 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation Through Monte Carlo Arithmetic Leads to More Generalizable Classification in Connectomics
Sep 20, 2021Machine learning models are commonly applied to human brain imaging datasets in an effort to associate function or structure with behaviour, health, or other individual phenotypes. Such models often rely on low-dimensional maps generated by complex processing pipelines. However, the numerical instabilities inherent to pipelines limit the fidelity of these maps and introduce computational bias. Monte Carlo Arithmetic, a technique for introducing controlled amounts of numerical noise, was used to perturb a structural connectome estimation pipeline, ultimately producing a range of plausible networks for each sample. The variability in the perturbed networks was captured in an augmented dataset, which was then used for an age classification task. We found that resampling brain networks across a series of such numerically perturbed outcomes led to improved performance in all tested classifiers, preprocessing strategies, and dimensionality reduction techniques. Importantly, we find that this benefit does not hinge on a large number of perturbations, suggesting that even minimally perturbing a dataset adds meaningful variance which can be captured in the subsequently designed models.
Accurate simulation of operating system updates in neuroimaging using Monte-Carlo arithmetic
Aug 06, 2021
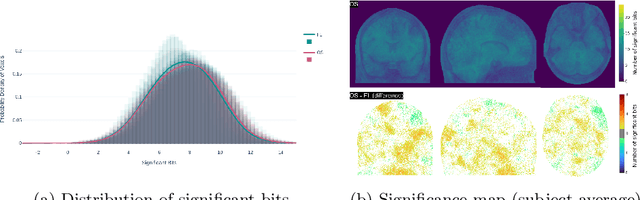
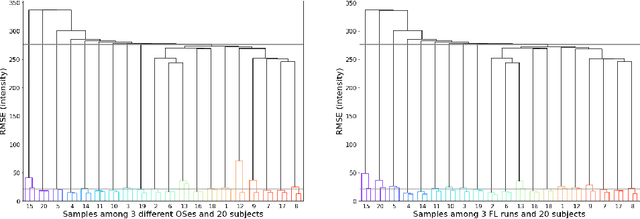
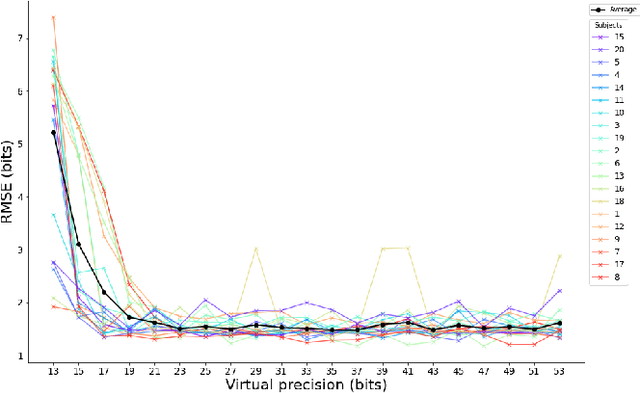
Operating system (OS) updates introduce numerical perturbations that impact the reproducibility of computational pipelines. In neuroimaging, this has important practical implications on the validity of computational results, particularly when obtained in systems such as high-performance computing clusters where the experimenter does not control software updates. We present a framework to reproduce the variability induced by OS updates in controlled conditions. We hypothesize that OS updates impact computational pipelines mainly through numerical perturbations originating in mathematical libraries, which we simulate using Monte-Carlo arithmetic in a framework called "fuzzy libmath" (FL). We applied this methodology to pre-processing pipelines of the Human Connectome Project, a flagship open-data project in neuroimaging. We found that FL-perturbed pipelines accurately reproduce the variability induced by OS updates and that this similarity is only mildly dependent on simulation parameters. Importantly, we also found between-subject differences were preserved in both cases, though the between-run variability was of comparable magnitude for both FL and OS perturbations. We found the numerical precision in the HCP pre-processed images to be relatively low, with less than 8 significant bits among the 24 available, which motivates further investigation of the numerical stability of components in the tested pipeline. Overall, our results establish that FL accurately simulates results variability due to OS updates, and is a practical framework to quantify numerical uncertainty in neuroimaging.
