge and supervised training, to simpler distributed strategies such as fractional power control that rely on local information but perform poorly in terms of fairness. This letter proposes an unsupervised, physics-informed framework that directly optimizes max-min fairness without requiring optimal labels or user position information. The method is inherently scalable in the number of user equipment, does not require retraining when the user population changes, and can be extended to achieve full scalability with respect to both access points and users. Numerical results show that it nearly doubles the worst-user spectral efficiency compared to existing scalable schemes.
A General Framework for Scalable UE-AP Association in User-Centric Cell-Free Massive MIMO based on Recurrent Neural Networks
Mar 06, 2025This study addresses the challenge of access point (AP) and user equipment (UE) association in cell-free massive MIMO networks. It introduces a deep learning algorithm leveraging Bidirectional Long Short-Term Memory cells and a hybrid probabilistic methodology for weight updating. This approach enhances scalability by adapting to variations in the number of UEs without requiring retraining. Additionally, the study presents a training methodology that improves scalability not only with respect to the number of UEs but also to the number of APs. Furthermore, a variant of the proposed AP-UE algorithm ensures robustness against pilot contamination effects, a critical issue arising from pilot reuse in channel estimation. Extensive numerical results validate the effectiveness and adaptability of the proposed methods, demonstrating their superiority over widely used heuristic alternatives.
A Unified View of Algorithms for Path Planning Using Probabilistic Inference on Factor Graphs
Jun 19, 2021



Even if path planning can be solved using standard techniques from dynamic programming and control, the problem can also be approached using probabilistic inference. The algorithms that emerge using the latter framework bear some appealing characteristics that qualify the probabilistic approach as a powerful alternative to the more traditional control formulations. The idea of using estimation on stochastic models to solve control problems is not new and the inference approach considered here falls under the rubric of Active Inference (AI) and Control as Inference (CAI). In this work, we look at the specific recursions that arise from various cost functions that, although they may appear similar in scope, bear noticeable differences, at least when applied to typical path planning problems. We start by posing the path planning problem on a probabilistic factor graph, and show how the various algorithms translate into specific message composition rules. We then show how this unified approach, presented both in probability space and in log space, provides a very general framework that includes the Sum-product, the Max-product, Dynamic programming and mixed Reward/Entropy criteria-based algorithms. The framework also expands algorithmic design options for smoother or sharper policy distributions, including generalized Sum/Max-product algorithm, a Smooth Dynamic programming algorithm and modified versions of the Reward/Entropy recursions. We provide a comprehensive table of recursions and a comparison through simulations, first on a synthetic small grid with a single goal with obstacles, and then on a grid extrapolated from a real-world scene with multiple goals and a semantic map.
Path Planning Using Probability Tensor Flows
Mar 05, 2020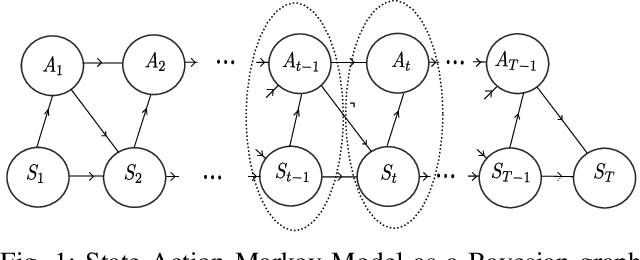

