 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Parametric Memory Guidance for Multi-Document Summarization
Nov 14, 2023

Multi-document summarization (MDS) is a difficult task in Natural Language Processing, aiming to summarize information from several documents. However, the source documents are often insufficient to obtain a qualitative summary. We propose a retriever-guided model combined with non-parametric memory for summary generation. This model retrieves relevant candidates from a database and then generates the summary considering the candidates with a copy mechanism and the source documents. The retriever is implemented with Approximate Nearest Neighbor Search (ANN) to search large databases. Our method is evaluated on the MultiXScience dataset which includes scientific articles. Finally, we discuss our results and possible directions for future work.
F-measure Maximization in Multi-Label Classification with Conditionally Independent Label Subsets
Jul 01, 2016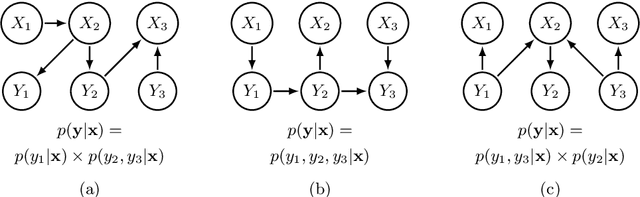
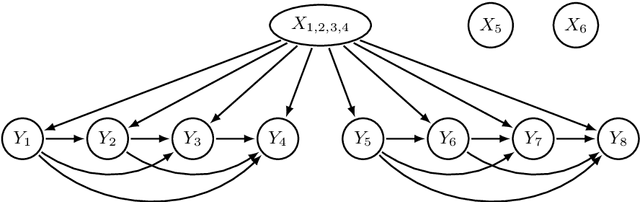
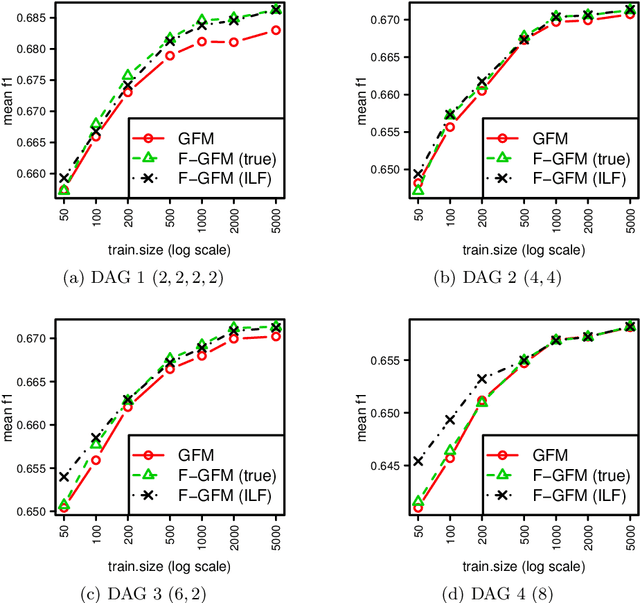
We discuss a method to improve the exact F-measure maximization algorithm called GFM, proposed in (Dembczynski et al. 2011) for multi-label classification, assuming the label set can be can partitioned into conditionally independent subsets given the input features. If the labels were all independent, the estimation of only $m$ parameters ($m$ denoting the number of labels) would suffice to derive Bayes-optimal predictions in $O(m^2)$ operations. In the general case, $m^2+1$ parameters are required by GFM, to solve the problem in $O(m^3)$ operations. In this work, we show that the number of parameters can be reduced further to $m^2/n$, in the best case, assuming the label set can be partitioned into $n$ conditionally independent subsets. As this label partition needs to be estimated from the data beforehand, we use first the procedure proposed in (Gasse et al. 2015) that finds such partition and then infer the required parameters locally in each label subset. The latter are aggregated and serve as input to GFM to form the Bayes-optimal prediction. We show on a synthetic experiment that the reduction in the number of parameters brings about significant benefits in terms of performance.
