 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Positive-Negative Prototype Approach to Integrated Prototypical Discriminative Learning
Jan 05, 2025



This paper proposes a novel Deep Positive-Negative Prototype (DPNP) model that combines prototype-based learning (PbL) with discriminative methods to improve class compactness and separability in deep neural networks. While PbL traditionally emphasizes interpretability by classifying samples based on their similarity to representative prototypes, it struggles with creating optimal decision boundaries in complex scenarios. Conversely, discriminative methods effectively separate classes but often lack intuitive interpretability. Toward exploiting advantages of these two approaches, the suggested DPNP model bridges between them by unifying class prototypes with weight vectors, thereby establishing a structured latent space that enables accurate classification using interpretable prototypes alongside a properly learned feature representation. Based on this central idea of unified prototype-weight representation, Deep Positive Prototype (DPP) is formed in the latent space as a representative for each class using off-the-shelf deep networks as feature extractors. Then, rival neighboring class DPPs are treated as implicit negative prototypes with repulsive force in DPNP, which push away DPPs from each other. This helps to enhance inter-class separation without the need for any extra parameters. Hence, through a novel loss function that integrates cross-entropy, prototype alignment, and separation terms, DPNP achieves well-organized feature space geometry, maximizing intra-class compactness and inter-class margins. We show that DPNP can organize prototypes in nearly regular positions within feature space, such that it is possible to achieve competitive classification accuracy even in much lower-dimensional feature spaces. Experimental results on several datasets demonstrate that DPNP outperforms state-of-the-art models, while using smaller networks.
Deep multi-prototype capsule networks
Apr 23, 2024Capsule networks are a type of neural network that identify image parts and form the instantiation parameters of a whole hierarchically. The goal behind the network is to perform an inverse computer graphics task, and the network parameters are the mapping weights that transform parts into a whole. The trainability of capsule networks in complex data with high intra-class or intra-part variation is challenging. This paper presents a multi-prototype architecture for guiding capsule networks to represent the variations in the image parts. To this end, instead of considering a single capsule for each class and part, the proposed method employs several capsules (co-group capsules), capturing multiple prototypes of an object. In the final layer, co-group capsules compete, and their soft output is considered the target for a competitive cross-entropy loss. Moreover, in the middle layers, the most active capsules map to the next layer with a shared weight among the co-groups. Consequently, due to the reduction in parameters, implicit weight-sharing makes it possible to have more deep capsule network layers. The experimental results on MNIST, SVHN, C-Cube, CEDAR, MCYT, and UTSig datasets reveal that the proposed model outperforms others regarding image classification accuracy.
Prototype-based interpretation of the functionality of neurons in winner-take-all neural networks
Aug 20, 2020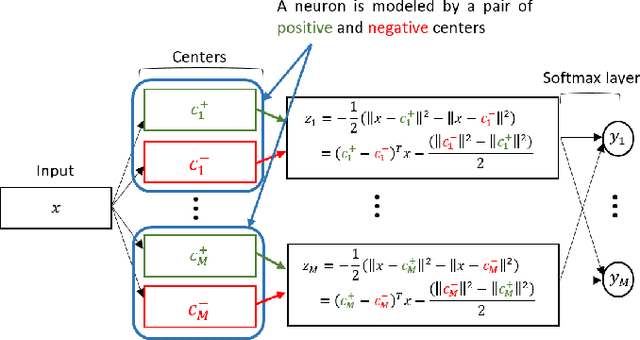

