 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Approach for Facial Action Unit Classifier Training UsingNoisy Data for Pre-Training
Paper and Code
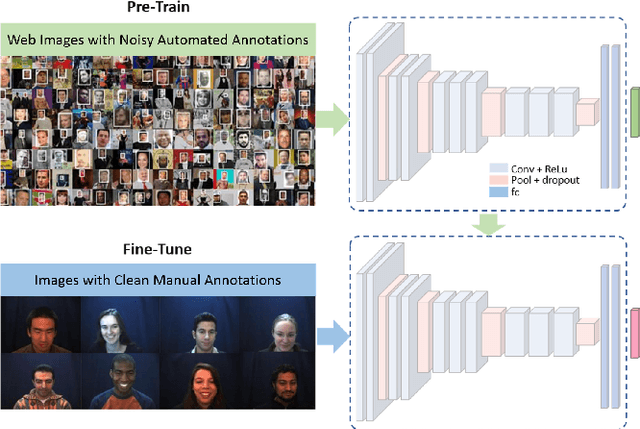

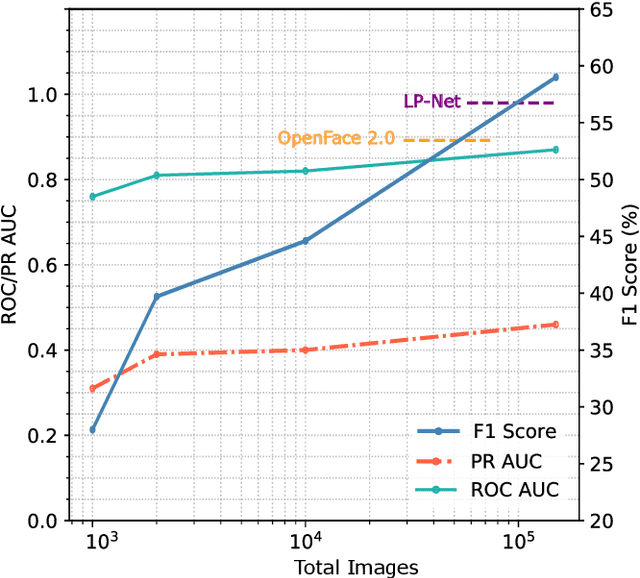
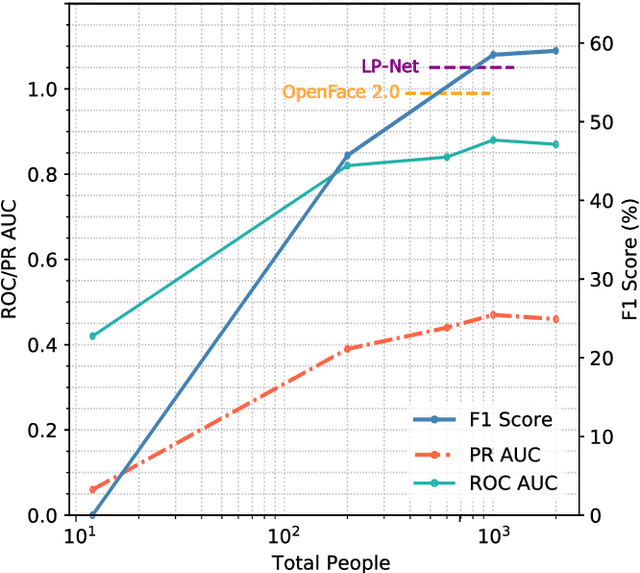
Machine learning systems are being used to automate many types of laborious labeling tasks. Facial actioncoding is an example of such a labeling task that requires copious amounts of time and a beyond average level of human domain expertise. In recent years, the use of end-to-end deep neural networks has led to significant improvements in action unit recognition performance and many network architectures have been proposed. Do the more complex deep neural network(DNN) architectures perform sufficiently well to justify the additional complexity? We show that pre-training on a large diverse set of noisy data can result in even a simple CNN model improving over the current state-of-the-art DNN architectures.The average F1-score achieved with our proposed method on the DISFA dataset is 0.60, compared to a previous state-of-the-art of 0.57. Additionally, we show how the number of subjects and number of images used for pre-training impacts the model performance. The approach that we have outlined is open-source, highly scalable, and not dependent on the model architecture. We release the code and data: https://github.com/facialactionpretrain/facs.