 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Q-Networks for Value Function Factorizing in Multi-Agent Reinforcement Learning
May 30, 2022
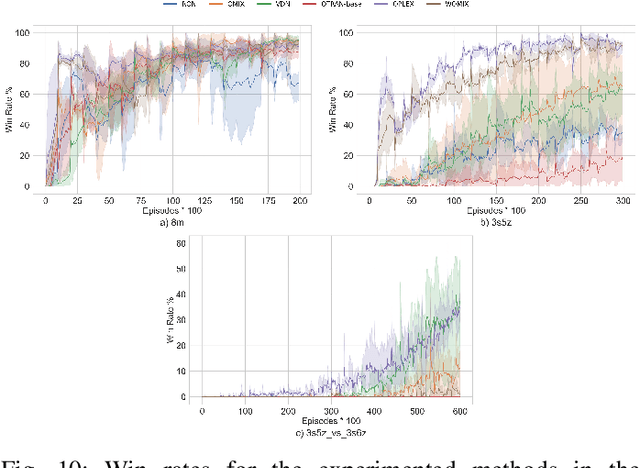
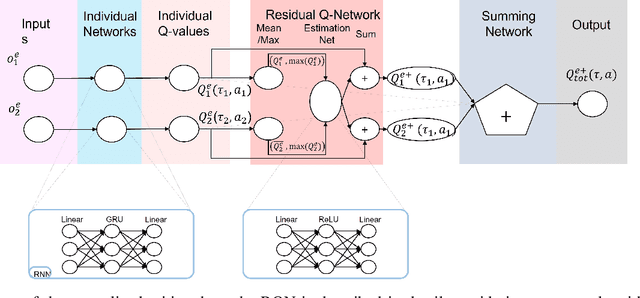

Multi-Agent Reinforcement Learning (MARL) is useful in many problems that require the cooperation and coordination of multiple agents. Learning optimal policies using reinforcement learning in a multi-agent setting can be very difficult as the number of agents increases. Recent solutions such as Value Decomposition Networks (VDN), QMIX, QTRAN and QPLEX adhere to the centralized training and decentralized execution scheme and perform factorization of the joint action-value functions. However, these methods still suffer from increased environmental complexity, and at times fail to converge in a stable manner. We propose a novel concept of Residual Q-Networks (RQNs) for MARL, which learns to transform the individual Q-value trajectories in a way that preserves the Individual-Global-Max criteria (IGM), but is more robust in factorizing action-value functions. The RQN acts as an auxiliary network that accelerates convergence and will become obsolete as the agents reach the training objectives. The performance of the proposed method is compared against several state-of-the-art techniques such as QPLEX, QMIX, QTRAN and VDN, in a range of multi-agent cooperative tasks. The results illustrate that the proposed method, in general, converges faster, with increased stability and shows robust performance in a wider family of environments. The improvements in results are more prominent in environments with severe punishments for non-cooperative behaviours and especially in the absence of complete state information during training time.
Adaptive Feature Processing for Robust Human Activity Recognition on a Novel Multi-Modal Dataset
Jan 09, 2019

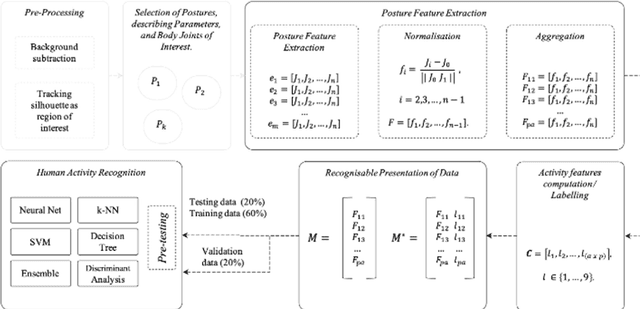

Human Activity Recognition (HAR) is a key building block of many emerging applications such as intelligent mobility, sports analytics, ambient-assisted living and human-robot interaction. With robust HAR, systems will become more human-aware, leading towards much safer and empathetic autonomous systems. While human pose detection has made significant progress with the dawn of deep convolutional neural networks (CNNs), the state-of-the-art research has almost exclusively focused on a single sensing modality, especially video. However, in safety critical applications it is imperative to utilize multiple sensor modalities for robust operation. To exploit the benefits of state-of-the-art machine learning techniques for HAR, it is extremely important to have multimodal datasets. In this paper, we present a novel, multi-modal sensor dataset that encompasses nine indoor activities, performed by 16 participants, and captured by four types of sensors that are commonly used in indoor applications and autonomous vehicles. This multimodal dataset is the first of its kind to be made openly available and can be exploited for many applications that require HAR, including sports analytics, healthcare assistance and indoor intelligent mobility. We propose a novel data preprocessing algorithm to enable adaptive feature extraction from the dataset to be utilized by different machine learning algorithms. Through rigorous experimental evaluations, this paper reviews the performance of machine learning approaches to posture recognition, and analyses the robustness of the algorithms. When performing HAR with the RGB-Depth data from our new dataset, machine learning algorithms such as a deep neural network reached a mean accuracy of up to 96.8% for classification across all stationary and dynamic activities
An Agent-based Modelling Framework for Driving Policy Learning in Connected and Autonomous Vehicles
Aug 23, 2018



