 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Performance Increment Strategy for Semantic Segmentation of Low-Resolution Images from Damaged Roads
Nov 25, 2024



Autonomous driving needs good roads, but 85% of Brazilian roads have damages that deep learning models may not regard as most semantic segmentation datasets for autonomous driving are high-resolution images of well-maintained urban roads. A representative dataset for emerging countries consists of low-resolution images of poorly maintained roads and includes labels of damage classes; in this scenario, three challenges arise: objects with few pixels, objects with undefined shapes, and highly underrepresented classes. To tackle these challenges, this work proposes the Performance Increment Strategy for Semantic Segmentation (PISSS) as a methodology of 14 training experiments to boost performance. With PISSS, we reached state-of-the-art results of 79.8 and 68.8 mIoU on the Road Traversing Knowledge (RTK) and Technik Autonomer Systeme 500 (TAS500) test sets, respectively. Furthermore, we also offer an analysis of DeepLabV3+ pitfalls for small object segmentation.
Comparative analysis of deep learning approaches for AgNOR-stained cytology samples interpretation
Oct 19, 2022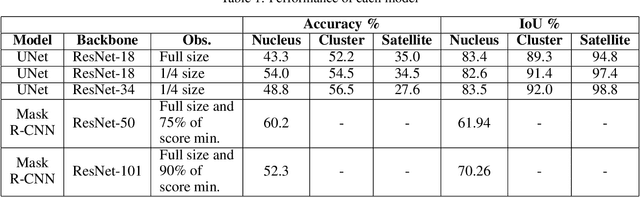
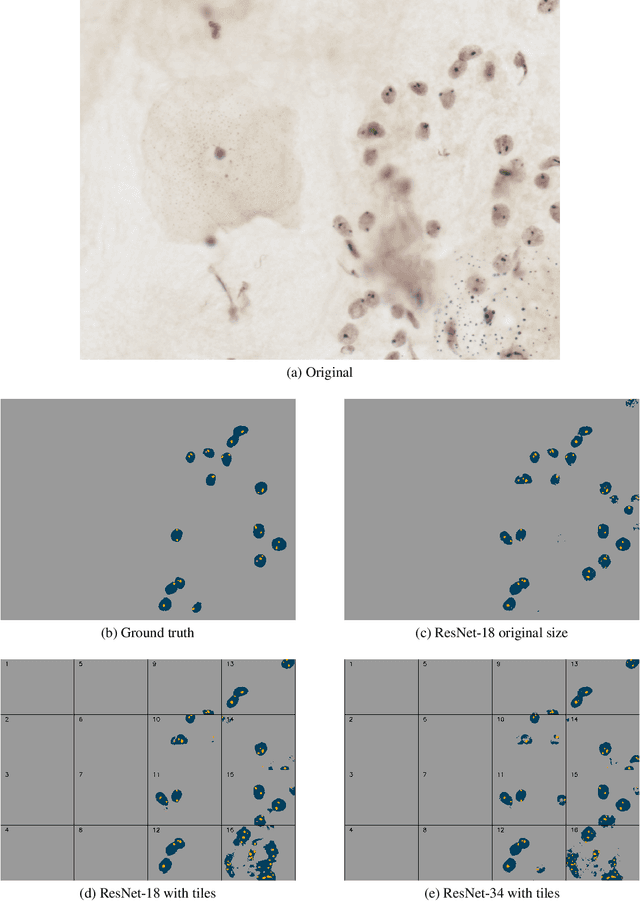

Cervical cancer is a public health problem, where the treatment has a better chance of success if detected early. The analysis is a manual process which is subject to a human error, so this paper provides a way to analyze argyrophilic nucleolar organizer regions (AgNOR) stained slide using deep learning approaches. Also, this paper compares models for instance and semantic detection approaches. Our results show that the semantic segmentation using U-Net with ResNet-18 or ResNet-34 as the backbone have similar results, and the best model shows an IoU for nucleus, cluster, and satellites of 0.83, 0.92, and 0.99 respectively. For instance segmentation, the Mask R-CNN using ResNet-50 performs better in the visual inspection and has a 0.61 of the IoU metric. We conclude that the instance segmentation and semantic segmentation models can be used in combination to make a cascade model able to select a nucleus and subsequently segment the nucleus and its respective nucleolar organizer regions (NORs).
What is the State of the Art of Computer Vision-Assisted Cytology? A Systematic Literature Review
May 24, 2021