An Experimental Comparison of Hybrid Algorithms for Bayesian Network Structure Learning
Aug 24, 2015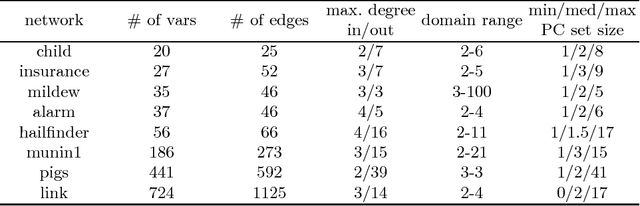
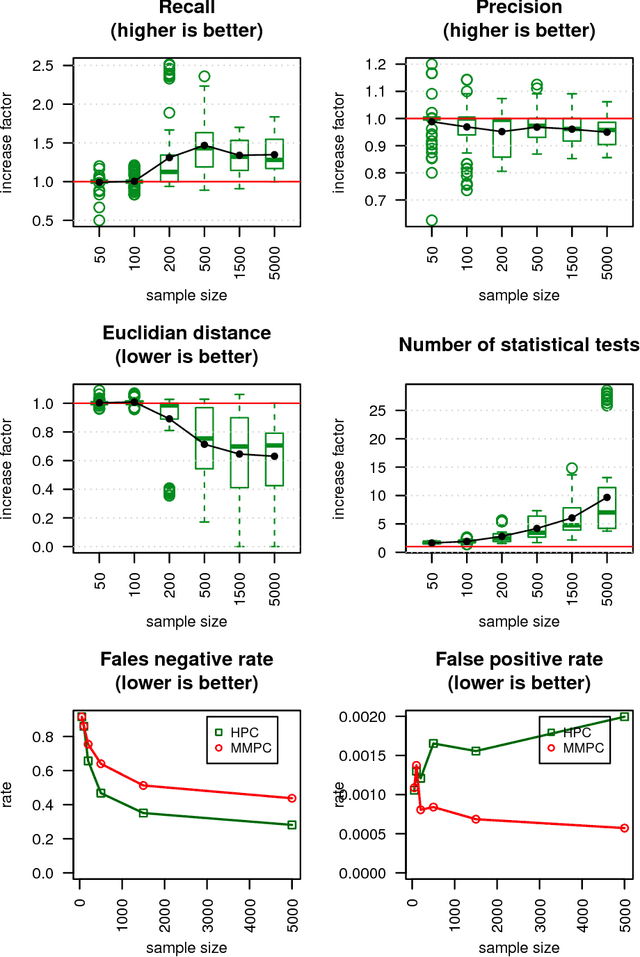
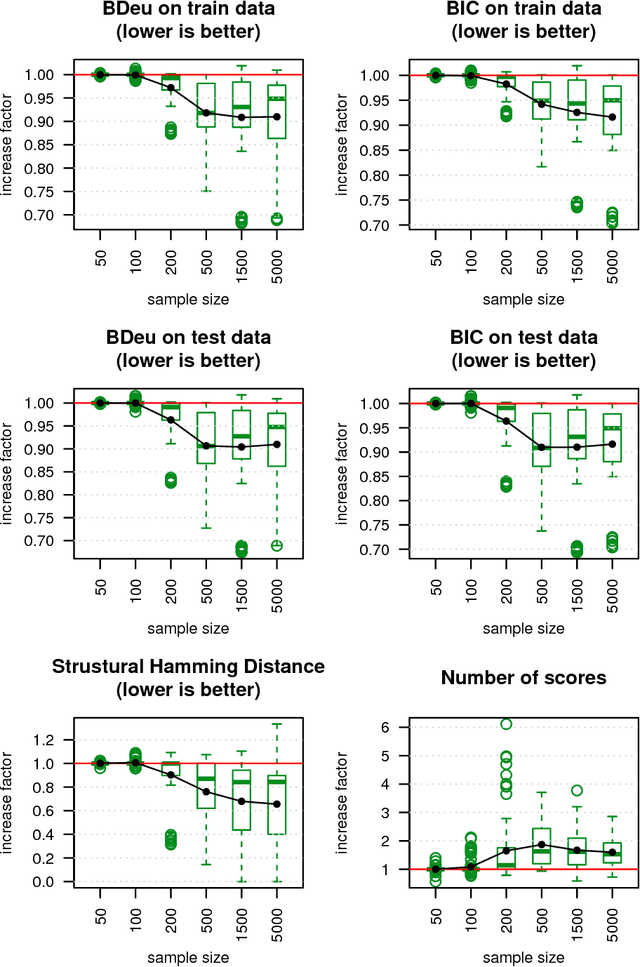
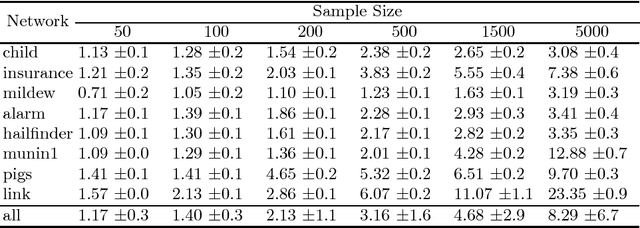
We present a novel hybrid algorithm for Bayesian network structure learning, called Hybrid HPC (H2PC). It first reconstructs the skeleton of a Bayesian network and then performs a Bayesian-scoring greedy hill-climbing search to orient the edges. It is based on a subroutine called HPC, that combines ideas from incremental and divide-and-conquer constraint-based methods to learn the parents and children of a target variable. We conduct an experimental comparison of H2PC against Max-Min Hill-Climbing (MMHC), which is currently the most powerful state-of-the-art algorithm for Bayesian network structure learning, on several benchmarks with various data sizes. Our extensive experiments show that H2PC outperforms MMHC both in terms of goodness of fit to new data and in terms of the quality of the network structure itself, which is closer to the true dependence structure of the data. The source code (in R) of H2PC as well as all data sets used for the empirical tests are publicly available.
