 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrasp Transfer based on Self-Aligning Implicit Representations of Local Surfaces
Aug 15, 2023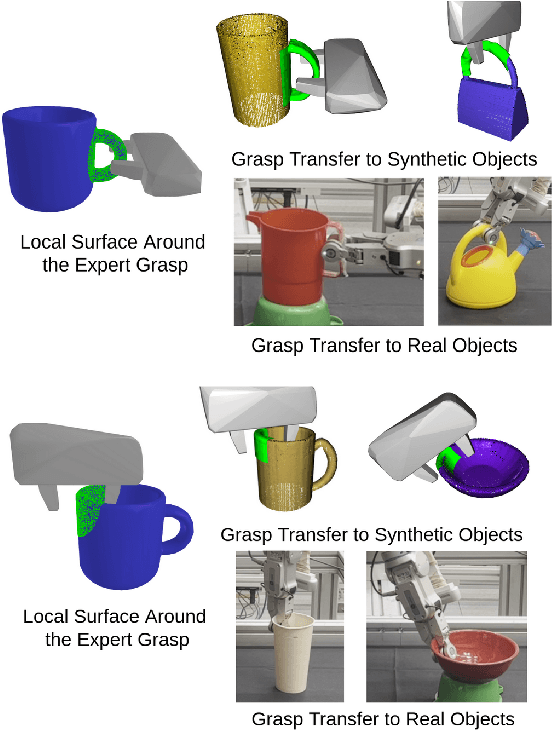
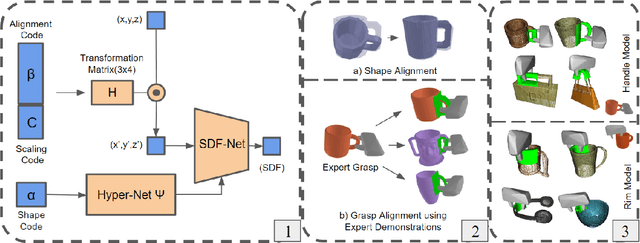


Objects we interact with and manipulate often share similar parts, such as handles, that allow us to transfer our actions flexibly due to their shared functionality. This work addresses the problem of transferring a grasp experience or a demonstration to a novel object that shares shape similarities with objects the robot has previously encountered. Existing approaches for solving this problem are typically restricted to a specific object category or a parametric shape. Our approach, however, can transfer grasps associated with implicit models of local surfaces shared across object categories. Specifically, we employ a single expert grasp demonstration to learn an implicit local surface representation model from a small dataset of object meshes. At inference time, this model is used to transfer grasps to novel objects by identifying the most geometrically similar surfaces to the one on which the expert grasp is demonstrated. Our model is trained entirely in simulation and is evaluated on simulated and real-world objects that are not seen during training. Evaluations indicate that grasp transfer to unseen object categories using this approach can be successfully performed both in simulation and real-world experiments. The simulation results also show that the proposed approach leads to better spatial precision and grasp accuracy compared to a baseline approach.
Neural Field Movement Primitives for Joint Modelling of Scenes and Motions
Aug 15, 2023



This paper presents a novel Learning from Demonstration (LfD) method that uses neural fields to learn new skills efficiently and accurately. It achieves this by utilizing a shared embedding to learn both scene and motion representations in a generative way. Our method smoothly maps each expert demonstration to a scene-motion embedding and learns to model them without requiring hand-crafted task parameters or large datasets. It achieves data efficiency by enforcing scene and motion generation to be smooth with respect to changes in the embedding space. At inference time, our method can retrieve scene-motion embeddings using test time optimization, and generate precise motion trajectories for novel scenes. The proposed method is versatile and can employ images, 3D shapes, and any other scene representations that can be modeled using neural fields. Additionally, it can generate both end-effector positions and joint angle-based trajectories. Our method is evaluated on tasks that require accurate motion trajectory generation, where the underlying task parametrization is based on object positions and geometric scene changes. Experimental results demonstrate that the proposed method outperforms the baseline approaches and generalizes to novel scenes. Furthermore, in real-world experiments, we show that our method can successfully model multi-valued trajectories, it is robust to the distractor objects introduced at inference time, and it can generate 6D motions.