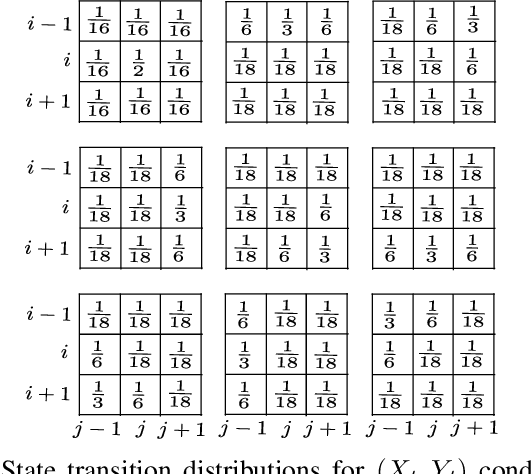
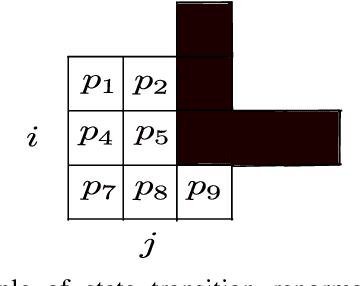
Probability models have been proposed in the literature to account for "intelligent" behavior in many contexts. In this paper, probability propagation is applied to model agent's motion in potentially complex scenarios that include goals and obstacles. The backward flow provides precious background information to the agent's behavior, viz., inferences coming from the future determine the agent's actions. Probability tensors are layered in time in both directions in a manner similar to convolutional neural networks. The discussion is carried out with reference to a set of simulated grids where, despite the apparent task complexity, a solution, if feasible, is always found. The original model proposed by Attias has been extended to include non-absorbing obstacles, multiple goals and multiple agents. The emerging behaviors are very realistic and demonstrate great potentials of the application of this framework to real environments.
An Analysis of Word2Vec for the Italian Language
Jan 25, 2020

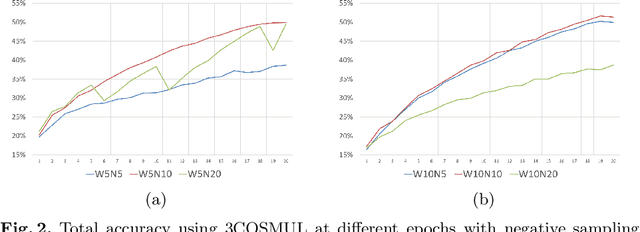

Word representation is fundamental in NLP tasks, because it is precisely from the coding of semantic closeness between words that it is possible to think of teaching a machine to understand text. Despite the spread of word embedding concepts, still few are the achievements in linguistic contexts other than English. In this work, analysing the semantic capacity of the Word2Vec algorithm, an embedding for the Italian language is produced. Parameter setting such as the number of epochs, the size of the context window and the number of negatively backpropagated samples is explored.
Intent Classification in Question-Answering Using LSTM Architectures
Jan 25, 2020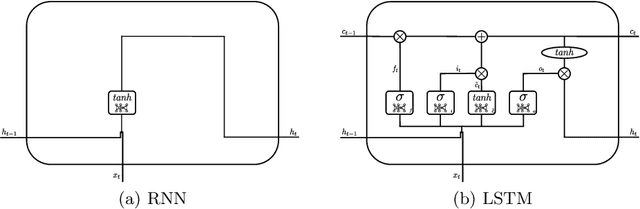



Question-answering (QA) is certainly the best known and probably also one of the most complex problem within Natural Language Processing (NLP) and artificial intelligence (AI). Since the complete solution to the problem of finding a generic answer still seems far away, the wisest thing to do is to break down the problem by solving single simpler parts. Assuming a modular approach to the problem, we confine our research to intent classification for an answer, given a question. Through the use of an LSTM network, we show how this type of classification can be approached effectively and efficiently, and how it can be properly used within a basic prototype responder.
Optimized Realization of Bayesian Networks in Reduced Normal Form using Latent Variable Model
Jan 18, 2019



Bayesian networks in their Factor Graph Reduced Normal Form (FGrn) are a powerful paradigm for implementing inference graphs. Unfortunately, the computational and memory costs of these networks may be considerable, even for relatively small networks, and this is one of the main reasons why these structures have often been underused in practice. In this work, through a detailed algorithmic and structural analysis, various solutions for cost reduction are proposed. An online version of the classic batch learning algorithm is also analyzed, showing very similar results (in an unsupervised context); which is essential even if multilevel structures are to be built. The solutions proposed, together with the possible online learning algorithm, are included in a C++ library that is quite efficient, especially if compared to the direct use of the well-known sum-product and Maximum Likelihood (ML) algorithms. The results are discussed with particular reference to a Latent Variable Model (LVM) structure.
Discrete Independent Component Analysis (DICA) with Belief Propagation
May 26, 2015
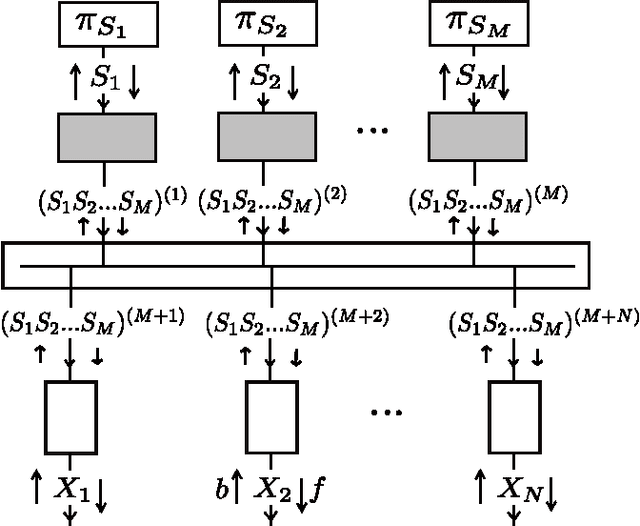


