 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPE: Encoding Relative Positions with Continuous Augmented Positional Embeddings
Jun 06, 2021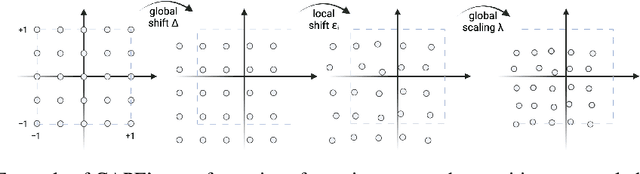
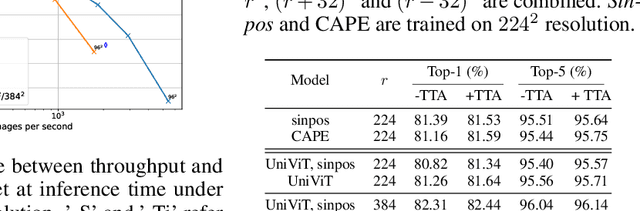
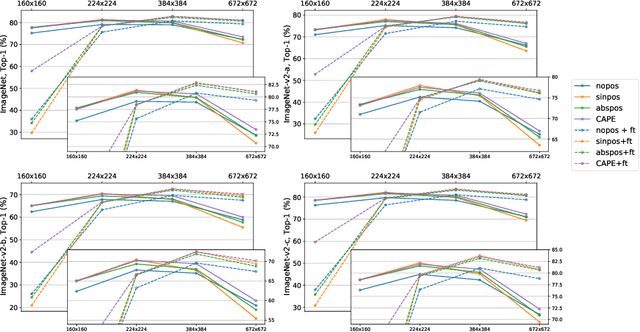
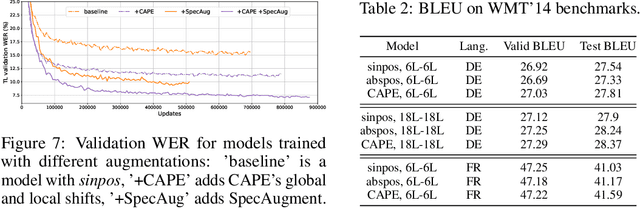
Without positional information, attention-based transformer neural networks are permutation-invariant. Absolute or relative positional embeddings are the most popular ways to feed transformer models positional information. Absolute positional embeddings are simple to implement, but suffer from generalization issues when evaluating on sequences of different length than those seen at training time. Relative positions are more robust to length change, but are more complex to implement and yield inferior model throughput. In this paper, we propose an augmentation-based approach (CAPE) for absolute positional embeddings, which keeps the advantages of both absolute (simplicity and speed) and relative position embeddings (better generalization). In addition, our empirical evaluation on state-of-the-art models in machine translation, image and speech recognition demonstrates that CAPE leads to better generalization performance as well as increased stability with respect to training hyper-parameters.
InfiniteBoost: building infinite ensembles with gradient descent
Sep 21, 2018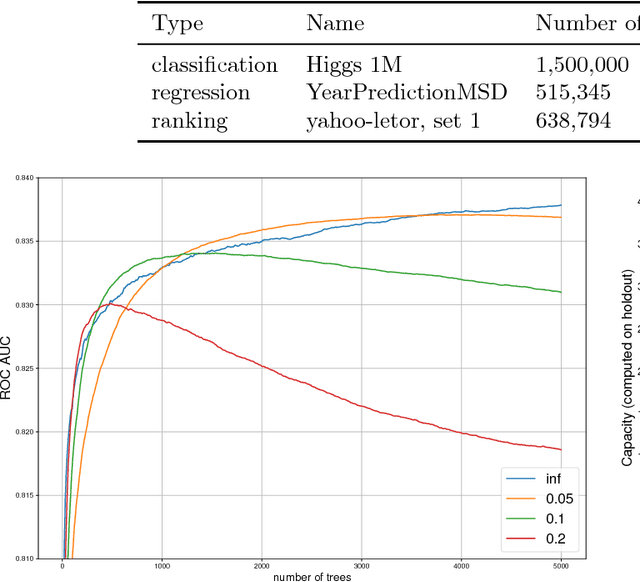
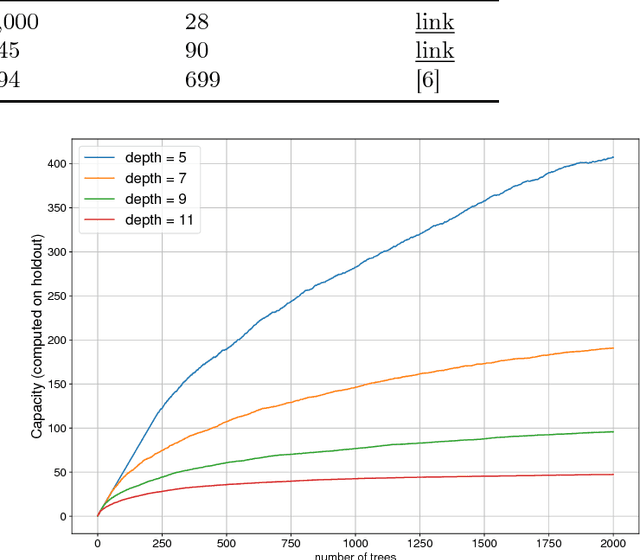
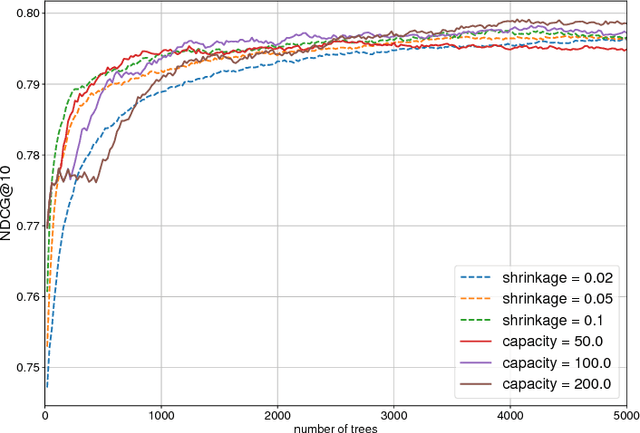

