 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebrat: Aligned Multi-View Embeddings for Brain MRI Analysis
Dec 21, 2025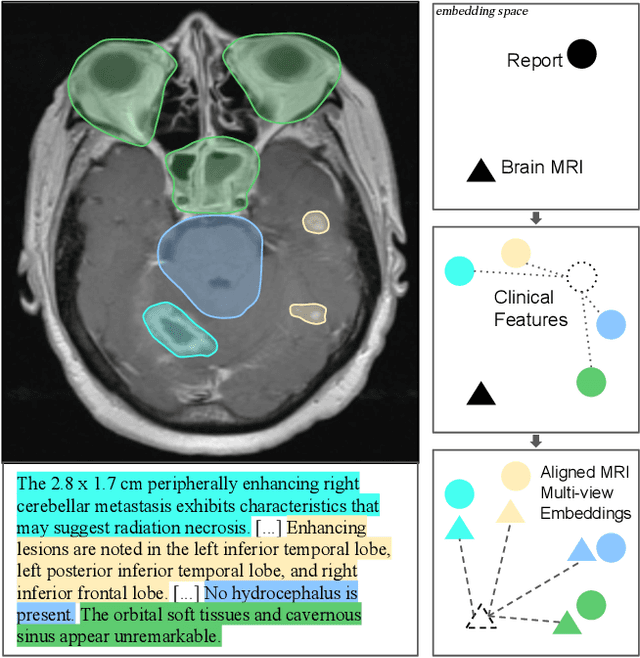
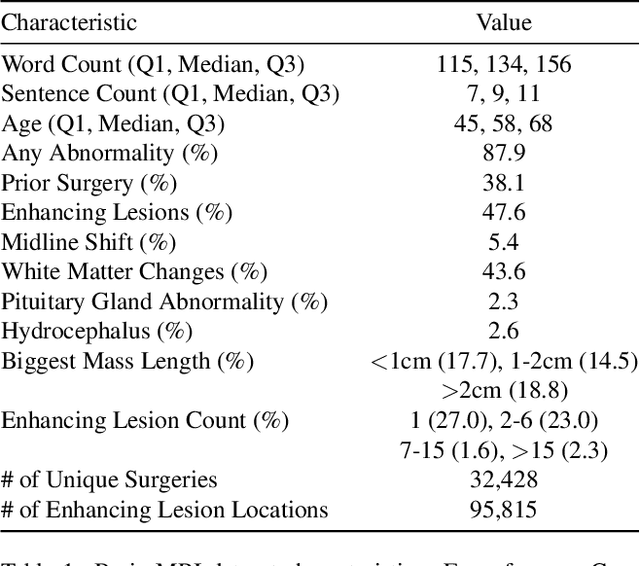
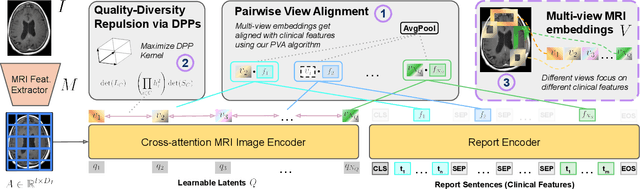
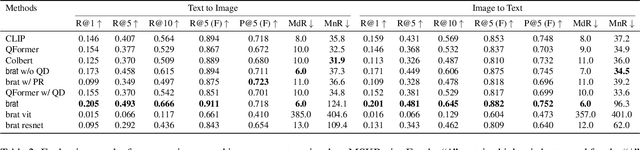
We present brat (brain report alignment transformer), a multi-view representation learning framework for brain magnetic resonance imaging (MRI) trained on MRIs paired with clinical reports. Brain MRIs present unique challenges due to the presence of numerous, highly varied, and often subtle abnormalities that are localized to a few slices within a 3D volume. To address these challenges, we introduce a brain MRI dataset $10\times$ larger than existing ones, containing approximately 80,000 3D scans with corresponding radiology reports, and propose a multi-view pre-training approach inspired by advances in document retrieval. We develop an implicit query-feature matching mechanism and adopt concepts from quality-diversity to obtain multi-view embeddings of MRIs that are aligned with the clinical features given by report sentences. We evaluate our approach across multiple vision-language and vision tasks, demonstrating substantial performance improvements. The brat foundation models are publicly released.