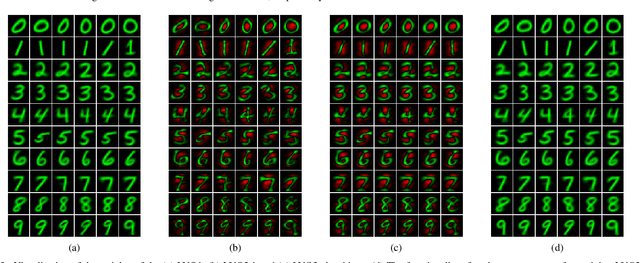

Prototype-based learning (PbL) using a winner-take-all (WTA) network based on minimum Euclidean distance (ED-WTA) is an intuitive approach to multiclass classification. By constructing meaningful class centers, PbL provides higher interpretability and generalization than hyperplane-based learning (HbL) methods based on maximum Inner Product (IP-WTA) and can efficiently detect and reject samples that do not belong to any classes. In this paper, we first prove the equivalence of IP-WTA and ED-WTA from a representational point of view. Then, we show that naively using this equivalence leads to unintuitive ED-WTA networks in which the centers have high distances to data that they represent. We propose $\pm$ED-WTA which models each neuron with two prototypes: one positive prototype representing samples that are modeled by this neuron and a negative prototype representing the samples that are erroneously won by that neuron during training. We propose a novel training algorithm for the $\pm$ED-WTA network, which cleverly switches between updating the positive and negative prototypes and is essential to the emergence of interpretable prototypes. Unexpectedly, we observed that the negative prototype of each neuron is indistinguishably similar to the positive one. The rationale behind this observation is that the training data that are mistaken with a prototype are indeed similar to it. The main finding of this paper is this interpretation of the functionality of neurons as computing the difference between the distances to a positive and a negative prototype, which is in agreement with the BCM theory. In our experiments, we show that the proposed $\pm$ED-WTA method constructs highly interpretable prototypes that can be successfully used for detecting outlier and adversarial examples.
WSMN: An optimized multipurpose blind watermarking in Shearlet domain using MLP and NSGA-II
May 07, 2020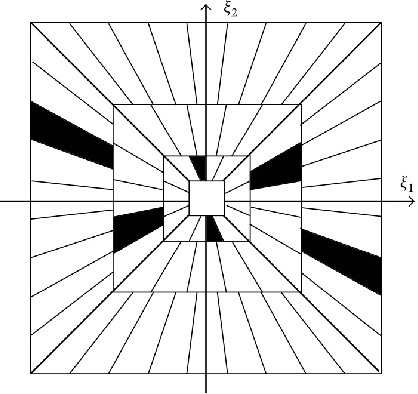
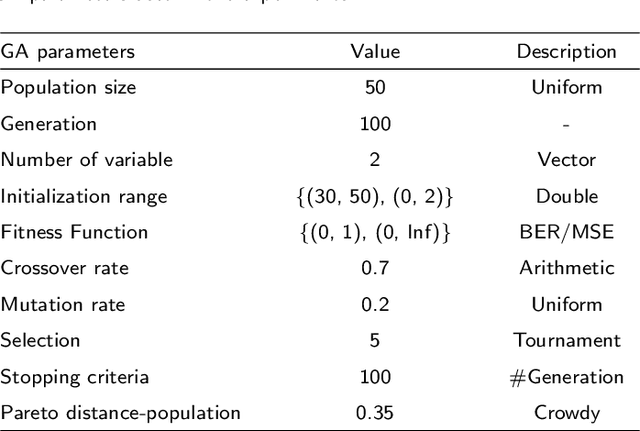

Digital watermarking is a remarkable issue in the field of information security to avoid the misuse of images in multimedia networks. Although access to unauthorized persons can be prevented through cryptography, it cannot be simultaneously used for copyright protection or content authentication with the preservation of image integrity. Hence, this paper presents an optimized multipurpose blind watermarking in Shearlet domain with the help of smart algorithms including MLP and NSGA-II. In this method, four copies of the robust copyright logo are embedded in the approximate coefficients of Shearlet by using an effective quantization technique. Furthermore, an embedded random sequence as a semi-fragile authentication mark is effectively extracted from details by the neural network. Due to performing an effective optimization algorithm for selecting optimum embedding thresholds, and also distinguishing the texture of blocks, the imperceptibility and robustness have been preserved. The experimental results reveal the superiority of the scheme with regard to the quality of watermarked images and robustness against hybrid attacks over other state-of-the-art schemes. The average PSNR and SSIM of the dual watermarked images are 38 dB and 0.95, respectively; Besides, it can effectively extract the copyright logo and locates forgery regions under severe attacks with satisfactory accuracy.
Salient Object Detection in Video using Deep Non-Local Neural Networks
Oct 16, 2018



