 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMMU -- A Survey of Transformer-based Biomedical Pretrained Language Models
Paper and Code
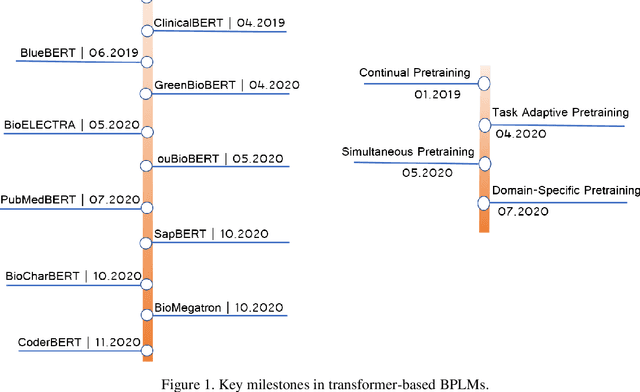


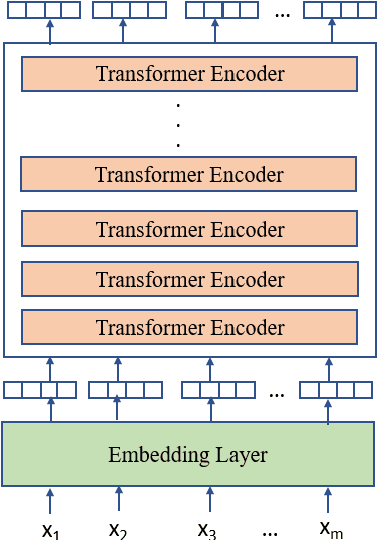
Transformer-based pretrained language models (PLMs) have started a new era in modern natural language processing (NLP). These models combine the power of transformers, transfer learning, and self-supervised learning (SSL). Following the success of these models in the general domain, the biomedical research community has developed various in-domain PLMs starting from BioBERT to the latest BioMegatron and CoderBERT models. We strongly believe there is a need for a survey paper that can provide a comprehensive survey of various transformer-based biomedical pretrained language models (BPLMs). In this survey, we start with a brief overview of foundational concepts like self-supervised learning, embedding layer and transformer encoder layers. We discuss core concepts of transformer-based PLMs like pretraining methods, pretraining tasks, fine-tuning methods, and various embedding types specific to biomedical domain. We introduce a taxonomy for transformer-based BPLMs and then discuss all the models. We discuss various challenges and present possible solutions. We conclude by highlighting some of the open issues which will drive the research community to further improve transformer-based BPLMs.