Improving Minimax Group Fairness in Sequential Recommendation
Jan 30, 2025
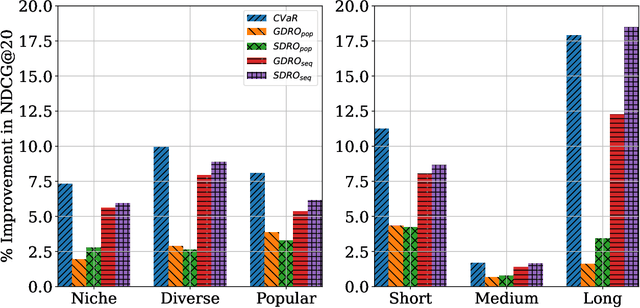
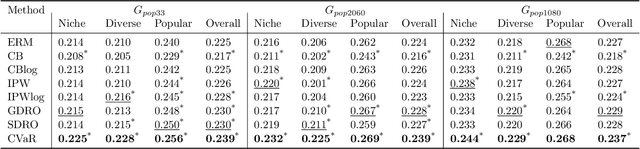
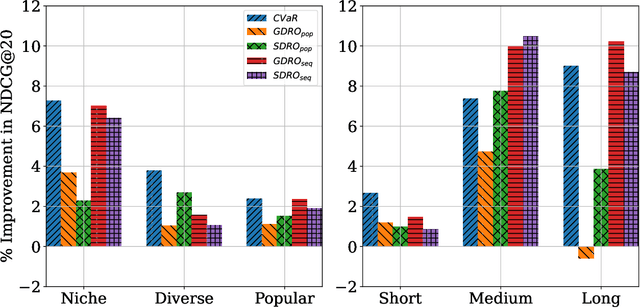
Training sequential recommenders such as SASRec with uniform sample weights achieves good overall performance but can fall short on specific user groups. One such example is popularity bias, where mainstream users receive better recommendations than niche content viewers. To improve recommendation quality across diverse user groups, we explore three Distributionally Robust Optimization(DRO) methods: Group DRO, Streaming DRO, and Conditional Value at Risk (CVaR) DRO. While Group and Streaming DRO rely on group annotations and struggle with users belonging to multiple groups, CVaR does not require such annotations and can naturally handle overlapping groups. In experiments on two real-world datasets, we show that the DRO methods outperform standard training, with CVaR delivering the best results. Additionally, we find that Group and Streaming DRO are sensitive to the choice of group used for loss computation. Our contributions include (i) a novel application of CVaR to recommenders, (ii) showing that the DRO methods improve group metrics as well as overall performance, and (iii) demonstrating CVaR's effectiveness in the practical scenario of intersecting user groups.
Aligning GPTRec with Beyond-Accuracy Goals with Reinforcement Learning
Mar 07, 2024Adaptations of Transformer models, such as BERT4Rec and SASRec, achieve state-of-the-art performance in the sequential recommendation task according to accuracy-based metrics, such as NDCG. These models treat items as tokens and then utilise a score-and-rank approach (Top-K strategy), where the model first computes item scores and then ranks them according to this score. While this approach works well for accuracy-based metrics, it is hard to use it for optimising more complex beyond-accuracy metrics such as diversity. Recently, the GPTRec model, which uses a different Next-K strategy, has been proposed as an alternative to the Top-K models. In contrast with traditional Top-K recommendations, Next-K generates recommendations item-by-item and, therefore, can account for complex item-to-item interdependencies important for the beyond-accuracy measures. However, the original GPTRec paper focused only on accuracy in experiments and needed to address how to optimise the model for complex beyond-accuracy metrics. Indeed, training GPTRec for beyond-accuracy goals is challenging because the interaction training data available for training recommender systems typically needs to be aligned with beyond-accuracy recommendation goals. To solve the misalignment problem, we train GPTRec using a 2-stage approach: in the first stage, we use a teacher-student approach to train GPTRec, mimicking the behaviour of traditional Top-K models; in the second stage, we use Reinforcement Learning to align the model for beyond-accuracy goals. In particular, we experiment with increasing recommendation diversity and reducing popularity bias. Our experiments on two datasets show that in 3 out of 4 cases, GPTRec's Next-K generation approach offers a better tradeoff between accuracy and secondary metrics than classic greedy re-ranking techniques.
