 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the State of the Art of Computer Vision-Assisted Cytology? A Systematic Literature Review
May 24, 2021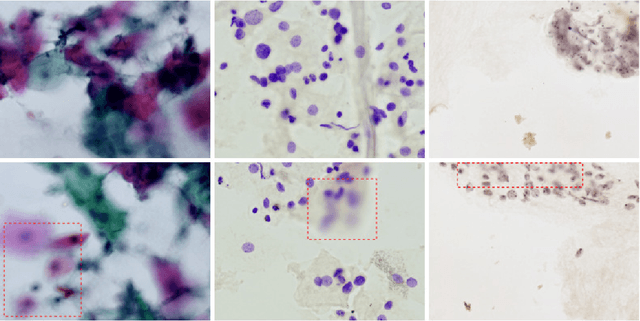

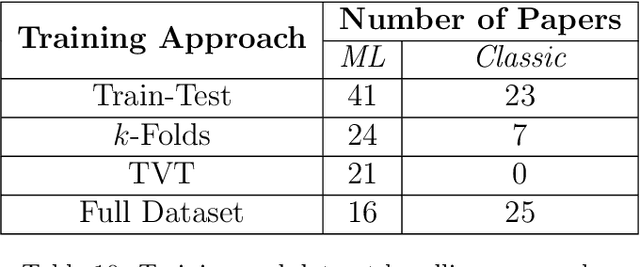

Cytology is a low-cost and non-invasive diagnostic procedure employed to support the diagnosis of a broad range of pathologies. Computer Vision technologies, by automatically generating quantitative and objective descriptions of examinations' contents, can help minimize the chances of misdiagnoses and shorten the time required for analysis. To identify the state-of-art of computer vision techniques currently applied to cytology, we conducted a Systematic Literature Review. We analyzed papers published in the last 5 years. The initial search was executed in September 2020 and resulted in 431 articles. After applying the inclusion/exclusion criteria, 157 papers remained, which we analyzed to build a picture of the tendencies and problems present in this research area, highlighting the computer vision methods, staining techniques, evaluation metrics, and the availability of the used datasets and computer code. As a result, we identified that the most used methods in the analyzed works are deep learning-based (70 papers), while fewer works employ classic computer vision only (101 papers). The most recurrent metric used for classification and object detection was the accuracy (33 papers and 5 papers), while for segmentation it was the Dice Similarity Coefficient (38 papers). Regarding staining techniques, Papanicolaou was the most employed one (130 papers), followed by H&E (20 papers) and Feulgen (5 papers). Twelve of the datasets used in the papers are publicly available, with the DTU/Herlev dataset being the most used one. We conclude that there still is a lack of high-quality datasets for many types of stains and most of the works are not mature enough to be applied in a daily clinical diagnostic routine. We also identified a growing tendency towards adopting deep learning-based approaches as the methods of choice.
Towards a Complete Pipeline for Segmenting Nuclei in Feulgen-Stained Images
Feb 19, 2020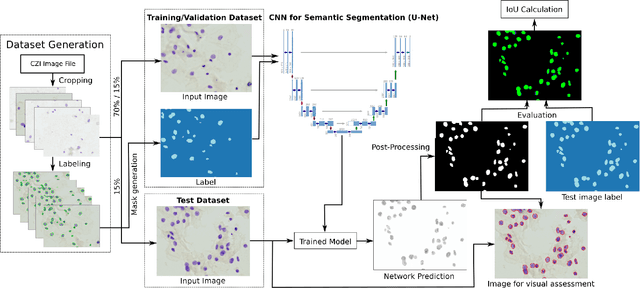
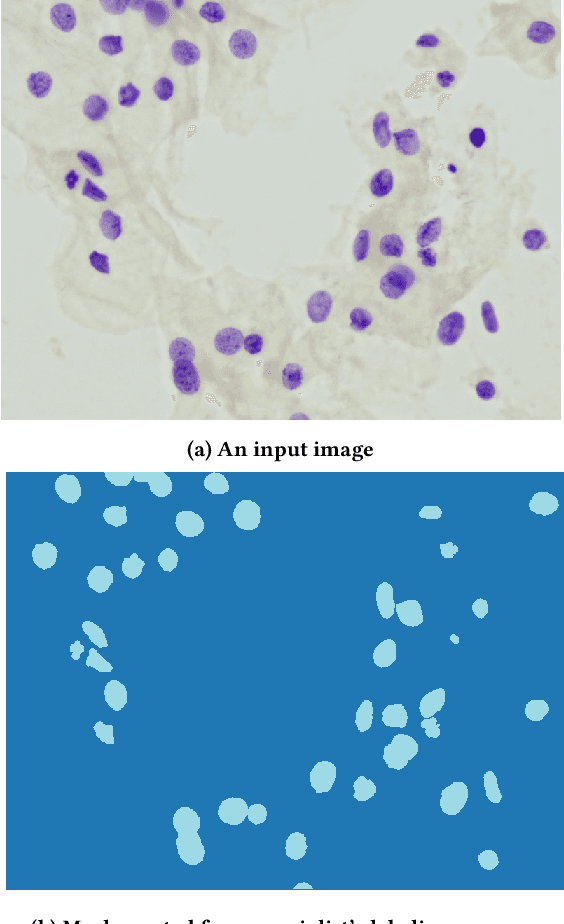
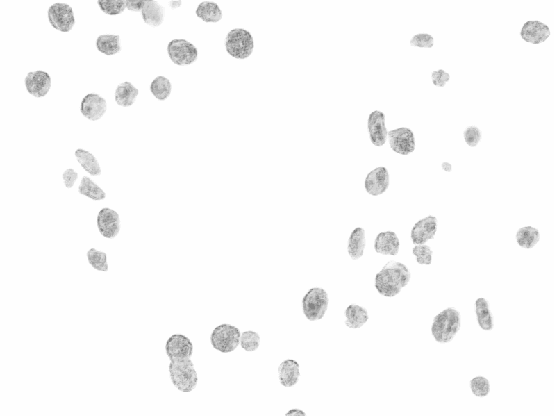
