 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution of ESG-focused DLT Research: An NLP Analysis of the Literature
Aug 23, 2023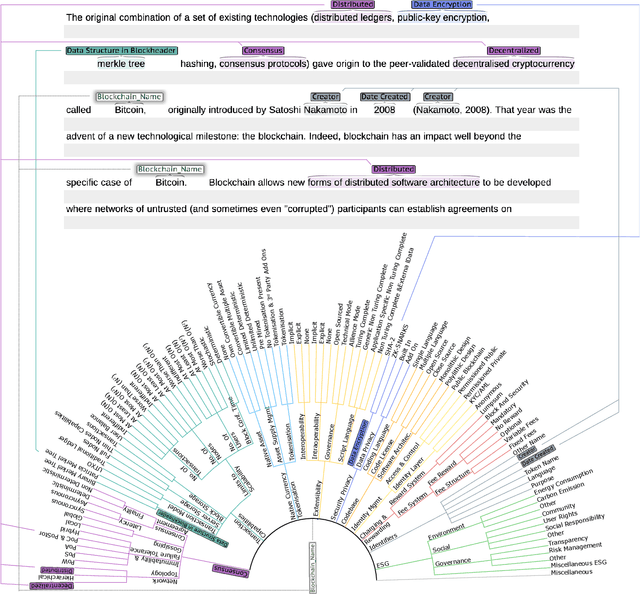
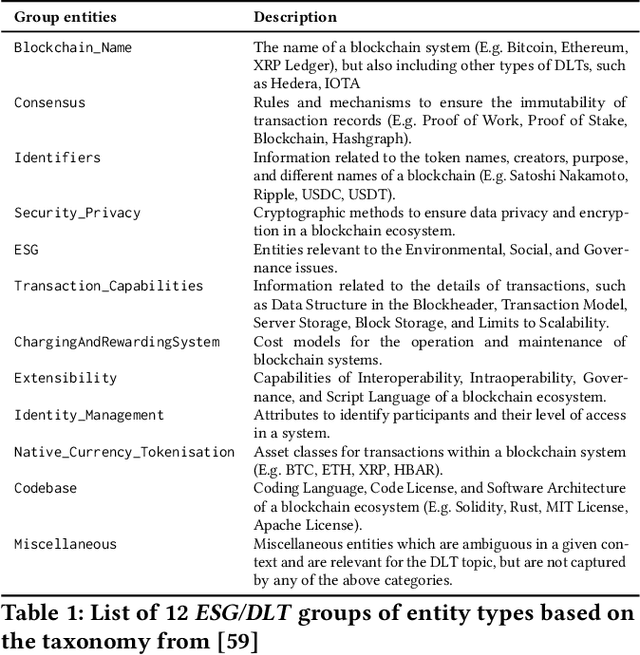
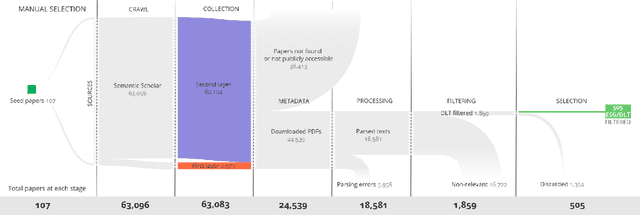
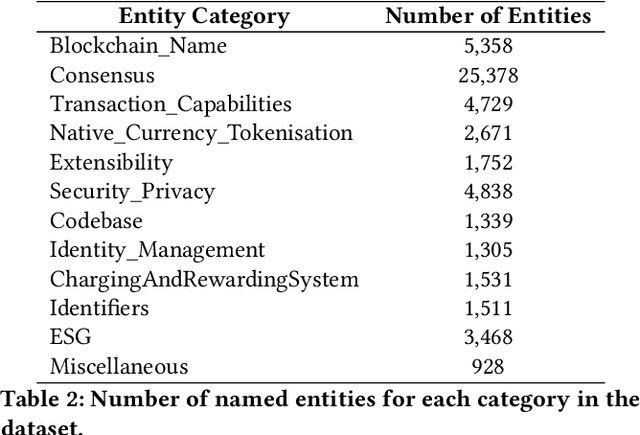
Distributed Ledger Technologies (DLTs) have rapidly evolved, necessitating comprehensive insights into their diverse components. However, a systematic literature review that emphasizes the Environmental, Sustainability, and Governance (ESG) components of DLT remains lacking. To bridge this gap, we selected 107 seed papers to build a citation network of 63,083 references and refined it to a corpus of 24,539 publications for analysis. Then, we labeled the named entities in 46 papers according to twelve top-level categories derived from an established technology taxonomy and enhanced the taxonomy by pinpointing DLT's ESG elements. Leveraging transformer-based language models, we fine-tuned a pre-trained language model for a Named Entity Recognition (NER) task using our labeled dataset. We used our fine-tuned language model to distill the corpus to 505 key papers, facilitating a literature review via named entities and temporal graph analysis on DLT evolution in the context of ESG. Our contributions are a methodology to conduct a machine learning-driven systematic literature review in the DLT field, placing a special emphasis on ESG aspects. Furthermore, we present a first-of-its-kind NER dataset, composed of 54,808 named entities, designed for DLT and ESG-related explorations.
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Apr 18, 2021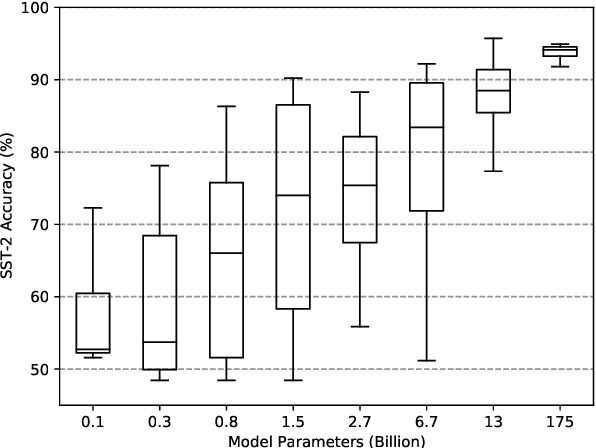


When primed with only a handful of training samples, very large pretrained language models such as GPT-3, have shown competitive results when compared to fully-supervised fine-tuned large pretrained language models. We demonstrate that the order in which the samples are provided can be the difference between near state-of-the-art and random guess performance: Essentially some permutations are "fantastic" and some not. We analyse this phenomenon in detail, establishing that: it is present across model sizes (even for the largest current models), it is not related to a specific subset of samples, and that a given good permutation for one model is not transferable to another. While one could use a development set to determine which permutations are performant, this would deviate from the few-shot setting as it requires additional annotated data. Instead, we use the generative nature of the language models to construct an artificial development set and based on entropy statistics of the candidate permutations from this set we identify performant prompts. Our method improves upon GPT-family models by on average 13% relative across eleven different established text classification tasks.