gSASRec: Reducing Overconfidence in Sequential Recommendation Trained with Negative Sampling
Aug 14, 2023



A large catalogue size is one of the central challenges in training recommendation models: a large number of items makes them memory and computationally inefficient to compute scores for all items during training, forcing these models to deploy negative sampling. However, negative sampling increases the proportion of positive interactions in the training data, and therefore models trained with negative sampling tend to overestimate the probabilities of positive interactions a phenomenon we call overconfidence. While the absolute values of the predicted scores or probabilities are not important for the ranking of retrieved recommendations, overconfident models may fail to estimate nuanced differences in the top-ranked items, resulting in degraded performance. In this paper, we show that overconfidence explains why the popular SASRec model underperforms when compared to BERT4Rec. This is contrary to the BERT4Rec authors explanation that the difference in performance is due to the bi-directional attention mechanism. To mitigate overconfidence, we propose a novel Generalised Binary Cross-Entropy Loss function (gBCE) and theoretically prove that it can mitigate overconfidence. We further propose the gSASRec model, an improvement over SASRec that deploys an increased number of negatives and the gBCE loss. We show through detailed experiments on three datasets that gSASRec does not exhibit the overconfidence problem. As a result, gSASRec can outperform BERT4Rec (e.g. +9.47% NDCG on the MovieLens-1M dataset), while requiring less training time (e.g. -73% training time on MovieLens-1M). Moreover, in contrast to BERT4Rec, gSASRec is suitable for large datasets that contain more than 1 million items.
Effective and Efficient Training for Sequential Recommendation using Recency Sampling
Jul 15, 2022


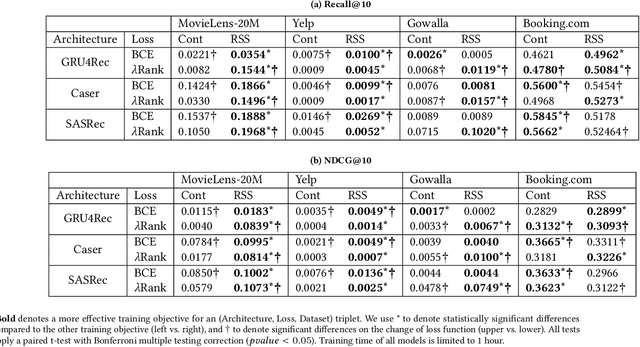
Many modern sequential recommender systems use deep neural networks, which can effectively estimate the relevance of items but require a lot of time to train. Slow training increases expenses, hinders product development timescales and prevents the model from being regularly updated to adapt to changing user preferences. Training such sequential models involves appropriately sampling past user interactions to create a realistic training objective. The existing training objectives have limitations. For instance, next item prediction never uses the beginning of the sequence as a learning target, thereby potentially discarding valuable data. On the other hand, the item masking used by BERT4Rec is only weakly related to the goal of the sequential recommendation; therefore, it requires much more time to obtain an effective model. Hence, we propose a novel Recency-based Sampling of Sequences training objective that addresses both limitations. We apply our method to various recent and state-of-the-art model architectures - such as GRU4Rec, Caser, and SASRec. We show that the models enhanced with our method can achieve performances exceeding or very close to stateof-the-art BERT4Rec, but with much less training time.
