 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Missing Information Loss function for implicit feedback datasets
Aug 16, 2018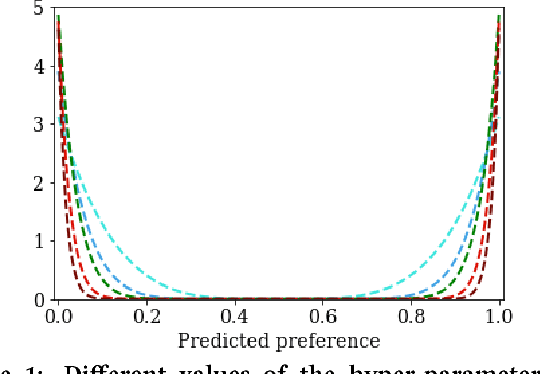



Latent factor models for Recommender Systems with implicit feedback typically treat unobserved user-item interactions (i.e. missing information) as negative feedback. This is frequently done either through negative sampling (point--wise loss) or with a ranking loss function (pair-- or list--wise estimation). Since a zero preference recommendation is a valid solution for most common objective functions, regarding unknown values as actual zeros results in users having a zero preference recommendation for most of the available items. In this paper we propose a novel objective function, the \emph{Missing Information Loss} (MIL), that explicitly forbids treating unobserved user-item interactions as positive or negative feedback. We apply this loss to both traditional Matrix Factorization and user--based Denoising Autoencoder, and compare it with other established objective functions such as cross-entropy (both point- and pair-wise) or the recently proposed multinomial log-likelihood. MIL achieves competitive performance in ranking-aware metrics when applied to three datasets. Furthermore, we show that such a relevance in the recommendation is obtained while displaying popular items less frequently (up to a $20 \%$ decrease with respect to the best competing method). This debiasing from the recommendation of popular items favours the appearance of infrequent items (up to a $50 \%$ increase of long-tail recommendations), a valuable feature for Recommender Systems with a large catalogue of products.
Reinforcement Learning for Fair Dynamic Pricing
Mar 27, 2018



Unfair pricing policies have been shown to be one of the most negative perceptions customers can have concerning pricing, and may result in long-term losses for a company. Despite the fact that dynamic pricing models help companies maximize revenue, fairness and equality should be taken into account in order to avoid unfair price differences between groups of customers. This paper shows how to solve dynamic pricing by using Reinforcement Learning (RL) techniques so that prices are maximized while keeping a balance between revenue and fairness. We demonstrate that RL provides two main features to support fairness in dynamic pricing: on the one hand, RL is able to learn from recent experience, adapting the pricing policy to complex market environments; on the other hand, it provides a trade-off between short and long-term objectives, hence integrating fairness into the model's core. Considering these two features, we propose the application of RL for revenue optimization, with the additional integration of fairness as part of the learning procedure by using Jain's index as a metric. Results in a simulated environment show a significant improvement in fairness while at the same time maintaining optimisation of revenue.