 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Generative AI Design Space through Structured Prompting and Multimodal Interfaces
Apr 22, 2025Text-based prompting remains the predominant interaction paradigm in generative AI, yet it often introduces friction for novice users such as small business owners (SBOs), who struggle to articulate creative goals in domain-specific contexts like advertising. Through a formative study with six SBOs in the United Kingdom, we identify three key challenges: difficulties in expressing brand intuition through prompts, limited opportunities for fine-grained adjustment and refinement during and after content generation, and the frequent production of generic content that lacks brand specificity. In response, we present ACAI (AI Co-Creation for Advertising and Inspiration), a multimodal generative AI tool designed to support novice designers by moving beyond traditional prompt interfaces. ACAI features a structured input system composed of three panels: Branding, Audience and Goals, and the Inspiration Board. These inputs allow users to convey brand-relevant context and visual preferences. This work contributes to HCI research on generative systems by showing how structured interfaces can foreground user-defined context, improve alignment, and enhance co-creative control in novice creative workflows.
ACAI for SBOs: AI Co-creation for Advertising and Inspiration for Small Business Owners
Mar 09, 2025



Small business owners (SBOs) often lack the resources and design experience needed to produce high-quality advertisements. To address this, we developed ACAI (AI Co-Creation for Advertising and Inspiration), an GenAI-powered multimodal advertisement creation tool, and conducted a user study with 16 SBOs in London to explore their perceptions of and interactions with ACAI in advertisement creation. Our findings reveal that structured inputs enhance user agency and control while improving AI outputs by facilitating better brand alignment, enhancing AI transparency, and offering scaffolding that assists novice designers, such as SBOs, in formulating prompts. We also found that ACAI's multimodal interface bridges the design skill gap for SBOs with a clear advertisement vision, but who lack the design jargon necessary for effective prompting. Building on our findings, we propose three capabilities: contextual intelligence, adaptive interactions, and data management, with corresponding design recommendations to advance the co-creative attributes of AI-mediated design tools.
LLMs achieve adult human performance on higher-order theory of mind tasks
May 29, 2024This paper examines the extent to which large language models (LLMs) have developed higher-order theory of mind (ToM); the human ability to reason about multiple mental and emotional states in a recursive manner (e.g. I think that you believe that she knows). This paper builds on prior work by introducing a handwritten test suite -- Multi-Order Theory of Mind Q&A -- and using it to compare the performance of five LLMs to a newly gathered adult human benchmark. We find that GPT-4 and Flan-PaLM reach adult-level and near adult-level performance on ToM tasks overall, and that GPT-4 exceeds adult performance on 6th order inferences. Our results suggest that there is an interplay between model size and finetuning for the realisation of ToM abilities, and that the best-performing LLMs have developed a generalised capacity for ToM. Given the role that higher-order ToM plays in a wide range of cooperative and competitive human behaviours, these findings have significant implications for user-facing LLM applications.