A hybrid algorithm for Bayesian network structure learning with application to multi-label learning
Jun 18, 2015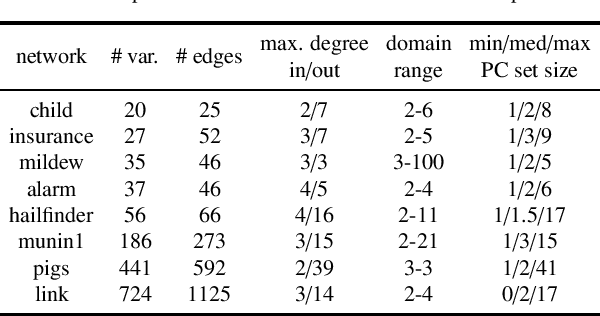
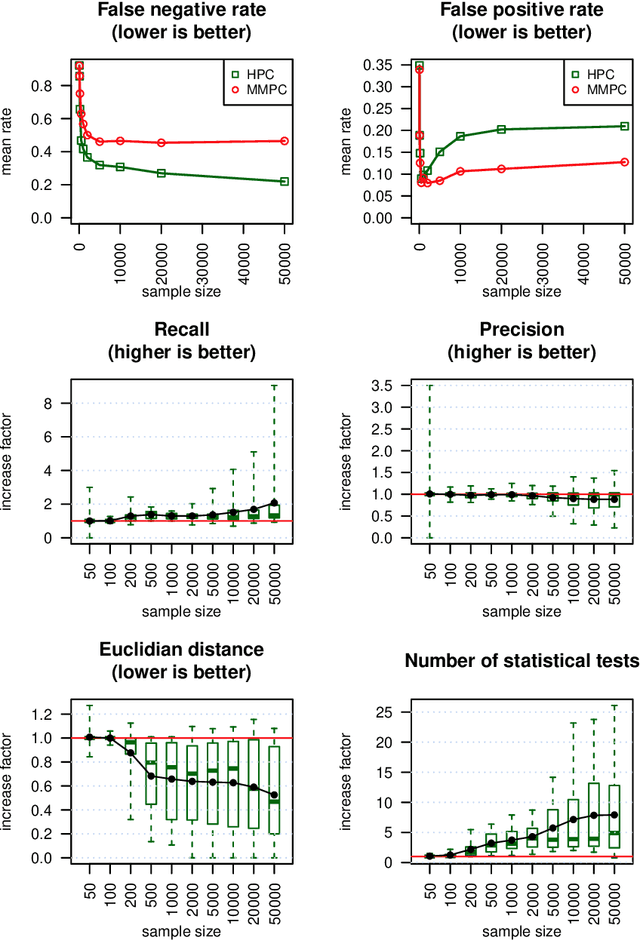
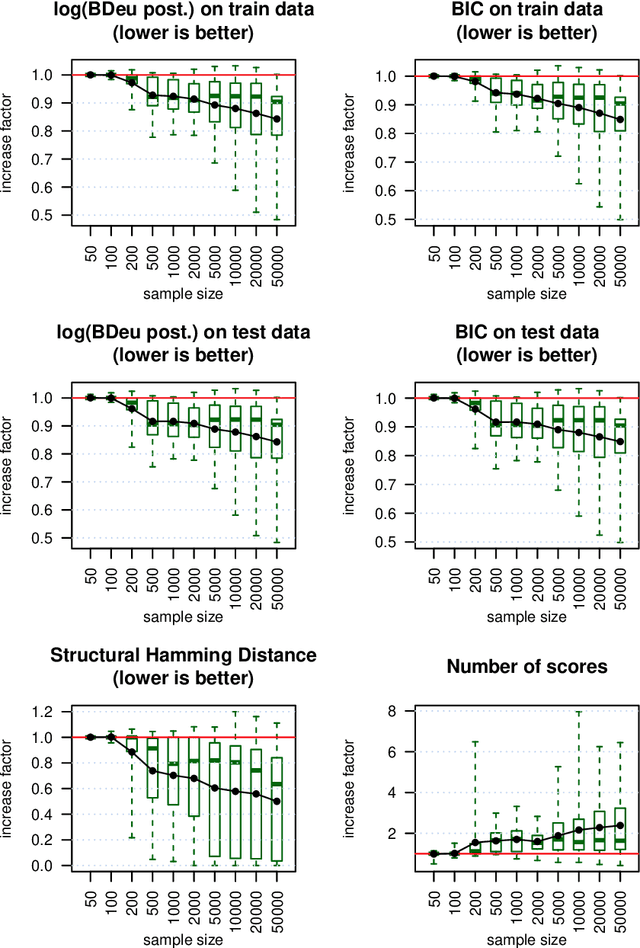
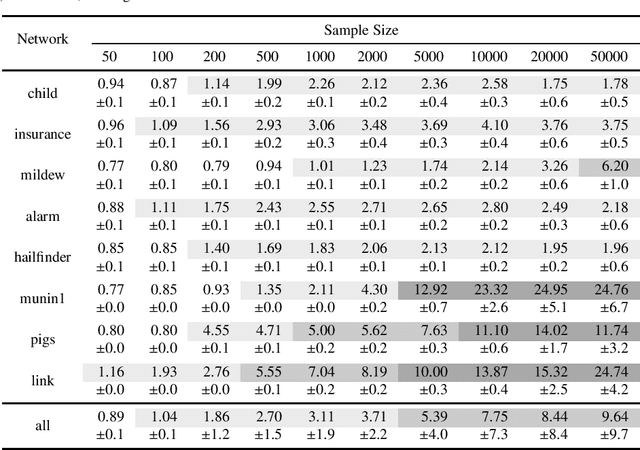
We present a novel hybrid algorithm for Bayesian network structure learning, called H2PC. It first reconstructs the skeleton of a Bayesian network and then performs a Bayesian-scoring greedy hill-climbing search to orient the edges. The algorithm is based on divide-and-conquer constraint-based subroutines to learn the local structure around a target variable. We conduct two series of experimental comparisons of H2PC against Max-Min Hill-Climbing (MMHC), which is currently the most powerful state-of-the-art algorithm for Bayesian network structure learning. First, we use eight well-known Bayesian network benchmarks with various data sizes to assess the quality of the learned structure returned by the algorithms. Our extensive experiments show that H2PC outperforms MMHC in terms of goodness of fit to new data and quality of the network structure with respect to the true dependence structure of the data. Second, we investigate H2PC's ability to solve the multi-label learning problem. We provide theoretical results to characterize and identify graphically the so-called minimal label powersets that appear as irreducible factors in the joint distribution under the faithfulness condition. The multi-label learning problem is then decomposed into a series of multi-class classification problems, where each multi-class variable encodes a label powerset. H2PC is shown to compare favorably to MMHC in terms of global classification accuracy over ten multi-label data sets covering different application domains. Overall, our experiments support the conclusions that local structural learning with H2PC in the form of local neighborhood induction is a theoretically well-motivated and empirically effective learning framework that is well suited to multi-label learning. The source code (in R) of H2PC as well as all data sets used for the empirical tests are publicly available.
* arXiv admin note: text overlap with arXiv:1101.5184 by other authors