 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling heterogeneous distributions with an Uncountable Mixture of Asymmetric Laplacians
Oct 29, 2019
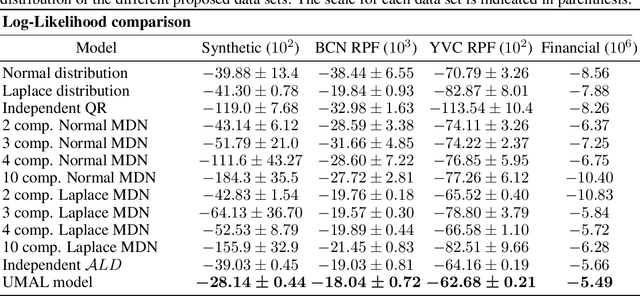
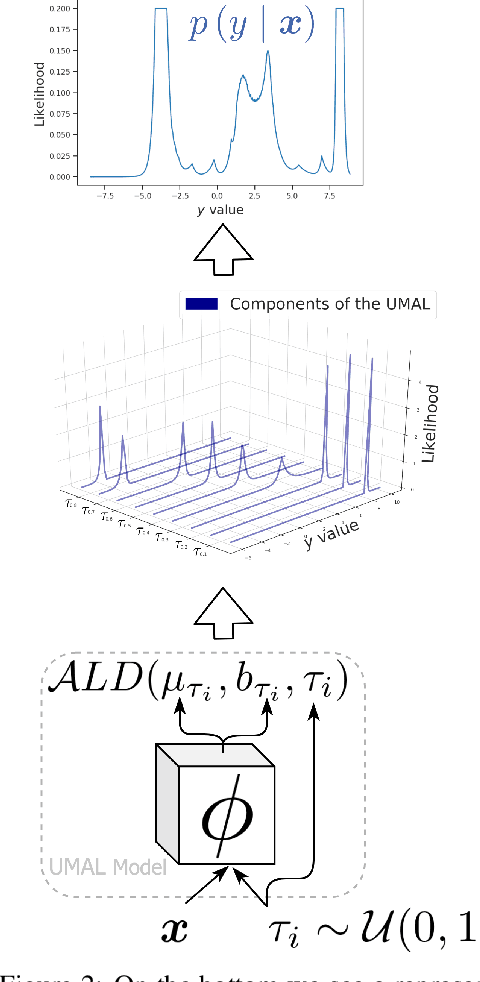

In regression tasks, aleatoric uncertainty is commonly addressed by considering a parametric distribution of the output variable, which is based on strong assumptions such as symmetry, unimodality or by supposing a restricted shape. These assumptions are too limited in scenarios where complex shapes, strong skews or multiple modes are present. In this paper, we propose a generic deep learning framework that learns an Uncountable Mixture of Asymmetric Laplacians (UMAL), which will allow us to estimate heterogeneous distributions of the output variable and shows its connections to quantile regression. Despite having a fixed number of parameters, the model can be interpreted as an infinite mixture of components, which yields a flexible approximation for heterogeneous distributions. Apart from synthetic cases, we apply this model to room price forecasting and to predict financial operations in personal bank accounts. We demonstrate that UMAL produces proper distributions, which allows us to extract richer insights and to sharpen decision-making.
Reinforcement Learning for Fair Dynamic Pricing
Mar 27, 2018



Unfair pricing policies have been shown to be one of the most negative perceptions customers can have concerning pricing, and may result in long-term losses for a company. Despite the fact that dynamic pricing models help companies maximize revenue, fairness and equality should be taken into account in order to avoid unfair price differences between groups of customers. This paper shows how to solve dynamic pricing by using Reinforcement Learning (RL) techniques so that prices are maximized while keeping a balance between revenue and fairness. We demonstrate that RL provides two main features to support fairness in dynamic pricing: on the one hand, RL is able to learn from recent experience, adapting the pricing policy to complex market environments; on the other hand, it provides a trade-off between short and long-term objectives, hence integrating fairness into the model's core. Considering these two features, we propose the application of RL for revenue optimization, with the additional integration of fairness as part of the learning procedure by using Jain's index as a metric. Results in a simulated environment show a significant improvement in fairness while at the same time maintaining optimisation of revenue.