Active Learning of Inverse Models with Intrinsically Motivated Goal Exploration in Robots
Jan 21, 2013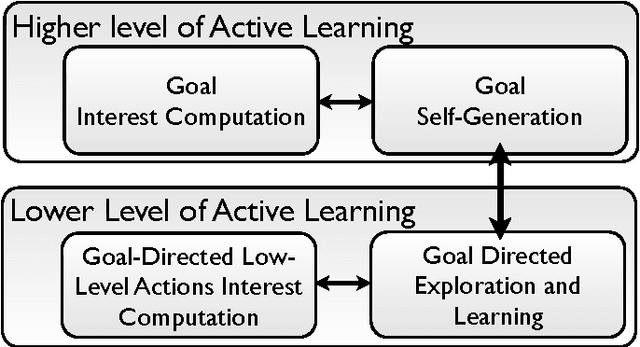
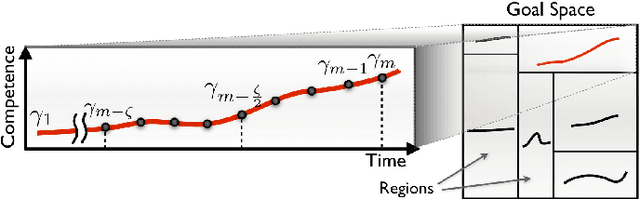
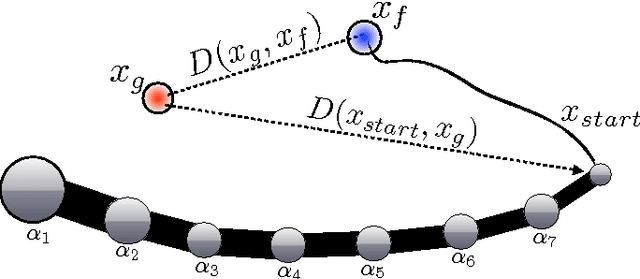
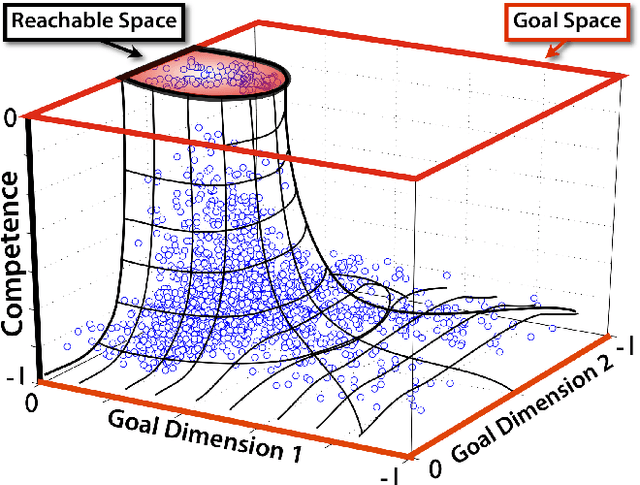
We introduce the Self-Adaptive Goal Generation - Robust Intelligent Adaptive Curiosity (SAGG-RIAC) architecture as an intrinsi- cally motivated goal exploration mechanism which allows active learning of inverse models in high-dimensional redundant robots. This allows a robot to efficiently and actively learn distributions of parameterized motor skills/policies that solve a corresponding distribution of parameterized tasks/goals. The architecture makes the robot sample actively novel parameterized tasks in the task space, based on a measure of competence progress, each of which triggers low-level goal-directed learning of the motor policy pa- rameters that allow to solve it. For both learning and generalization, the system leverages regression techniques which allow to infer the motor policy parameters corresponding to a given novel parameterized task, and based on the previously learnt correspondences between policy and task parameters. We present experiments with high-dimensional continuous sensorimotor spaces in three different robotic setups: 1) learning the inverse kinematics in a highly-redundant robotic arm, 2) learning omnidirectional locomotion with motor primitives in a quadruped robot, 3) an arm learning to control a fishing rod with a flexible wire. We show that 1) exploration in the task space can be a lot faster than exploration in the actuator space for learning inverse models in redundant robots; 2) selecting goals maximizing competence progress creates developmental trajectories driving the robot to progressively focus on tasks of increasing complexity and is statistically significantly more efficient than selecting tasks randomly, as well as more efficient than different standard active motor babbling methods; 3) this architecture allows the robot to actively discover which parts of its task space it can learn to reach and which part it cannot.
Bootstrapping Intrinsically Motivated Learning with Human Demonstrations
Dec 08, 2011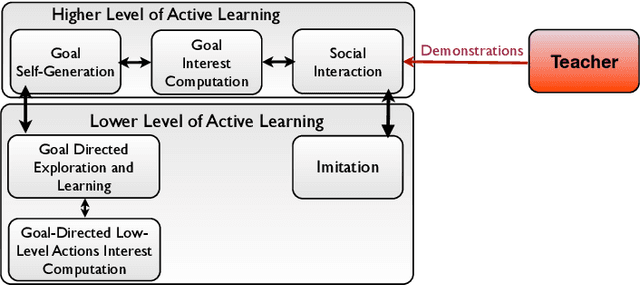
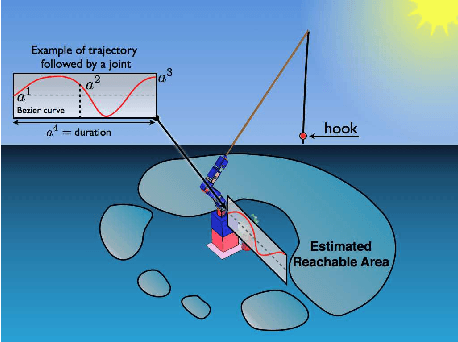
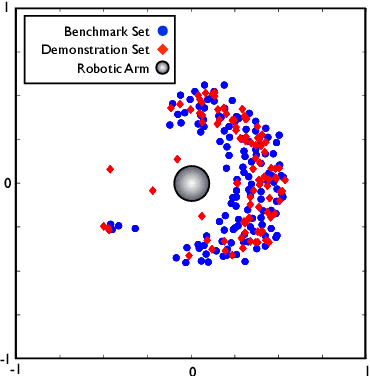
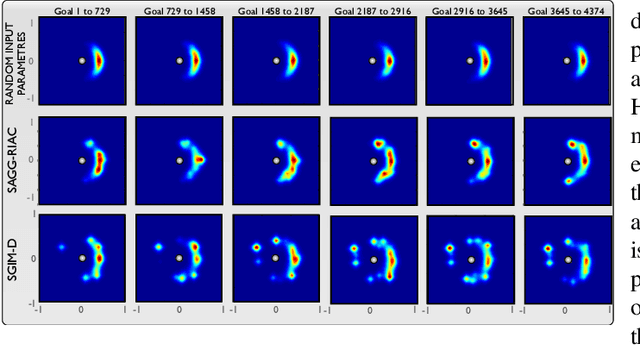
This paper studies the coupling of internally guided learning and social interaction, and more specifically the improvement owing to demonstrations of the learning by intrinsic motivation. We present Socially Guided Intrinsic Motivation by Demonstration (SGIM-D), an algorithm for learning in continuous, unbounded and non-preset environments. After introducing social learning and intrinsic motivation, we describe the design of our algorithm, before showing through a fishing experiment that SGIM-D efficiently combines the advantages of social learning and intrinsic motivation to gain a wide repertoire while being specialised in specific subspaces.