Reward Conditioned Neural Movement Primitives for Population Based Variational Policy Optimization
Nov 09, 2020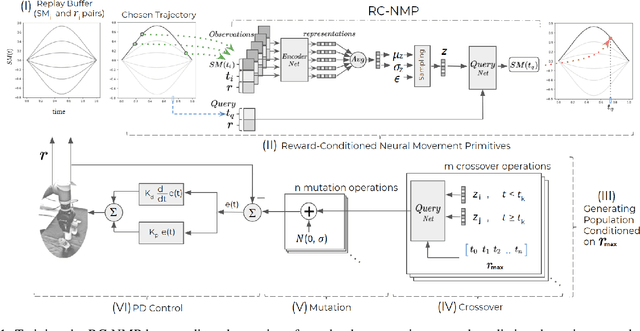
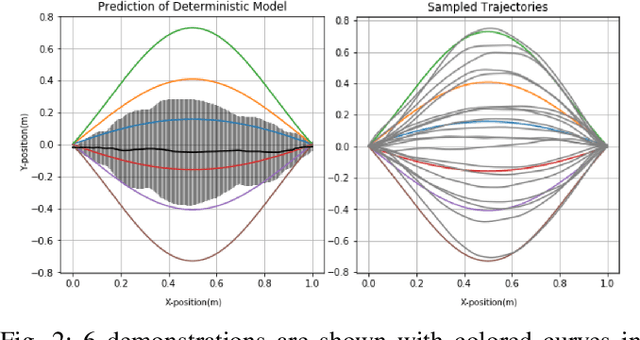
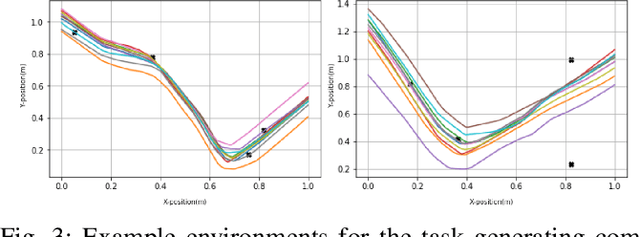
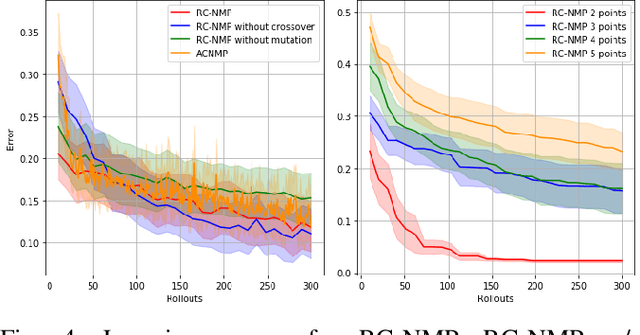
The aim of this paper is to study the reward based policy exploration problem in a supervised learning approach and enable robots to form complex movement trajectories in challenging reward settings and search spaces. For this, the experience of the robot, which can be bootstrapped from demonstrated trajectories, is used to train a novel Neural Processes-based deep network that samples from its latent space and generates the required trajectories given desired rewards. Our framework can generate progressively improved trajectories by sampling them from high reward landscapes, increasing the reward gradually. Variational inference is used to create a stochastic latent space to sample varying trajectories in generating population of trajectories given target rewards. We benefit from Evolutionary Strategies and propose a novel crossover operation, which is applied in the self-organized latent space of the individual policies, allowing blending of the individuals that might address different factors in the reward function. Using a number of tasks that require sequential reaching to multiple points or passing through gaps between objects, we showed that our method provides stable learning progress and significant sample efficiency compared to a number of state-of-the-art robotic reinforcement learning methods. Finally, we show the real-world suitability of our method through real robot execution involving obstacle avoidance.