 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Motion Transfer with Diffusion Transformers
Dec 10, 2024
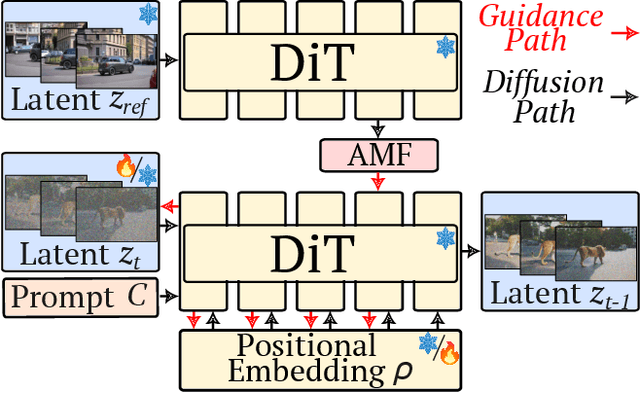


We propose DiTFlow, a method for transferring the motion of a reference video to a newly synthesized one, designed specifically for Diffusion Transformers (DiT). We first process the reference video with a pre-trained DiT to analyze cross-frame attention maps and extract a patch-wise motion signal called the Attention Motion Flow (AMF). We guide the latent denoising process in an optimization-based, training-free, manner by optimizing latents with our AMF loss to generate videos reproducing the motion of the reference one. We also apply our optimization strategy to transformer positional embeddings, granting us a boost in zero-shot motion transfer capabilities. We evaluate DiTFlow against recently published methods, outperforming all across multiple metrics and human evaluation.
MatchDiffusion: Training-free Generation of Match-cuts
Nov 27, 2024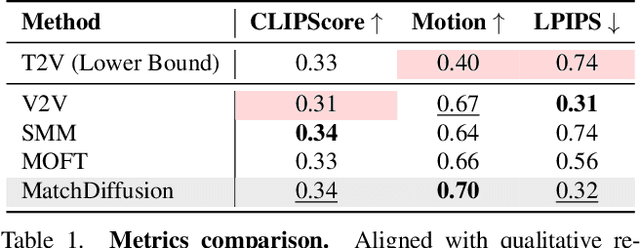

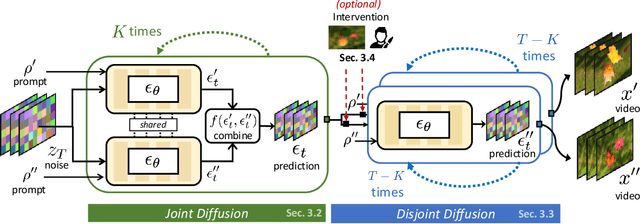
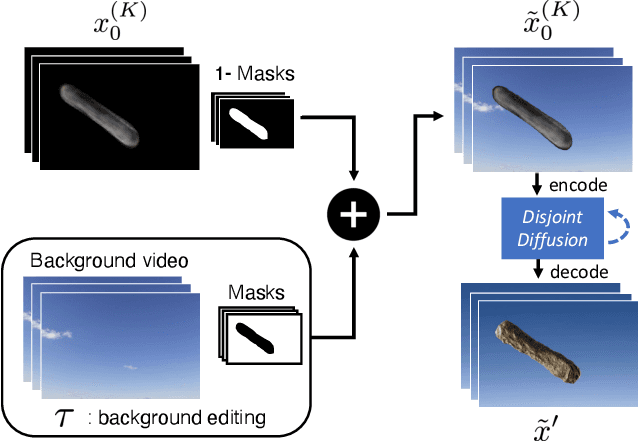
Match-cuts are powerful cinematic tools that create seamless transitions between scenes, delivering strong visual and metaphorical connections. However, crafting match-cuts is a challenging, resource-intensive process requiring deliberate artistic planning. In MatchDiffusion, we present the first training-free method for match-cut generation using text-to-video diffusion models. MatchDiffusion leverages a key property of diffusion models: early denoising steps define the scene's broad structure, while later steps add details. Guided by this insight, MatchDiffusion employs "Joint Diffusion" to initialize generation for two prompts from shared noise, aligning structure and motion. It then applies "Disjoint Diffusion", allowing the videos to diverge and introduce unique details. This approach produces visually coherent videos suited for match-cuts. User studies and metrics demonstrate MatchDiffusion's effectiveness and potential to democratize match-cut creation.
Convolutional Neural Processes for Inpainting Satellite Images
May 24, 2022

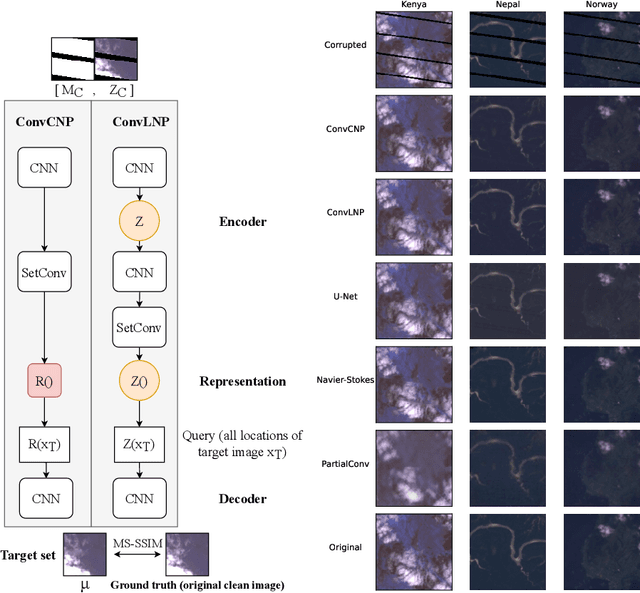

The widespread availability of satellite images has allowed researchers to model complex systems such as disease dynamics. However, many satellite images have missing values due to measurement defects, which render them unusable without data imputation. For example, the scanline corrector for the LANDSAT 7 satellite broke down in 2003, resulting in a loss of around 20\% of its data. Inpainting involves predicting what is missing based on the known pixels and is an old problem in image processing, classically based on PDEs or interpolation methods, but recent deep learning approaches have shown promise. However, many of these methods do not explicitly take into account the inherent spatiotemporal structure of satellite images. In this work, we cast satellite image inpainting as a natural meta-learning problem, and propose using convolutional neural processes (ConvNPs) where we frame each satellite image as its own task or 2D regression problem. We show ConvNPs can outperform classical methods and state-of-the-art deep learning inpainting models on a scanline inpainting problem for LANDSAT 7 satellite images, assessed on a variety of in and out-of-distribution images.