A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation
Jul 15, 2022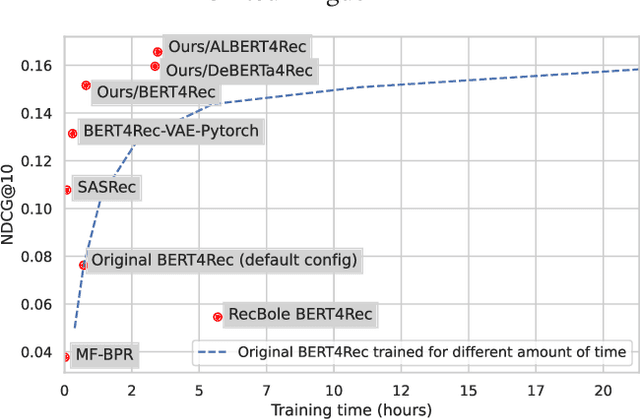

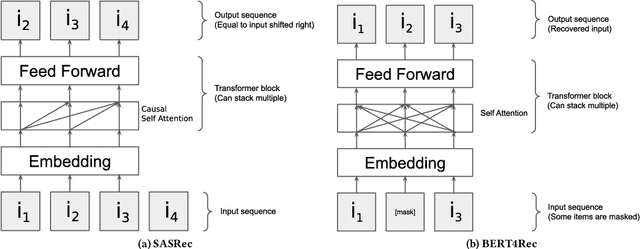

BERT4Rec is an effective model for sequential recommendation based on the Transformer architecture. In the original publication, BERT4Rec claimed superiority over other available sequential recommendation approaches (e.g. SASRec), and it is now frequently being used as a state-of-the art baseline for sequential recommendations. However, not all subsequent publications confirmed this result and proposed other models that were shown to outperform BERT4Rec in effectiveness. In this paper we systematically review all publications that compare BERT4Rec with another popular Transformer-based model, namely SASRec, and show that BERT4Rec results are not consistent within these publications. To understand the reasons behind this inconsistency, we analyse the available implementations of BERT4Rec and show that we fail to reproduce results of the original BERT4Rec publication when using their default configuration parameters. However, we are able to replicate the reported results with the original code if training for a much longer amount of time (up to 30x) compared to the default configuration. We also propose our own implementation of BERT4Rec based on the Hugging Face Transformers library, which we demonstrate replicates the originally reported results on 3 out 4 datasets, while requiring up to 95% less training time to converge. Overall, from our systematic review and detailed experiments, we conclude that BERT4Rec does indeed exhibit state-of-the-art effectiveness for sequential recommendation, but only when trained for a sufficient amount of time. Additionally, we show that our implementation can further benefit from adapting other Transformer architectures that are available in the Hugging Face Transformers library (e.g. using disentangled attention, as provided by DeBERTa, or larger hidden layer size cf. ALBERT).
Attention-based neural re-ranking approach for next city in trip recommendations
Mar 23, 2021

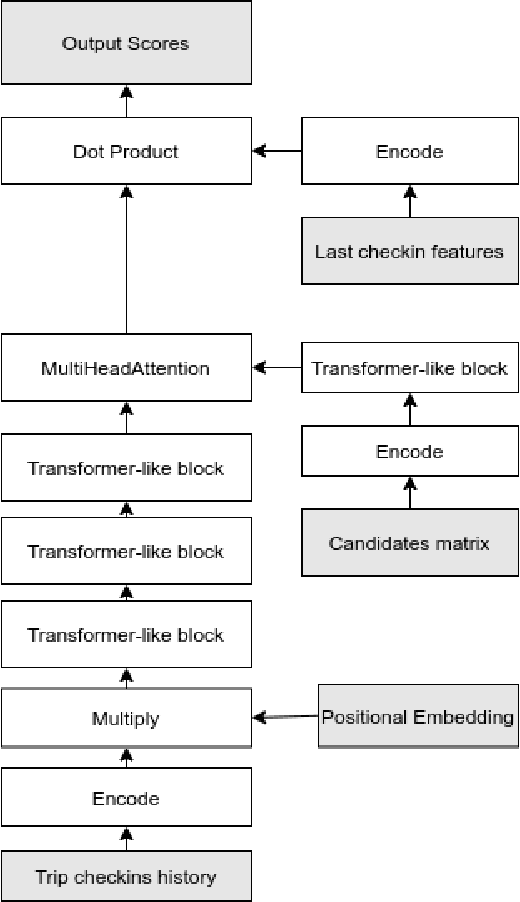

This paper describes an approach to solving the next destination city recommendation problem for a travel reservation system. We propose a two stages approach: a heuristic approach for candidates selection and an attention neural network model for candidates re-ranking. Our method was inspired by listwise learning-to-rank methods and recent developments in natural language processing and the transformer architecture in particular. We used this approach to solve the Booking.com recommendations challenge Our team achieved 5th place on the challenge using this method, with 0.555 accuracy@4 value on the closed part of the dataset.