Due to the complexity of the natural world, a programmer cannot foresee all possible situations, a connected and autonomous vehicle (CAV) will face during its operation, and hence, CAVs will need to learn to make decisions autonomously. Due to the sensing of its surroundings and information exchanged with other vehicles and road infrastructure, a CAV will have access to large amounts of useful data. While different control algorithms have been proposed for CAVs, the benefits brought about by connectedness of autonomous vehicles to other vehicles and to the infrastructure, and its implications on policy learning has not been investigated in literature. This paper investigates a data driven driving policy learning framework through an agent-based modelling approaches. The contributions of the paper are two-fold. A dynamic programming framework is proposed for in-vehicle policy learning with and without connectivity to neighboring vehicles. The simulation results indicate that while a CAV can learn to make autonomous decisions, vehicle-to-vehicle (V2V) communication of information improves this capability. Furthermore, to overcome the limitations of sensing in a CAV, the paper proposes a novel concept for infrastructure-led policy learning and communication with autonomous vehicles. In infrastructure-led policy learning, road-side infrastructure senses and captures successful vehicle maneuvers and learns an optimal policy from those temporal sequences, and when a vehicle approaches the road-side unit, the policy is communicated to the CAV. Deep-imitation learning methodology is proposed to develop such an infrastructure-led policy learning framework.
Robust Fusion of LiDAR and Wide-Angle Camera Data for Autonomous Mobile Robots
Aug 23, 2018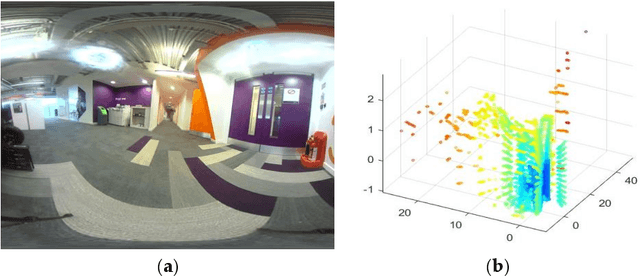

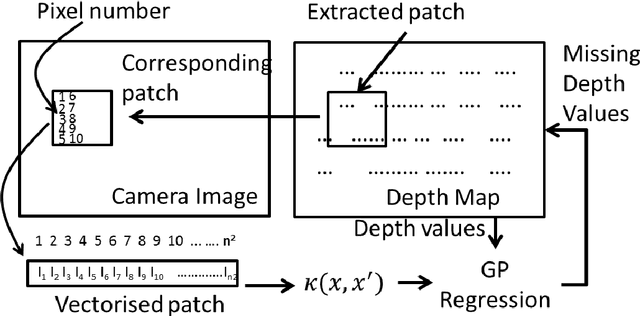
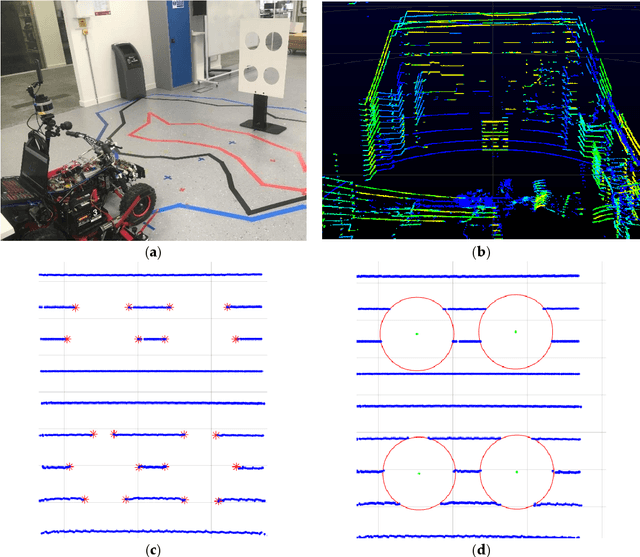
Autonomous robots that assist humans in day to day living tasks are becoming increasingly popular. Autonomous mobile robots operate by sensing and perceiving their surrounding environment to make accurate driving decisions. A combination of several different sensors such as LiDAR, radar, ultrasound sensors and cameras are utilized to sense the surrounding environment of autonomous vehicles. These heterogeneous sensors simultaneously capture various physical attributes of the environment. Such multimodality and redundancy of sensing need to be positively utilized for reliable and consistent perception of the environment through sensor data fusion. However, these multimodal sensor data streams are different from each other in many ways, such as temporal and spatial resolution, data format, and geometric alignment. For the subsequent perception algorithms to utilize the diversity offered by multimodal sensing, the data streams need to be spatially, geometrically and temporally aligned with each other. In this paper, we address the problem of fusing the outputs of a Light Detection and Ranging (LiDAR) scanner and a wide-angle monocular image sensor for free space detection. The outputs of LiDAR scanner and the image sensor are of different spatial resolutions and need to be aligned with each other. A geometrical model is used to spatially align the two sensor outputs, followed by a Gaussian Process (GP) regression-based resolution matching algorithm to interpolate the missing data with quantifiable uncertainty. The results indicate that the proposed sensor data fusion framework significantly aids the subsequent perception steps, as illustrated by the performance improvement of a uncertainty aware free space detection algorithm