Constraining the Size Growth of the Task Space with Socially Guided Intrinsic Motivation using Demonstrations
Nov 29, 2011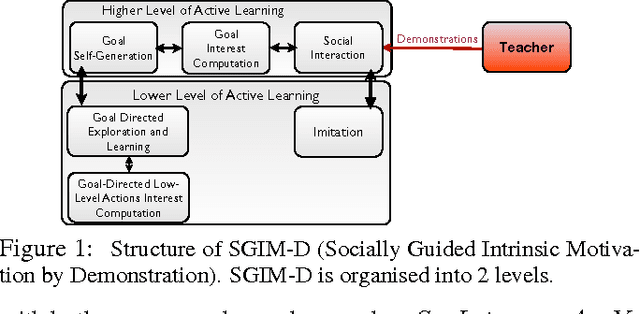
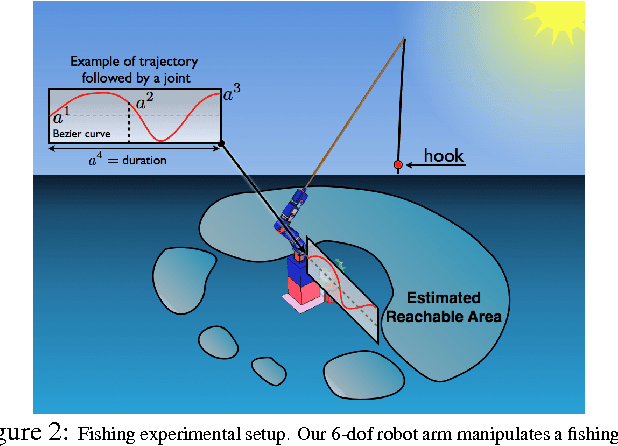
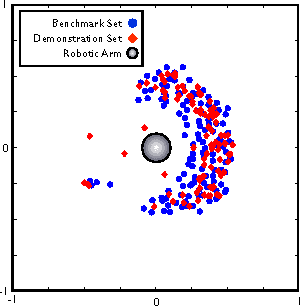
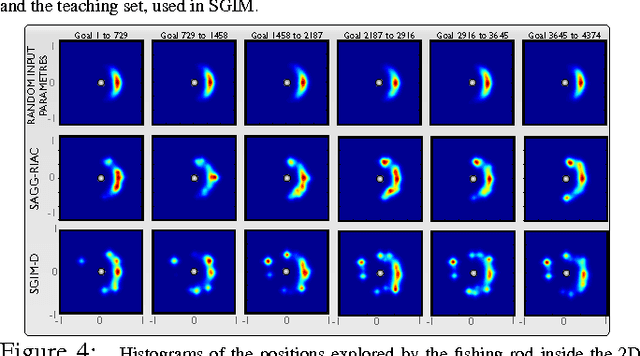
This paper presents an algorithm for learning a highly redundant inverse model in continuous and non-preset environments. Our Socially Guided Intrinsic Motivation by Demonstrations (SGIM-D) algorithm combines the advantages of both social learning and intrinsic motivation, to specialise in a wide range of skills, while lessening its dependence on the teacher. SGIM-D is evaluated on a fishing skill learning experiment.