 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness and Reliability of Gender Bias Assessment in Word Embeddings: The Role of Base Pairs
Oct 27, 2020

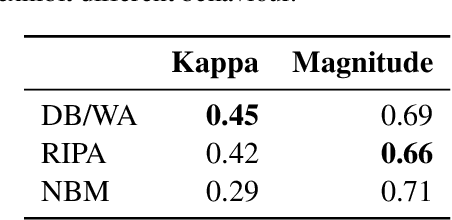
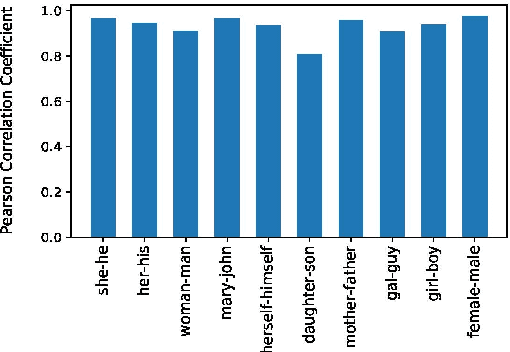
It has been shown that word embeddings can exhibit gender bias, and various methods have been proposed to quantify this. However, the extent to which the methods are capturing social stereotypes inherited from the data has been debated. Bias is a complex concept and there exist multiple ways to define it. Previous work has leveraged gender word pairs to measure bias and extract biased analogies. We show that the reliance on these gendered pairs has strong limitations: bias measures based off of them are not robust and cannot identify common types of real-world bias, whilst analogies utilising them are unsuitable indicators of bias. In particular, the well-known analogy "man is to computer-programmer as woman is to homemaker" is due to word similarity rather than societal bias. This has important implications for work on measuring bias in embeddings and related work debiasing embeddings.
Strong Baselines for Complex Word Identification across Multiple Languages
Apr 11, 2019
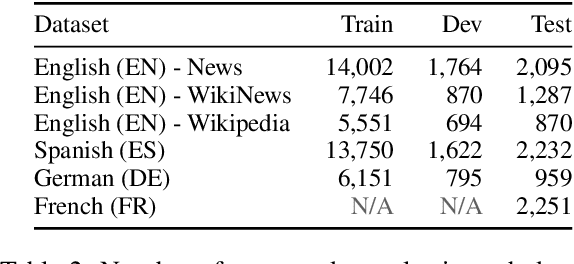
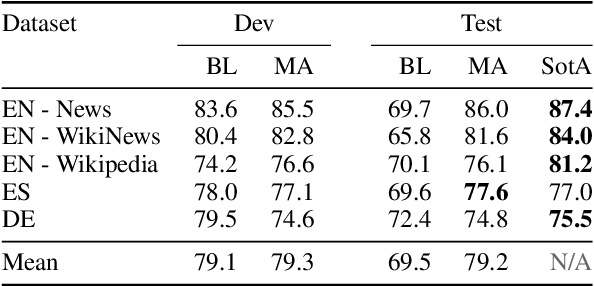

Complex Word Identification (CWI) is the task of identifying which words or phrases in a sentence are difficult to understand by a target audience. The latest CWI Shared Task released data for two settings: monolingual (i.e. train and test in the same language) and cross-lingual (i.e. test in a language not seen during training). The best monolingual models relied on language-dependent features, which do not generalise in the cross-lingual setting, while the best cross-lingual model used neural networks with multi-task learning. In this paper, we present monolingual and cross-lingual CWI models that perform as well as (or better than) most models submitted to the latest CWI Shared Task. We show that carefully selected features and simple learning models can achieve state-of-the-art performance, and result in strong baselines for future development in this area. Finally, we discuss how inconsistencies in the annotation of the data can explain some of the results obtained.