 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Word2Vec for the Italian Language
Jan 25, 2020

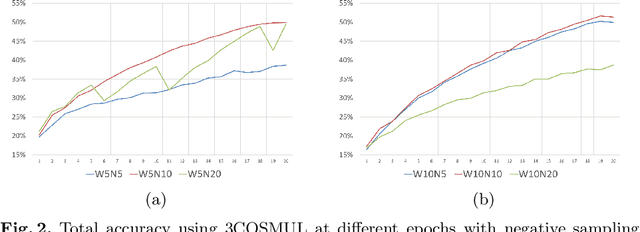

Word representation is fundamental in NLP tasks, because it is precisely from the coding of semantic closeness between words that it is possible to think of teaching a machine to understand text. Despite the spread of word embedding concepts, still few are the achievements in linguistic contexts other than English. In this work, analysing the semantic capacity of the Word2Vec algorithm, an embedding for the Italian language is produced. Parameter setting such as the number of epochs, the size of the context window and the number of negatively backpropagated samples is explored.
Intent Classification in Question-Answering Using LSTM Architectures
Jan 25, 2020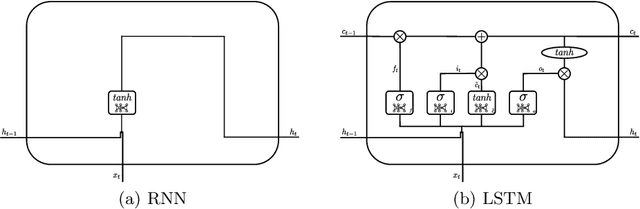



Question-answering (QA) is certainly the best known and probably also one of the most complex problem within Natural Language Processing (NLP) and artificial intelligence (AI). Since the complete solution to the problem of finding a generic answer still seems far away, the wisest thing to do is to break down the problem by solving single simpler parts. Assuming a modular approach to the problem, we confine our research to intent classification for an answer, given a question. Through the use of an LSTM network, we show how this type of classification can be approached effectively and efficiently, and how it can be properly used within a basic prototype responder.