 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Pilot Contamination and Enabling IoT Scalability in Massive MIMO Systems
Oct 05, 2023Massive MIMO is expected to play an important role in the development of 5G networks. This paper addresses the issue of pilot contamination and scalability in massive MIMO systems. The current practice of reusing orthogonal pilot sequences in adjacent cells leads to difficulty in differentiating incoming inter- and intra-cell pilot sequences. One possible solution is to increase the number of orthogonal pilot sequences, which results in dedicating more space of coherence block to pilot transmission than data transmission. This, in turn, also hinders the scalability of massive MIMO systems, particularly in accommodating a large number of IoT devices within a cell. To overcome these challenges, this paper devises an innovative pilot allocation scheme based on the data transfer patterns of IoT devices. The scheme assigns orthogonal pilot sequences to clusters of devices instead of individual devices, allowing multiple devices to utilize the same pilot for periodically transmitting data. Moreover, we formulate the pilot assignment problem as a graph coloring problem and use the max k-cut graph partitioning approach to overcome the pilot contamination in a multicell massive MIMO system. The proposed scheme significantly improves the spectral efficiency and enables the scalability of massive MIMO systems; for instance, by using ten orthogonal pilot sequences, we are able to accommodate 200 devices with only a 12.5% omission rate.
Blockage Prediction for Mobile UE in RIS-assisted Wireless Networks: A Deep Learning Approach
Sep 22, 2022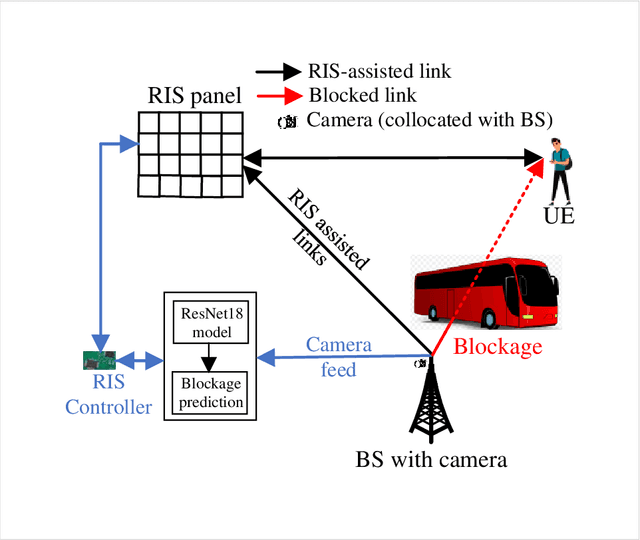
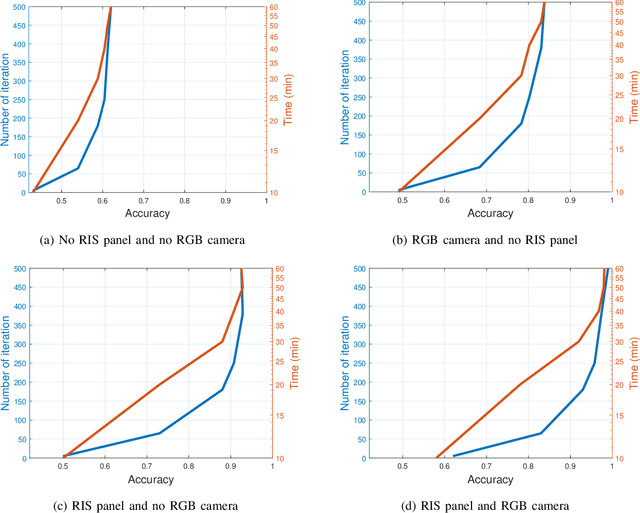
Due to significant blockage conditions in wireless networks, transmitted signals may considerably degrade before reaching the receiver. The reliability of the transmitted signals, therefore, may be critically problematic due to blockages between the communicating nodes. Thanks to the ability of Reconfigurable Intelligent Surfaces (RISs) to reflect the incident signals with different reflection angles, this may counter the blockage effect by optimally reflecting the transmit signals to receiving nodes, hence, improving the wireless network's performance. With this motivation, this paper formulates a RIS-aided wireless communication problem from a base station (BS) to a mobile user equipment (UE). The BS is equipped with an RGB camera. We use the RGB camera at the BS and the RIS panel to improve the system's performance while considering signal propagating through multiple paths and the Doppler spread for the mobile UE. First, the RGB camera is used to detect the presence of the UE with no blockage. When unsuccessful, the RIS-assisted gain takes over and is then used to detect if the UE is either "present but blocked" or "absent". The problem is determined as a ternary classification problem with the goal of maximizing the probability of UE communication blockage detection. We find the optimal solution for the probability of predicting the blockage status for a given RGB image and RIS-assisted data rate using a deep neural learning model. We employ the residual network 18-layer neural network model to find this optimal probability of blockage prediction. Extensive simulation results reveal that our proposed RIS panel-assisted model enhances the accuracy of maximization of the blockage prediction probability problem by over 38\% compared to the baseline scheme.