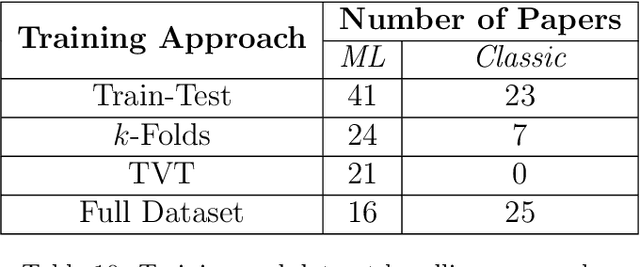

Cytology is a low-cost and non-invasive diagnostic procedure employed to support the diagnosis of a broad range of pathologies. Computer Vision technologies, by automatically generating quantitative and objective descriptions of examinations' contents, can help minimize the chances of misdiagnoses and shorten the time required for analysis. To identify the state-of-art of computer vision techniques currently applied to cytology, we conducted a Systematic Literature Review. We analyzed papers published in the last 5 years. The initial search was executed in September 2020 and resulted in 431 articles. After applying the inclusion/exclusion criteria, 157 papers remained, which we analyzed to build a picture of the tendencies and problems present in this research area, highlighting the computer vision methods, staining techniques, evaluation metrics, and the availability of the used datasets and computer code. As a result, we identified that the most used methods in the analyzed works are deep learning-based (70 papers), while fewer works employ classic computer vision only (101 papers). The most recurrent metric used for classification and object detection was the accuracy (33 papers and 5 papers), while for segmentation it was the Dice Similarity Coefficient (38 papers). Regarding staining techniques, Papanicolaou was the most employed one (130 papers), followed by H&E (20 papers) and Feulgen (5 papers). Twelve of the datasets used in the papers are publicly available, with the DTU/Herlev dataset being the most used one. We conclude that there still is a lack of high-quality datasets for many types of stains and most of the works are not mature enough to be applied in a daily clinical diagnostic routine. We also identified a growing tendency towards adopting deep learning-based approaches as the methods of choice.
Automatic code generation from sketches of mobile applications in end-user development using Deep Learning
Mar 09, 2021
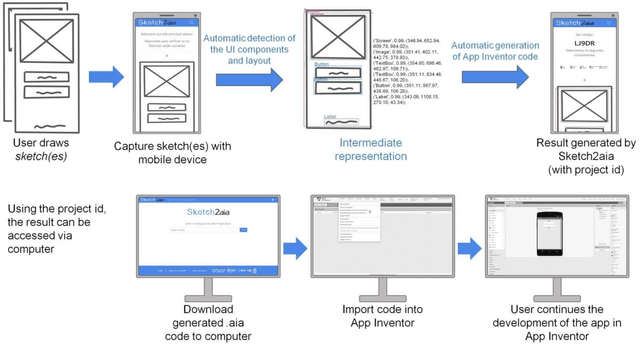
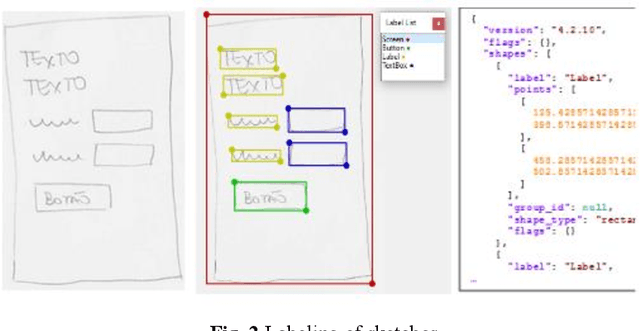

A common need for mobile application development by end-users or in computing education is to transform a sketch of a user interface into wireframe code using App Inventor, a popular block-based programming environment. As this task is challenging and time-consuming, we present the Sketch2aia approach that automates this process. Sketch2aia employs deep learning to detect the most frequent user interface components and their position on a hand-drawn sketch creating an intermediate representation of the user interface and then automatically generates the App Inventor code of the wireframe. The approach achieves an average user interface component classification accuracy of 87,72% and results of a preliminary user evaluation indicate that it generates wireframes that closely mirror the sketches in terms of visual similarity. The approach has been implemented as a web tool and can be used to support the end-user development of mobile applications effectively and efficiently as well as the teaching of user interface design in K-12.
Road obstacles positional and dynamic features extraction combining object detection, stereo disparity maps and optical flow data
Jun 24, 2020



One of the most relevant tasks in an intelligent vehicle navigation system is the detection of obstacles. It is important that a visual perception system for navigation purposes identifies obstacles, and it is also important that this system can extract essential information that may influence the vehicle's behavior, whether it will be generating an alert for a human driver or guide an autonomous vehicle in order to be able to make its driving decisions. In this paper we present an approach for the identification of obstacles and extraction of class, position, depth and motion information from these objects that employs data gained exclusively from passive vision. We performed our experiments on two different data-sets and the results obtained shown a good efficacy from the use of depth and motion patterns to assess the obstacles' potential threat status.
Road surface detection and differentiation considering surface damages
Jun 23, 2020



