 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform and Entropy Coding in AV2
Jan 06, 2026AV2 is the successor to the AV1 royalty-free video coding standard developed by the Alliance for Open Media (AOMedia). Its primary objective is to deliver substantial compression gains and subjective quality improvements while maintaining low-complexity encoder and decoder operations. This paper describes the transform, quantization and entropy coding design in AV2, including redesigned transform kernels and data-driven transforms, expanded transform partitioning, and a mode & coefficient dependent transform signaling. AV2 introduces several new coding tools including Intra/Inter Secondary Transforms (IST), Trellis Coded Quantization (TCQ), Adaptive Transform Coding (ATC), Probability Adaptation Rate Adjustment (PARA), Forward Skip Coding (FSC), Cross Chroma Component Transforms (CCTX), Parity Hiding (PH) tools and improved lossless coding. These advances enable AV2 to deliver the highest quality video experience for video applications at a significantly reduced bitrate.
Rectified Gaussian Scale Mixtures and the Sparse Non-Negative Least Squares Problem
Mar 27, 2018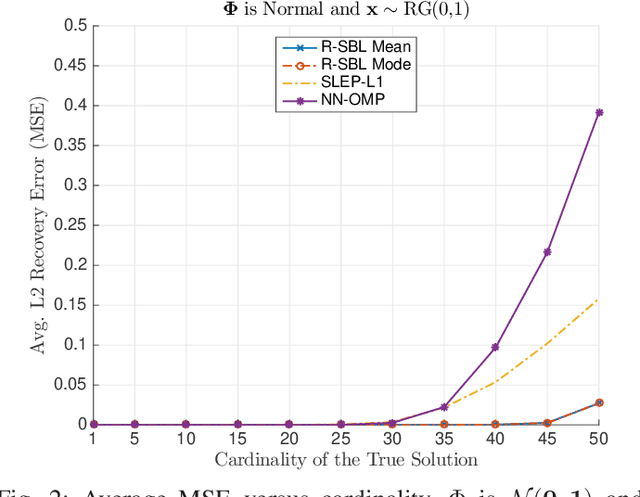
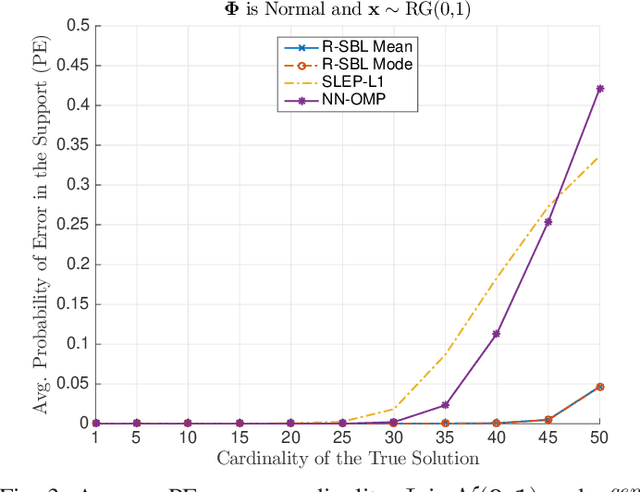
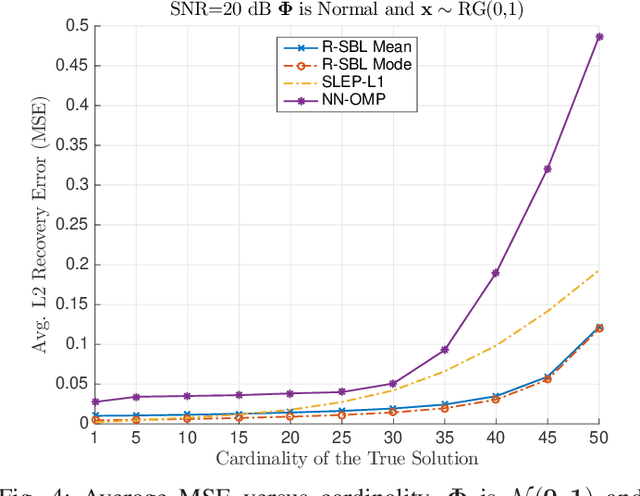
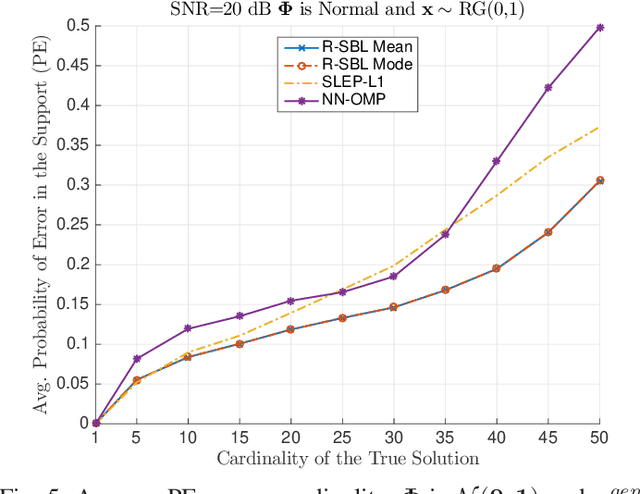
In this paper, we develop a Bayesian evidence maximization framework to solve the sparse non-negative least squares (S-NNLS) problem. We introduce a family of probability densities referred to as the Rectified Gaussian Scale Mixture (R- GSM) to model the sparsity enforcing prior distribution for the solution. The R-GSM prior encompasses a variety of heavy-tailed densities such as the rectified Laplacian and rectified Student- t distributions with a proper choice of the mixing density. We utilize the hierarchical representation induced by the R-GSM prior and develop an evidence maximization framework based on the Expectation-Maximization (EM) algorithm. Using the EM based method, we estimate the hyper-parameters and obtain a point estimate for the solution. We refer to the proposed method as rectified