 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFN: Towards Generalizable Facial Action Unit Recognition with Deep Face Normalization
Mar 03, 2021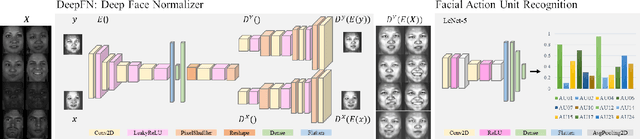
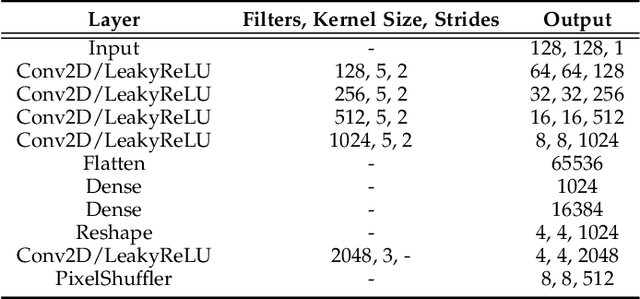
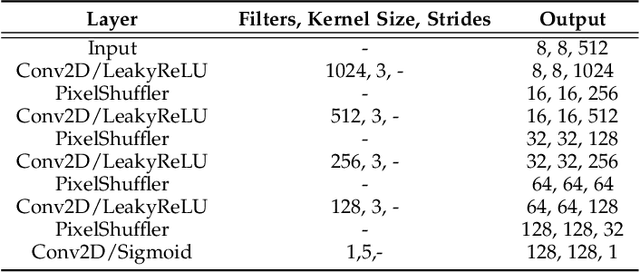
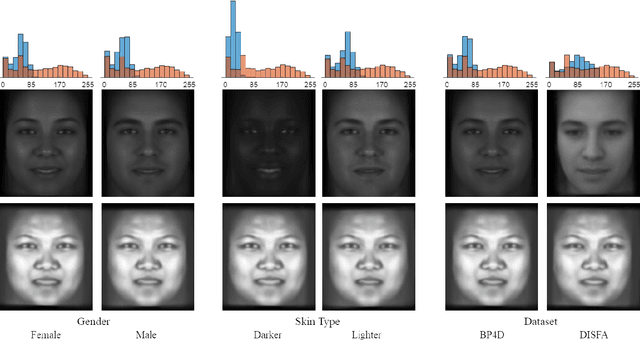
Facial action unit recognition has many applications from market research to psychotherapy and from image captioning to entertainment. Despite its recent progress, deployment of these models has been impeded due to their limited generalization to unseen people and demographics. This work conducts an in-depth analysis of performance across several dimensions: individuals(40 subjects), genders (male and female), skin types (darker and lighter), and databases (BP4D and DISFA). To help suppress the variance in data, we use the notion of self-supervised denoising autoencoders to design a method for deep face normalization(DeepFN) that transfers facial expressions of different people onto a common facial template which is then used to train and evaluate facial action recognition models. We show that person-independent models yield significantly lower performance (55% average F1 and accuracy across 40 subjects) than person-dependent models (60.3%), leading to a generalization gap of 5.3%. However, normalizing the data with the newly introduced DeepFN significantly increased the performance of person-independent models (59.6%), effectively reducing the gap. Similarly, we observed generalization gaps when considering gender (2.4%), skin type (5.3%), and dataset (9.4%), which were significantly reduced with the use of DeepFN. These findings represent an important step towards the creation of more generalizable facial action unit recognition systems.
