 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Architectures: SAC, TAC, and ESAC
Paper and Code
Apr 05, 2020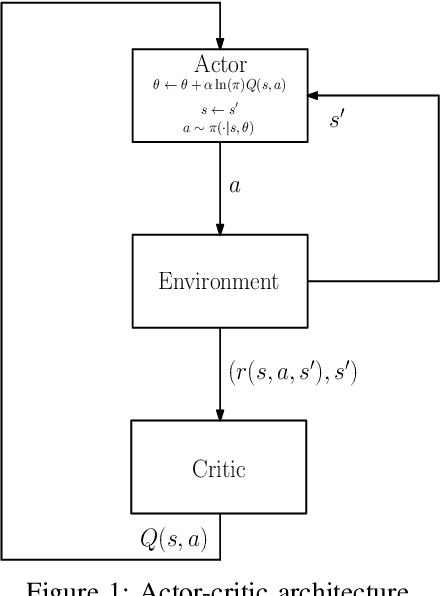
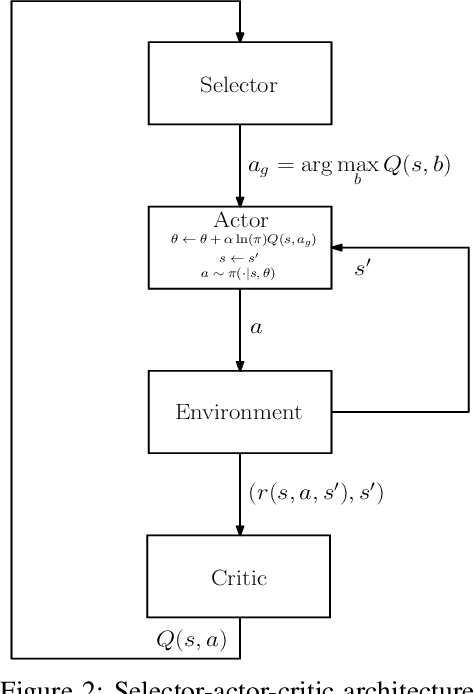
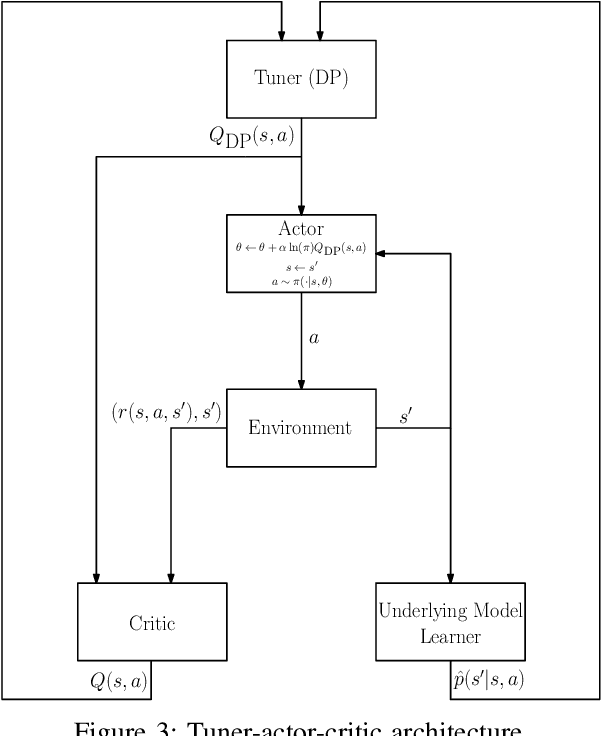

The trend is to implement intelligent agents capable of analyzing available information and utilize it efficiently. This work presents a number of reinforcement learning (RL) architectures; one of them is designed for intelligent agents. The proposed architectures are called selector-actor-critic (SAC), tuner-actor-critic (TAC), and estimator-selector-actor-critic (ESAC). These architectures are improved models of a well known architecture in RL called actor-critic (AC). In AC, an actor optimizes the used policy, while a critic estimates a value function and evaluate the optimized policy by the actor. SAC is an architecture equipped with an actor, a critic, and a selector. The selector determines the most promising action at the current state based on the last estimate from the critic. TAC consists of a tuner, a model-learner, an actor, and a critic. After receiving the approximated value of the current state-action pair from the critic and the learned model from the model-learner, the tuner uses the Bellman equation to tune the value of the current state-action pair. ESAC is proposed to implement intelligent agents based on two ideas, which are lookahead and intuition. Lookahead appears in estimating the values of the available actions at the next state, while the intuition appears in maximizing the probability of selecting the most promising action. The newly added elements are an underlying model learner, an estimator, and a selector. The model learner is used to approximate the underlying model. The estimator uses the approximated value function, the learned underlying model, and the Bellman equation to estimate the values of all actions at the next state. The selector is used to determine the most promising action at the next state, which will be used by the actor to optimize the used policy. Finally, the results show the superiority of ESAC compared with the other architectures.