sparse Bayesian learning (R-SBL). We provide four R- SBL variants that offer a range of options for computational complexity and the quality of the E-step computation. These methods include the Markov chain Monte Carlo EM, linear minimum mean-square-error estimation, approximate message passing and a diagonal approximation. Using numerical experiments, we show that the proposed R-SBL method outperforms existing S-NNLS solvers in terms of both signal and support recovery performance, and is also very robust against the structure of the design matrix.
A Unified Framework for Sparse Non-Negative Least Squares using Multiplicative Updates and the Non-Negative Matrix Factorization Problem
Jan 02, 2018
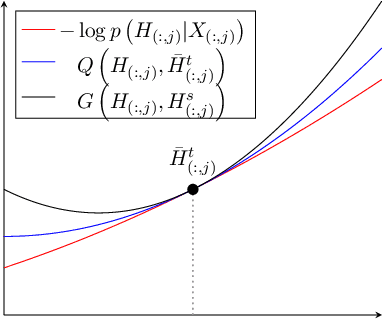
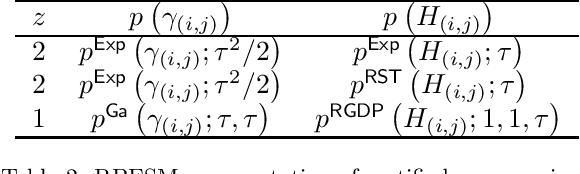
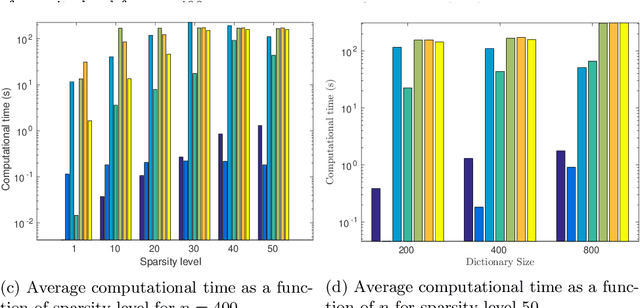
We study the sparse non-negative least squares (S-NNLS) problem. S-NNLS occurs naturally in a wide variety of applications where an unknown, non-negative quantity must be recovered from linear measurements. We present a unified framework for S-NNLS based on a rectified power exponential scale mixture prior on the sparse codes. We show that the proposed framework encompasses a large class of S-NNLS algorithms and provide a computationally efficient inference procedure based on multiplicative update rules. Such update rules are convenient for solving large sets of S-NNLS problems simultaneously, which is required in contexts like sparse non-negative matrix factorization (S-NMF). We provide theoretical justification for the proposed approach by showing that the local minima of the objective function being optimized are sparse and the S-NNLS algorithms presented are guaranteed to converge to a set of stationary points of the objective function. We then extend our framework to S-NMF, showing that our framework leads to many well known S-NMF algorithms under specific choices of prior and providing a guarantee that a popular subclass of the proposed algorithms converges to a set of stationary points of the objective function. Finally, we study the performance of the proposed approaches on synthetic and real-world data.