Reinforcement Learning Architectures: SAC, TAC, and ESAC
Apr 05, 2020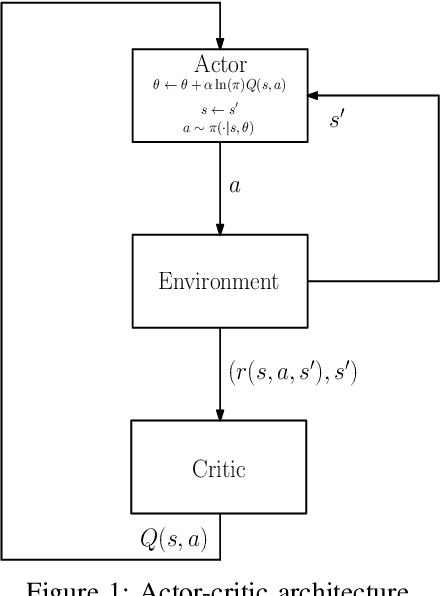
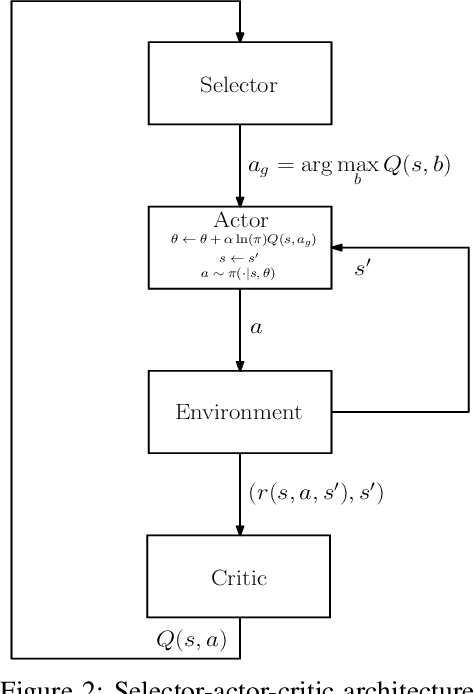
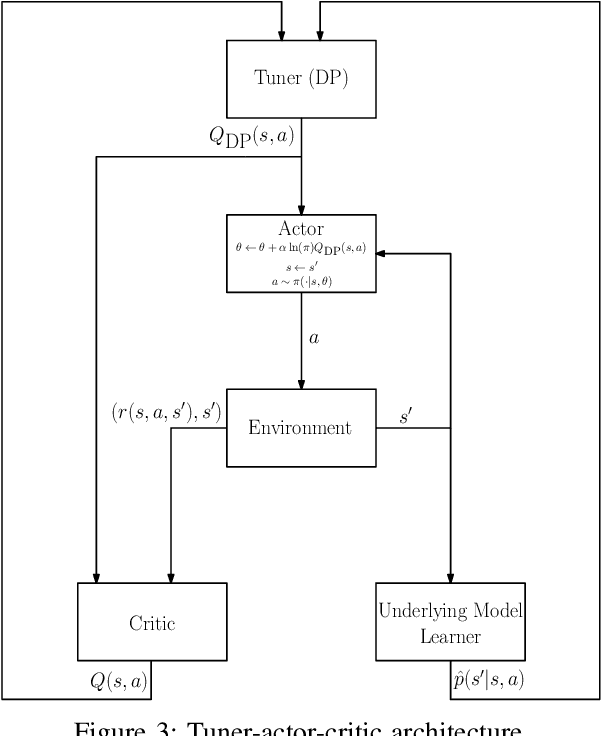

The trend is to implement intelligent agents capable of analyzing available information and utilize it efficiently. This work presents a number of reinforcement learning (RL) architectures; one of them is designed for intelligent agents. The proposed architectures are called selector-actor-critic (SAC), tuner-actor-critic (TAC), and estimator-selector-actor-critic (ESAC). These architectures are improved models of a well known architecture in RL called actor-critic (AC). In AC, an actor optimizes the used policy, while a critic estimates a value function and evaluate the optimized policy by the actor. SAC is an architecture equipped with an actor, a critic, and a selector. The selector determines the most promising action at the current state based on the last estimate from the critic. TAC consists of a tuner, a model-learner, an actor, and a critic. After receiving the approximated value of the current state-action pair from the critic and the learned model from the model-learner, the tuner uses the Bellman equation to tune the value of the current state-action pair. ESAC is proposed to implement intelligent agents based on two ideas, which are lookahead and intuition. Lookahead appears in estimating the values of the available actions at the next state, while the intuition appears in maximizing the probability of selecting the most promising action. The newly added elements are an underlying model learner, an estimator, and a selector. The model learner is used to approximate the underlying model. The estimator uses the approximated value function, the learned underlying model, and the Bellman equation to estimate the values of all actions at the next state. The selector is used to determine the most promising action at the next state, which will be used by the actor to optimize the used policy. Finally, the results show the superiority of ESAC compared with the other architectures.