A Scalable Approach for Facial Action Unit Classifier Training UsingNoisy Data for Pre-Training
Nov 14, 2019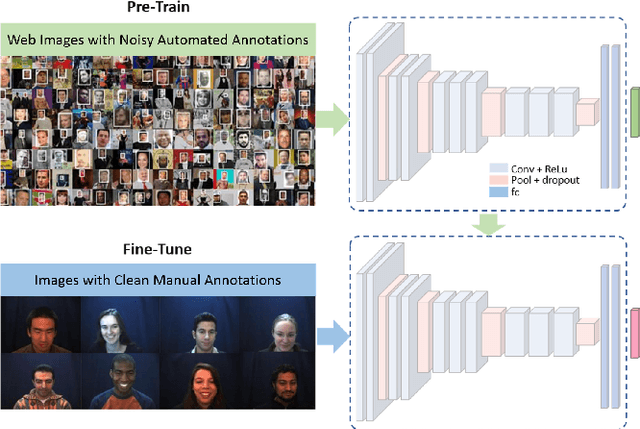

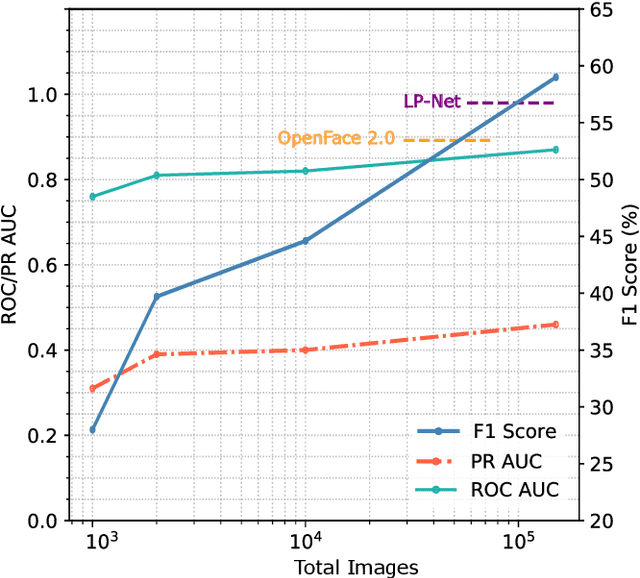
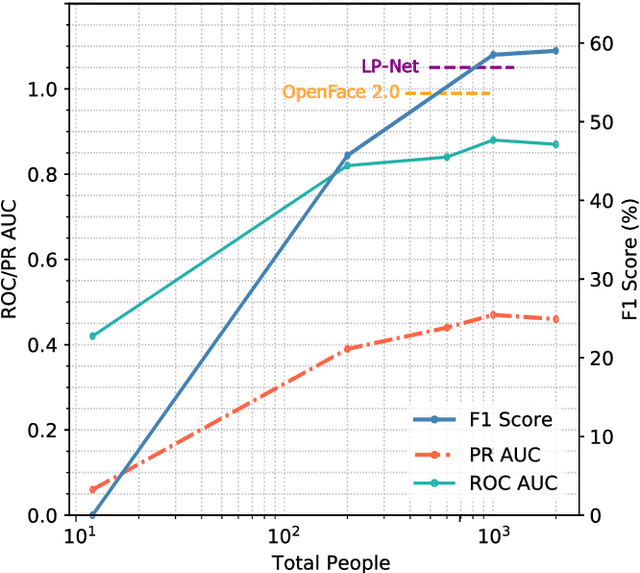
Machine learning systems are being used to automate many types of laborious labeling tasks. Facial actioncoding is an example of such a labeling task that requires copious amounts of time and a beyond average level of human domain expertise. In recent years, the use of end-to-end deep neural networks has led to significant improvements in action unit recognition performance and many network architectures have been proposed. Do the more complex deep neural network(DNN) architectures perform sufficiently well to justify the additional complexity? We show that pre-training on a large diverse set of noisy data can result in even a simple CNN model improving over the current state-of-the-art DNN architectures.The average F1-score achieved with our proposed method on the DISFA dataset is 0.60, compared to a previous state-of-the-art of 0.57. Additionally, we show how the number of subjects and number of images used for pre-training impacts the model performance. The approach that we have outlined is open-source, highly scalable, and not dependent on the model architecture. We release the code and data: https://github.com/facialactionpretrain/facs.