 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation
Paper and Code
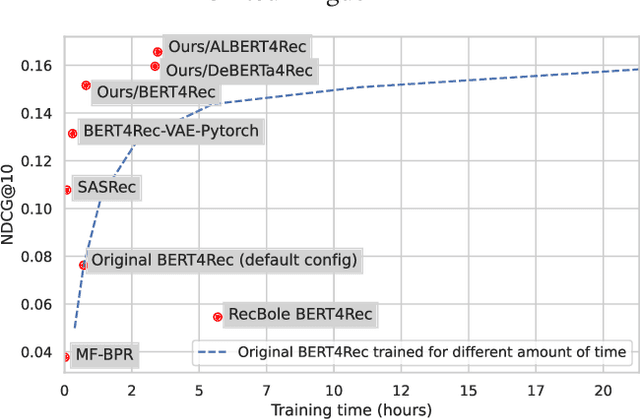

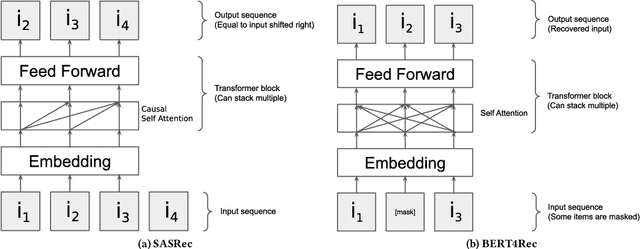

BERT4Rec is an effective model for sequential recommendation based on the Transformer architecture. In the original publication, BERT4Rec claimed superiority over other available sequential recommendation approaches (e.g. SASRec), and it is now frequently being used as a state-of-the art baseline for sequential recommendations. However, not all subsequent publications confirmed this result and proposed other models that were shown to outperform BERT4Rec in effectiveness. In this paper we systematically review all publications that compare BERT4Rec with another popular Transformer-based model, namely SASRec, and show that BERT4Rec results are not consistent within these publications. To understand the reasons behind this inconsistency, we analyse the available implementations of BERT4Rec and show that we fail to reproduce results of the original BERT4Rec publication when using their default configuration parameters. However, we are able to replicate the reported results with the original code if training for a much longer amount of time (up to 30x) compared to the default configuration. We also propose our own implementation of BERT4Rec based on the Hugging Face Transformers library, which we demonstrate replicates the originally reported results on 3 out 4 datasets, while requiring up to 95% less training time to converge. Overall, from our systematic review and detailed experiments, we conclude that BERT4Rec does indeed exhibit state-of-the-art effectiveness for sequential recommendation, but only when trained for a sufficient amount of time. Additionally, we show that our implementation can further benefit from adapting other Transformer architectures that are available in the Hugging Face Transformers library (e.g. using disentangled attention, as provided by DeBERTa, or larger hidden layer size cf. ALBERT).