 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypUC: Hyperfine Uncertainty Calibration with Gradient-boosted Corrections for Reliable Regression on Imbalanced Electrocardiograms
Nov 23, 2023The automated analysis of medical time series, such as the electrocardiogram (ECG), electroencephalogram (EEG), pulse oximetry, etc, has the potential to serve as a valuable tool for diagnostic decisions, allowing for remote monitoring of patients and more efficient use of expensive and time-consuming medical procedures. Deep neural networks (DNNs) have been demonstrated to process such signals effectively. However, previous research has primarily focused on classifying medical time series rather than attempting to regress the continuous-valued physiological parameters central to diagnosis. One significant challenge in this regard is the imbalanced nature of the dataset, as a low prevalence of abnormal conditions can lead to heavily skewed data that results in inaccurate predictions and a lack of certainty in such predictions when deployed. To address these challenges, we propose HypUC, a framework for imbalanced probabilistic regression in medical time series, making several contributions. (i) We introduce a simple kernel density-based technique to tackle the imbalanced regression problem with medical time series. (ii) Moreover, we employ a probabilistic regression framework that allows uncertainty estimation for the predicted continuous values. (iii) We also present a new approach to calibrate the predicted uncertainty further. (iv) Finally, we demonstrate a technique to use calibrated uncertainty estimates to improve the predicted continuous value and show the efficacy of the calibrated uncertainty estimates to flag unreliable predictions. HypUC is evaluated on a large, diverse, real-world dataset of ECGs collected from millions of patients, outperforming several conventional baselines on various diagnostic tasks, suggesting a potential use-case for the reliable clinical deployment of deep learning models.
* Published at TMLR
AMMUS : A Survey of Transformer-based Pretrained Models in Natural Language Processing
Aug 28, 2021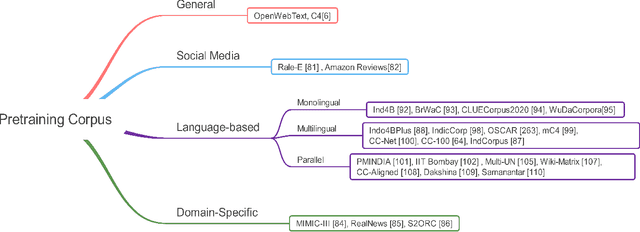
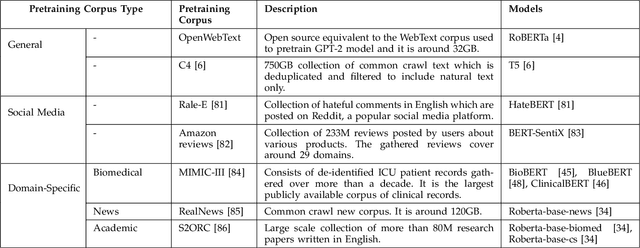

Transformer-based pretrained language models (T-PTLMs) have achieved great success in almost every NLP task. The evolution of these models started with GPT and BERT. These models are built on the top of transformers, self-supervised learning and transfer learning. Transformed-based PTLMs learn universal language representations from large volumes of text data using self-supervised learning and transfer this knowledge to downstream tasks. These models provide good background knowledge to downstream tasks which avoids training of downstream models from scratch. In this comprehensive survey paper, we initially give a brief overview of self-supervised learning. Next, we explain various core concepts like pretraining, pretraining methods, pretraining tasks, embeddings and downstream adaptation methods. Next, we present a new taxonomy of T-PTLMs and then give brief overview of various benchmarks including both intrinsic and extrinsic. We present a summary of various useful libraries to work with T-PTLMs. Finally, we highlight some of the future research directions which will further improve these models. We strongly believe that this comprehensive survey paper will serve as a good reference to learn the core concepts as well as to stay updated with the recent happenings in T-PTLMs.
AMMU -- A Survey of Transformer-based Biomedical Pretrained Language Models
Apr 16, 2021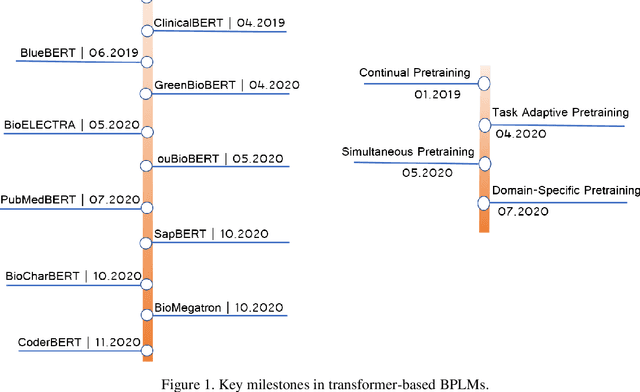


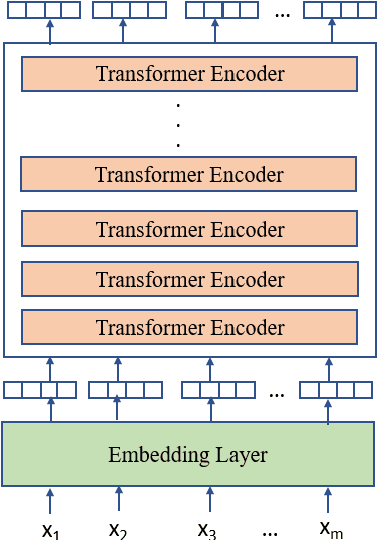
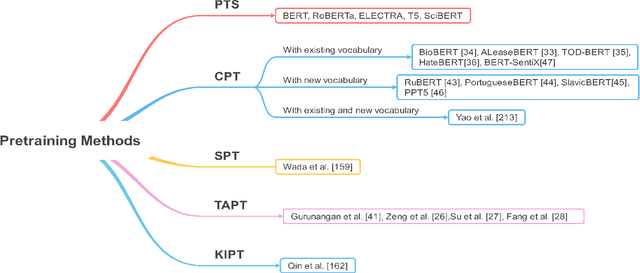
Transformer-based pretrained language models (PLMs) have started a new era in modern natural language processing (NLP). These models combine the power of transformers, transfer learning, and self-supervised learning (SSL). Following the success of these models in the general domain, the biomedical research community has developed various in-domain PLMs starting from BioBERT to the latest BioMegatron and CoderBERT models. We strongly believe there is a need for a survey paper that can provide a comprehensive survey of various transformer-based biomedical pretrained language models (BPLMs). In this survey, we start with a brief overview of foundational concepts like self-supervised learning, embedding layer and transformer encoder layers. We discuss core concepts of transformer-based PLMs like pretraining methods, pretraining tasks, fine-tuning methods, and various embedding types specific to biomedical domain. We introduce a taxonomy for transformer-based BPLMs and then discuss all the models. We discuss various challenges and present possible solutions. We conclude by highlighting some of the open issues which will drive the research community to further improve transformer-based BPLMs.