Detection of salient objects in image and video is of great importance in many computer vision applications. In spite of the fact that the state of the art in saliency detection for still images has been changed substantially over the last few years, there have been few improvements in video saliency detection. This paper investigates the use of recently introduced non-local neural networks in video salient object detection. Non-local neural networks are applied to capture global dependencies and hence determine the salient objects. The effect of non-local operations is studied separately on static and dynamic saliency detection in order to exploit both appearance and motion features. A novel deep non-local neural network architecture is introduced for video salient object detection and tested on two well-known datasets DAVIS and FBMS. The experimental results show that the proposed algorithm outperforms state-of-the-art video saliency detection methods.
Training LDCRF model on unsegmented sequences using Connectionist Temporal Classification
Sep 06, 2016
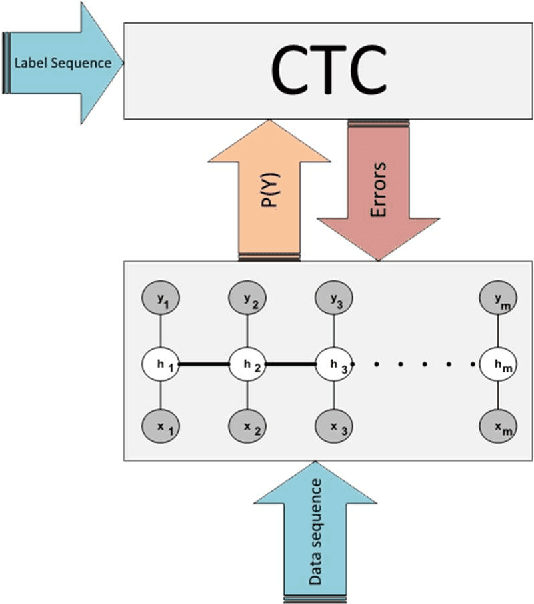

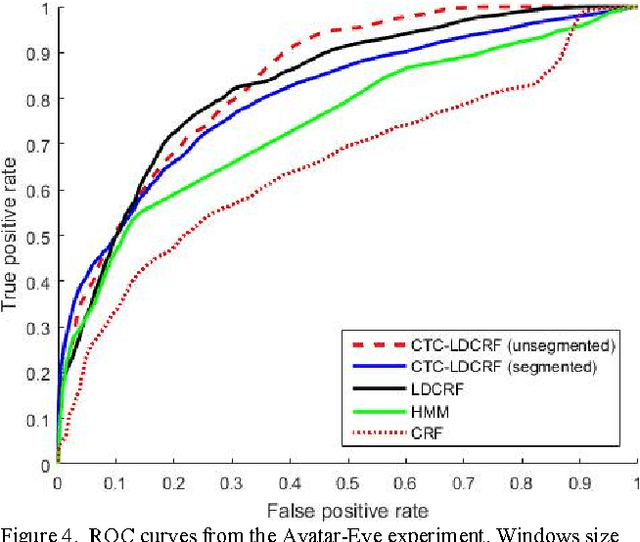
Many machine learning problems such as speech recognition, gesture recognition, and handwriting recognition are concerned with simultaneous segmentation and labeling of sequence data. Latent-dynamic conditional random field (LDCRF) is a well-known discriminative method that has been successfully used for this task. However, LDCRF can only be trained with pre-segmented data sequences in which the label of each frame is available apriori. In the realm of neural networks, the invention of connectionist temporal classification (CTC) made it possible to train recurrent neural networks on unsegmented sequences with great success. In this paper, we use CTC to train an LDCRF model on unsegmented sequences. Experimental results on two gesture recognition tasks show that the proposed method outperforms LDCRFs, hidden Markov models, and conditional random fields.