Cervical cancer is the second most common cancer type in women around the world. In some countries, due to non-existent or inadequate screening, it is often detected at late stages, making standard treatment options often absent or unaffordable. It is a deadly disease that could benefit from early detection approaches. It is usually done by cytological exams which consist of visually inspecting the nuclei searching for morphological alteration. Since it is done by humans, naturally, some subjectivity is introduced. Computational methods could be used to reduce this, where the first stage of the process would be the nuclei segmentation. In this context, we present a complete pipeline for the segmentation of nuclei in Feulgen-stained images using Convolutional Neural Networks. Here we show the entire process of segmentation, since the collection of the samples, passing through pre-processing, training the network, post-processing and results evaluation. We achieved an overall IoU of 0.78, showing the affordability of the approach of nuclei segmentation on Feulgen-stained images. The code is available in: https://github.com/luizbuschetto/feulgen_nuclei_segmentation.
Incremental and Decremental Fuzzy Bounded Twin Support Vector Machine
Jul 22, 2019
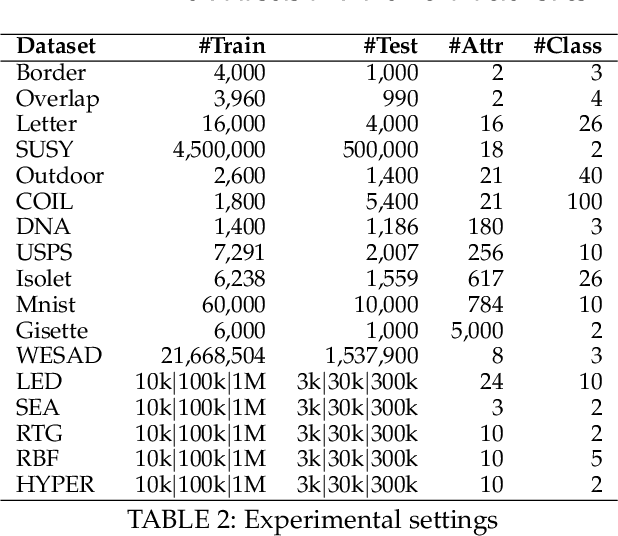


In this paper we present an incremental variant of the Twin Support Vector Machine (TWSVM) called Fuzzy Bounded Twin Support Vector Machine (FBTWSVM) to deal with large datasets and learning from data streams. We combine the TWSVM with a fuzzy membership function, so that each input has a different contribution to each hyperplane in a binary classifier. To solve the pair of quadratic programming problems (QPPs) we use a dual coordinate descent algorithm with a shrinking strategy, and to obtain a robust classification with a fast training we propose the use of a Fourier Gaussian approximation function with our linear FBTWSVM. Inspired by the shrinking technique, the incremental algorithm re-utilizes part of the training method with some heuristics, while the decremental procedure is based on a scored window. The FBTWSVM is also extended for multi-class problems by combining binary classifiers using a Directed Acyclic Graph (DAG) approach. Moreover, we analyzed the theoretical foundations properties of the proposed approach and its extension, and the experimental results on benchmark datasets indicate that the FBTWSVM has a fast training and retraining process while maintaining a robust classification performance.