In machine learning ensemble methods have demonstrated high accuracy for the variety of problems in different areas. Two notable ensemble methods widely used in practice are gradient boosting and random forests. In this paper we present InfiniteBoost - a novel algorithm, which combines important properties of these two approaches. The algorithm constructs the ensemble of trees for which two properties hold: trees of the ensemble incorporate the mistakes done by others; at the same time the ensemble could contain the infinite number of trees without the over-fitting effect. The proposed algorithm is evaluated on the regression, classification, and ranking tasks using large scale, publicly available datasets.
Inclusive Flavour Tagging Algorithm
May 24, 2017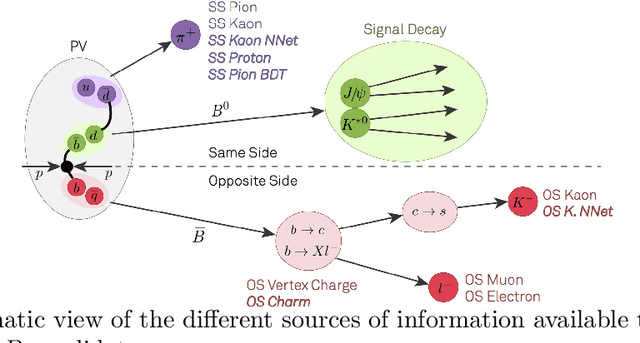
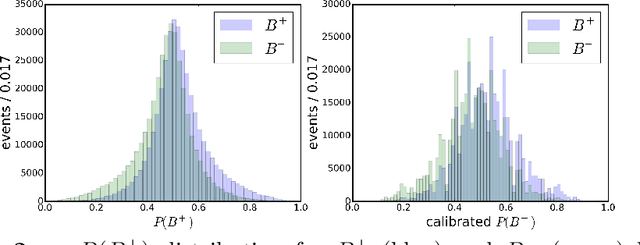
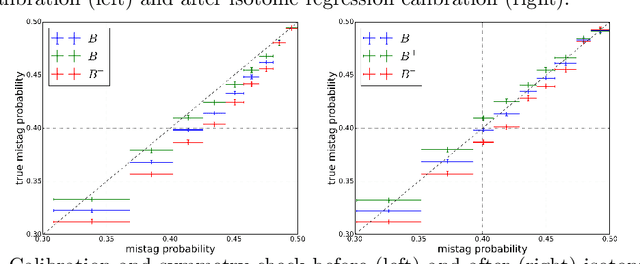

Identifying the flavour of neutral $B$ mesons production is one of the most important components needed in the study of time-dependent $CP$ violation. The harsh environment of the Large Hadron Collider makes it particularly hard to succeed in this task. We present an inclusive flavour-tagging algorithm as an upgrade of the algorithms currently used by the LHCb experiment. Specifically, a probabilistic model which efficiently combines information from reconstructed vertices and tracks using machine learning is proposed. The algorithm does not use information about underlying physics process. It reduces the dependence on the performance of lower level identification capacities and thus increases the overall performance. The proposed inclusive flavour-tagging algorithm is applicable to tag the flavour of $B$ mesons in any proton-proton experiment.
* 5 pages, 5 figures, 17th International workshop on Advanced Computing and Analysis Techniques in physics research (ACAT-2016)