Predicting computational reproducibility of data analysis pipelines in large population studies using collaborative filtering
Sep 26, 2018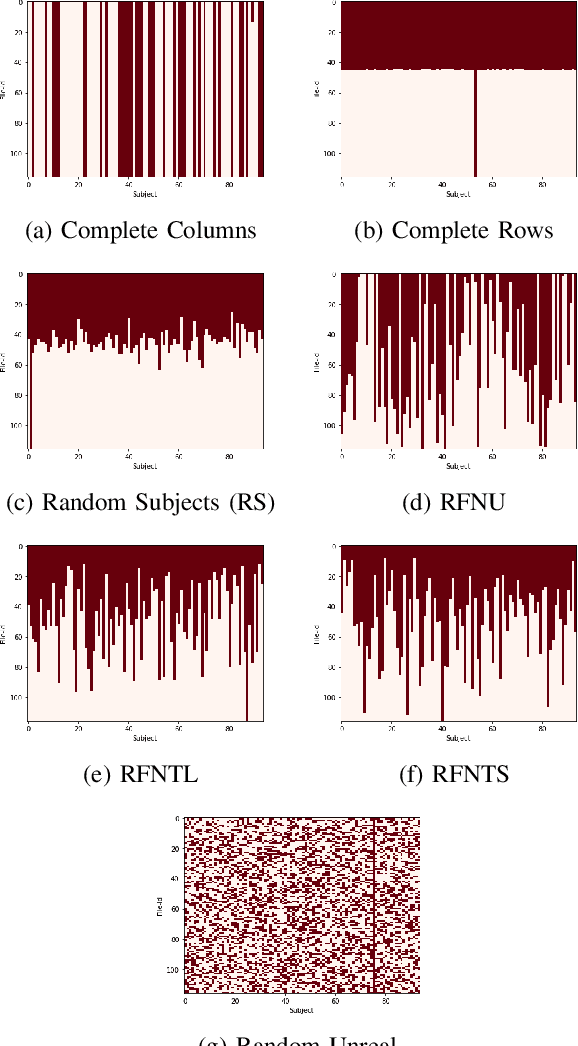
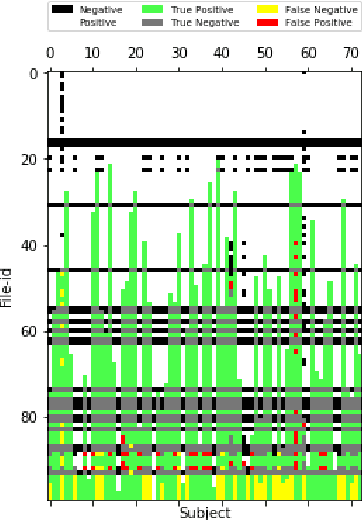
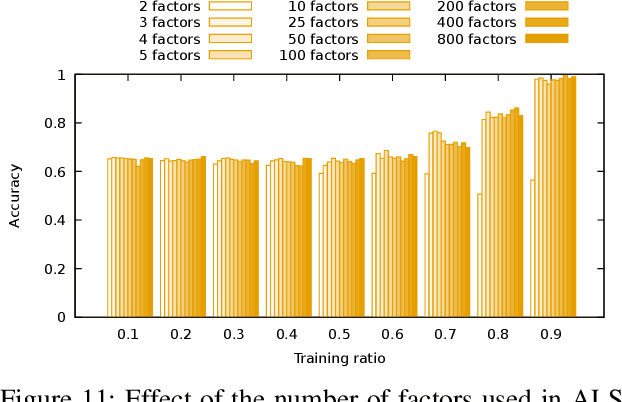
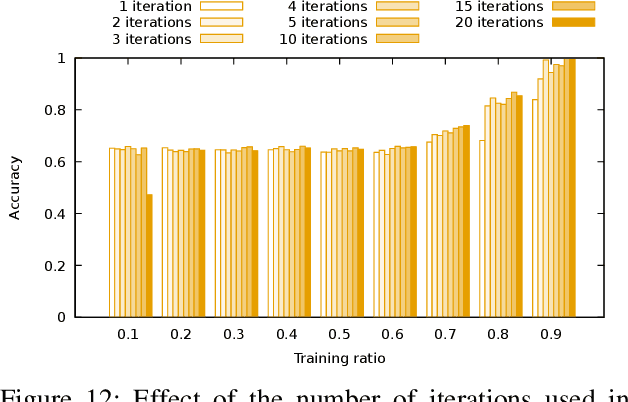
Evaluating the computational reproducibility of data analysis pipelines has become a critical issue. It is, however, a cumbersome process for analyses that involve data from large populations of subjects, due to their computational and storage requirements. We present a method to predict the computational reproducibility of data analysis pipelines in large population studies. We formulate the problem as a collaborative filtering process, with constraints on the construction of the training set. We propose 6 different strategies to build the training set, which we evaluate on 2 datasets, a synthetic one modeling a population with a growing number of subject types, and a real one obtained with neuroinformatics pipelines. Results show that one sampling method, "Random File Numbers (Uniform)" is able to predict computational reproducibility with a good accuracy. We also analyze the relevance of including file and subject biases in the collaborative filtering model. We conclude that the proposed method is able to speedup reproducibility evaluations substantially, with a reduced accuracy loss.