 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Tracking with Dynamic Control Point Blending for Autonomous Vehicles: An Experimental Study
Feb 02, 2026This paper presents an experimental study of a path-tracking framework for autonomous vehicles in which the lateral control command is applied to a dynamic control point along the wheelbase. Instead of enforcing a fixed reference at either the front or rear axle, the proposed method continuously interpolates between both, enabling smooth adaptation across driving contexts, including low-speed maneuvers and reverse motion. The lateral steering command is obtained by barycentric blending of two complementary controllers: a front-axle Stanley formulation and a rear-axle curvature-based geometric controller, yielding continuous transitions in steering behavior and improved tracking stability. In addition, we introduce a curvature-aware longitudinal control strategy based on virtual track borders and ray-tracing, which converts upcoming geometric constraints into a virtual obstacle distance and regulates speed accordingly. The complete approach is implemented in a unified control stack and validated in simulation and on a real autonomous vehicle equipped with GPS-RTK, radar, odometry, and IMU. The results in closed-loop tracking and backward maneuvers show improved trajectory accuracy, smoother steering profiles, and increased adaptability compared to fixed control-point baselines.
Online Context Learning for Socially-compliant Navigation
Jun 17, 2024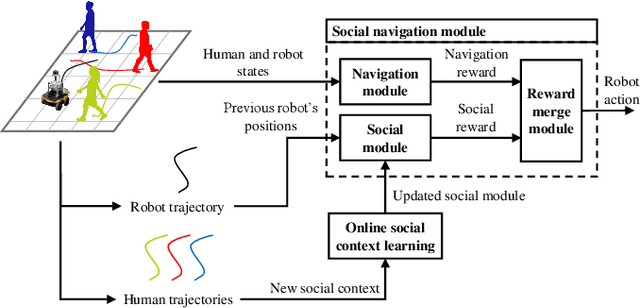
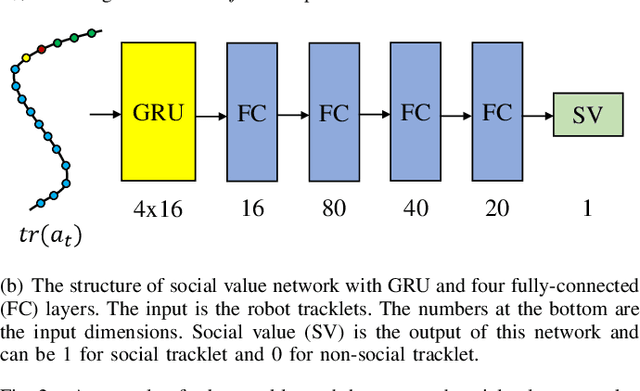
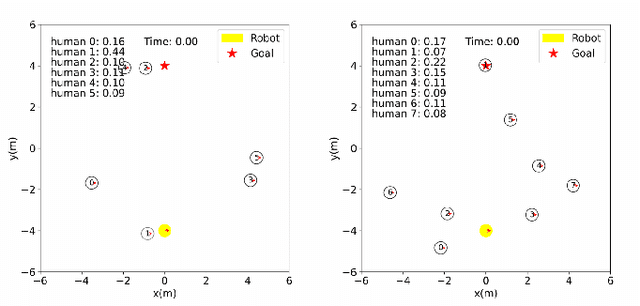
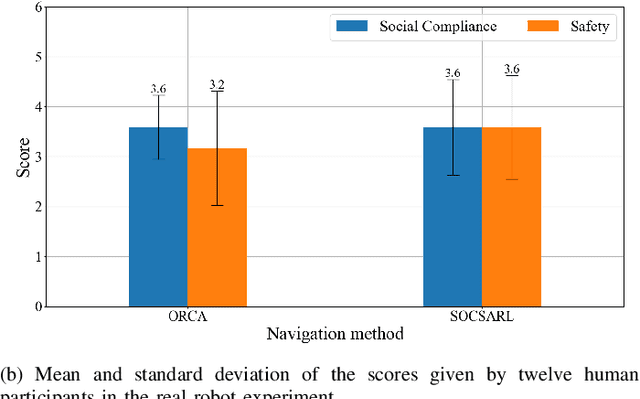
Robot social navigation needs to adapt to different human factors and environmental contexts. However, since these factors and contexts are difficult to predict and cannot be exhaustively enumerated, traditional learning-based methods have difficulty in ensuring the social attributes of robots in long-term and cross-environment deployments. This letter introduces an online context learning method that aims to empower robots to adapt to new social environments online. The proposed method adopts a two-layer structure. The bottom layer is built using a deep reinforcement learning-based method to ensure the output of basic robot navigation commands. The upper layer is implemented using an online robot learning-based method to socialize the control commands suggested by the bottom layer. Experiments using a community-wide simulator show that our method outperforms the state-of-the-art ones. Experimental results in the most challenging scenarios show that our method improves the performance of the state-of-the-art by 8%. The source code of the proposed method, the data used, and the tools for the per-training step will be publicly available at https://github.com/Nedzhaken/SOCSARL-OL.