A challenge still to be overcome in the field of visual perception for vehicle and robotic navigation on heavily damaged and unpaved roads is the task of reliable path and obstacle detection. The vast majority of the researches have as scenario roads in good condition, from developed countries. These works cope with few situations of variation on the road surface and even fewer situations presenting surface damages. In this paper we present an approach for road detection considering variation in surface types, identifying paved and unpaved surfaces and also detecting damage and other information on other road surface that may be relevant to driving safety. We also present a new Ground Truth with image segmentation, used in our approach and that allowed us to evaluate our results. Our results show that it is possible to use passive vision for these purposes, even using images captured with low cost cameras.
Towards a Complete Pipeline for Segmenting Nuclei in Feulgen-Stained Images
Feb 19, 2020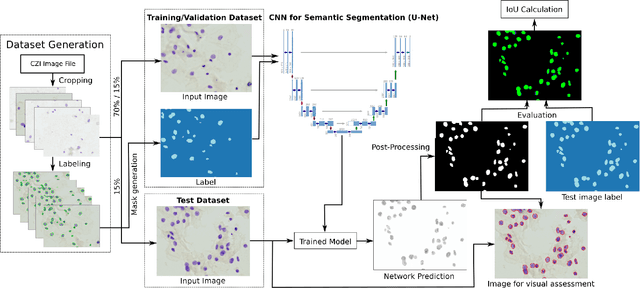
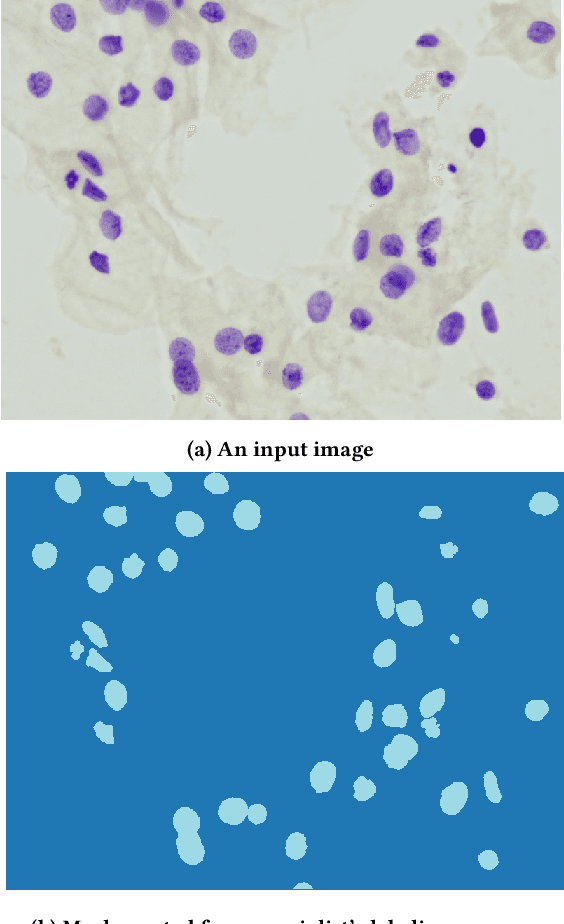
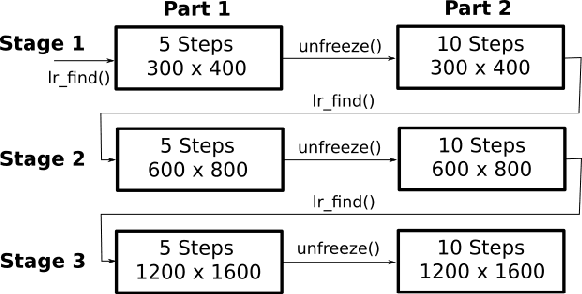
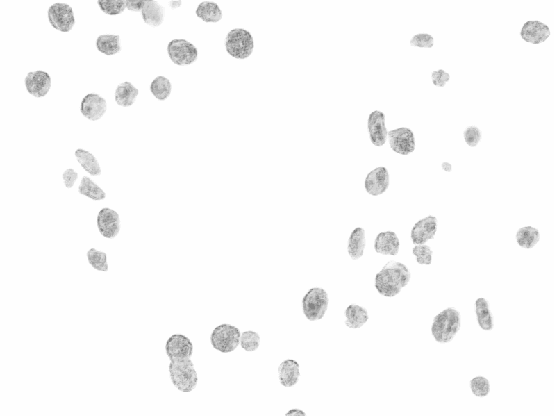
Cervical cancer is the second most common cancer type in women around the world. In some countries, due to non-existent or inadequate screening, it is often detected at late stages, making standard treatment options often absent or unaffordable. It is a deadly disease that could benefit from early detection approaches. It is usually done by cytological exams which consist of visually inspecting the nuclei searching for morphological alteration. Since it is done by humans, naturally, some subjectivity is introduced. Computational methods could be used to reduce this, where the first stage of the process would be the nuclei segmentation. In this context, we present a complete pipeline for the segmentation of nuclei in Feulgen-stained images using Convolutional Neural Networks. Here we show the entire process of segmentation, since the collection of the samples, passing through pre-processing, training the network, post-processing and results evaluation. We achieved an overall IoU of 0.78, showing the affordability of the approach of nuclei segmentation on Feulgen-stained images. The code is available in: https://github.com/luizbuschetto/feulgen_nuclei_segmentation.