We apply belief propagation to a Bayesian bipartite graph composed of discrete independent hidden variables and discrete visible variables. The network is the Discrete counterpart of Independent Component Analysis (DICA) and it is manipulated in a factor graph form for inference and learning. A full set of simulations is reported for character images from the MNIST dataset. The results show that the factorial code implemented by the sources contributes to build a good generative model for the data that can be used in various inference modes.
Towards Building Deep Networks with Bayesian Factor Graphs
Feb 16, 2015

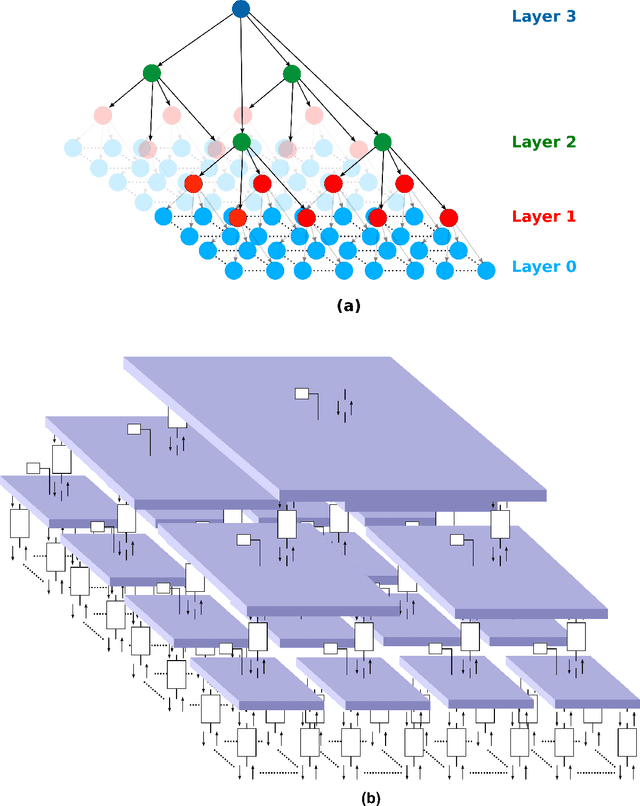

We propose a Multi-Layer Network based on the Bayesian framework of the Factor Graphs in Reduced Normal Form (FGrn) applied to a two-dimensional lattice. The Latent Variable Model (LVM) is the basic building block of a quadtree hierarchy built on top of a bottom layer of random variables that represent pixels of an image, a feature map, or more generally a collection of spatially distributed discrete variables. The multi-layer architecture implements a hierarchical data representation that, via belief propagation, can be used for learning and inference. Typical uses are pattern completion, correction and classification. The FGrn paradigm provides great flexibility and modularity and appears as a promising candidate for building deep networks: the system can be easily extended by introducing new and different (in cardinality and in type) variables. Prior knowledge, or supervised information, can be introduced at different scales. The FGrn paradigm provides a handy way for building all kinds of architectures by interconnecting only three types of units: Single Input Single Output (SISO) blocks, Sources and Replicators. The network is designed like a circuit diagram and the belief messages flow bidirectionally in the whole system. The learning algorithms operate only locally within each block. The framework is demonstrated in this paper in a three-layer structure applied to images extracted from a standard data set.