 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Conditioned Neural Movement Primitives for Population Based Variational Policy Optimization
Paper and Code
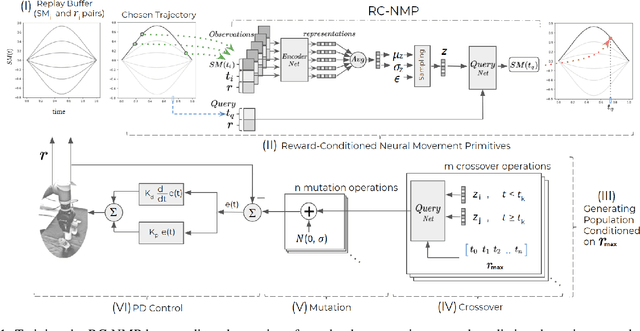
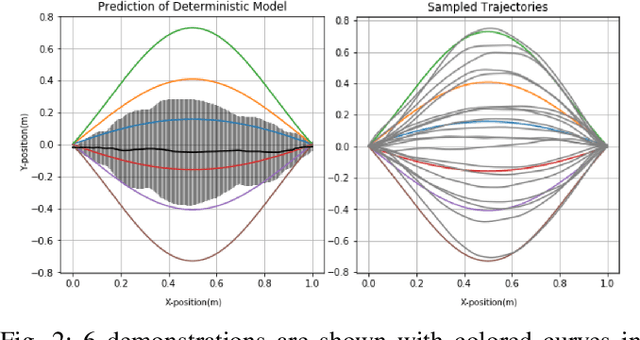
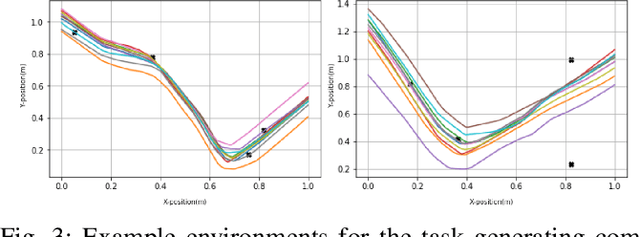
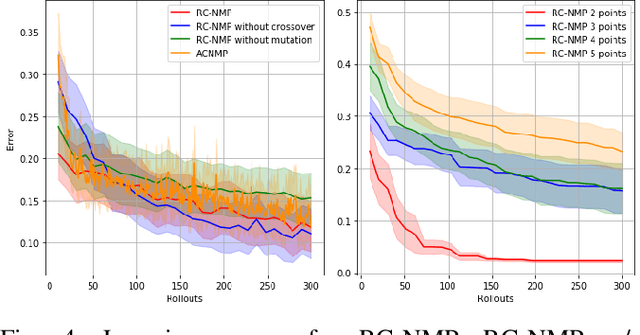
The aim of this paper is to study the reward based policy exploration problem in a supervised learning approach and enable robots to form complex movement trajectories in challenging reward settings and search spaces. For this, the experience of the robot, which can be bootstrapped from demonstrated trajectories, is used to train a novel Neural Processes-based deep network that samples from its latent space and generates the required trajectories given desired rewards. Our framework can generate progressively improved trajectories by sampling them from high reward landscapes, increasing the reward gradually. Variational inference is used to create a stochastic latent space to sample varying trajectories in generating population of trajectories given target rewards. We benefit from Evolutionary Strategies and propose a novel crossover operation, which is applied in the self-organized latent space of the individual policies, allowing blending of the individuals that might address different factors in the reward function. Using a number of tasks that require sequential reaching to multiple points or passing through gaps between objects, we showed that our method provides stable learning progress and significant sample efficiency compared to a number of state-of-the-art robotic reinforcement learning methods. Finally, we show the real-world suitability of our method through real robot execution involving obstacle avoidance.