Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Word2Vec for the Italian Language
Paper and Code
Jan 25, 2020

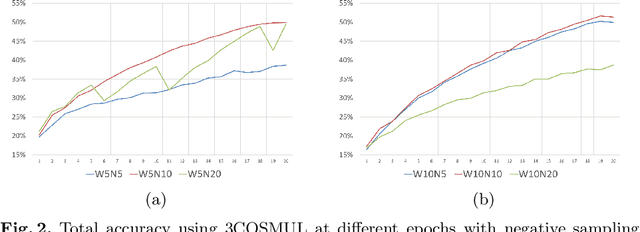

Word representation is fundamental in NLP tasks, because it is precisely from the coding of semantic closeness between words that it is possible to think of teaching a machine to understand text. Despite the spread of word embedding concepts, still few are the achievements in linguistic contexts other than English. In this work, analysing the semantic capacity of the Word2Vec algorithm, an embedding for the Italian language is produced. Parameter setting such as the number of epochs, the size of the context window and the number of negatively backpropagated samples is explored.
* Presented at the 2019 Italian Workshop on Neural Networks (WIRN'19) -
June 2019
View paper on