 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
NimbleD: Enhancing Self-supervised Monocular Depth Estimation with Pseudo-labels and Large-scale Video Pre-training
Aug 26, 2024We introduce NimbleD, an efficient self-supervised monocular depth estimation learning framework that incorporates supervision from pseudo-labels generated by a large vision model. This framework does not require camera intrinsics, enabling large-scale pre-training on publicly available videos. Our straightforward yet effective learning strategy significantly enhances the performance of fast and lightweight models without introducing any overhead, allowing them to achieve performance comparable to state-of-the-art self-supervised monocular depth estimation models. This advancement is particularly beneficial for virtual and augmented reality applications requiring low latency inference. The source code, model weights, and acknowledgments are available at https://github.com/xapaxca/nimbled .
The Third Monocular Depth Estimation Challenge
Apr 27, 2024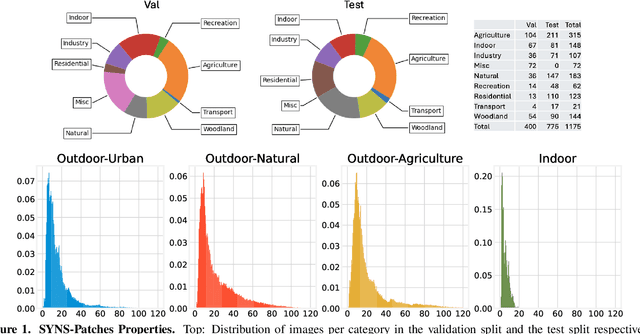

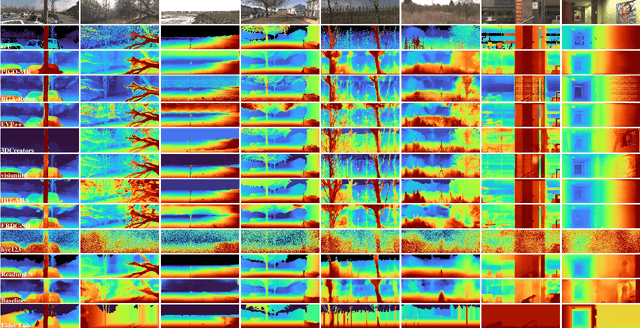
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.