 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Q-Networks for Value Function Factorizing in Multi-Agent Reinforcement Learning
May 30, 2022
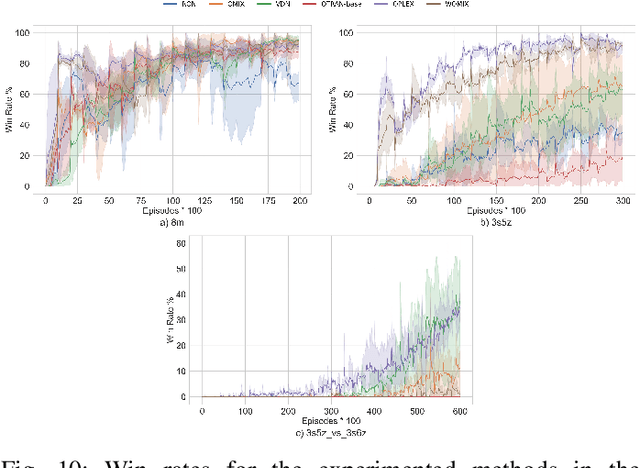
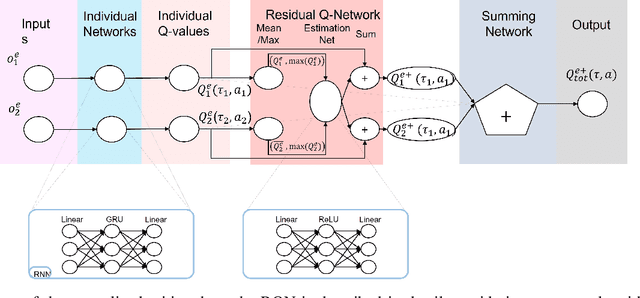

Multi-Agent Reinforcement Learning (MARL) is useful in many problems that require the cooperation and coordination of multiple agents. Learning optimal policies using reinforcement learning in a multi-agent setting can be very difficult as the number of agents increases. Recent solutions such as Value Decomposition Networks (VDN), QMIX, QTRAN and QPLEX adhere to the centralized training and decentralized execution scheme and perform factorization of the joint action-value functions. However, these methods still suffer from increased environmental complexity, and at times fail to converge in a stable manner. We propose a novel concept of Residual Q-Networks (RQNs) for MARL, which learns to transform the individual Q-value trajectories in a way that preserves the Individual-Global-Max criteria (IGM), but is more robust in factorizing action-value functions. The RQN acts as an auxiliary network that accelerates convergence and will become obsolete as the agents reach the training objectives. The performance of the proposed method is compared against several state-of-the-art techniques such as QPLEX, QMIX, QTRAN and VDN, in a range of multi-agent cooperative tasks. The results illustrate that the proposed method, in general, converges faster, with increased stability and shows robust performance in a wider family of environments. The improvements in results are more prominent in environments with severe punishments for non-cooperative behaviours and especially in the absence of complete state information during training time.