 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCTA-Based Biomarker Characterization in nAMD
Jan 25, 2026We aim to enhance ophthalmologists' decision-making when diagnosing the Neovascular Age-Related Macular Degeneration (nAMD). We developed three tools to analyze Optical Coherence Tomography Angiography images: (1) extracting biomarkers such as mCNV area and vessel density using image processing; (2) generating a 3D visualization of the neovascularization for a better view of the affected regions; and (3) applying an ensemble of three white box machine learning algorithms (decision tree, support vector machines and DL-Learner) for nAMD diagnosis. The learned expressions reached 100% accuracy for the training data and 68% accuracy in testing. The main advantage is that all the learned models white-box, which ensures explainability and transparency, allowing clinicians to better understand the decision-making process.
Combining Deep Learning and Explainable AI for Toxicity Prediction of Chemical Compounds
Oct 26, 2025The task here is to predict the toxicological activity of chemical compounds based on the Tox21 dataset, a benchmark in computational toxicology. After a domain-specific overview of chemical toxicity, we discuss current computational strategies, focusing on machine learning and deep learning. Several architectures are compared in terms of performance, robustness, and interpretability. This research introduces a novel image-based pipeline based on DenseNet121, which processes 2D graphical representations of chemical structures. Additionally, we employ Grad-CAM visualizations, an explainable AI technique, to interpret the model's predictions and highlight molecular regions contributing to toxicity classification. The proposed architecture achieves competitive results compared to traditional models, demonstrating the potential of deep convolutional networks in cheminformatics. Our findings emphasize the value of combining image-based representations with explainable AI methods to improve both predictive accuracy and model transparency in toxicology.
MCP-Orchestrated Multi-Agent System for Automated Disinformation Detection
Aug 13, 2025The large spread of disinformation across digital platforms creates significant challenges to information integrity. This paper presents a multi-agent system that uses relation extraction to detect disinformation in news articles, focusing on titles and short text snippets. The proposed Agentic AI system combines four agents: (i) a machine learning agent (logistic regression), (ii) a Wikipedia knowledge check agent (which relies on named entity recognition), (iii) a coherence detection agent (using LLM prompt engineering), and (iv) a web-scraped data analyzer that extracts relational triplets for fact checking. The system is orchestrated via the Model Context Protocol (MCP), offering shared context and live learning across components. Results demonstrate that the multi-agent ensemble achieves 95.3% accuracy with an F1 score of 0.964, significantly outperforming individual agents and traditional approaches. The weighted aggregation method, mathematically derived from individual agent misclassification rates, proves superior to algorithmic threshold optimization. The modular architecture makes the system easily scalable, while also maintaining details of the decision processes.
Measuring reasoning capabilities of ChatGPT
Oct 08, 2023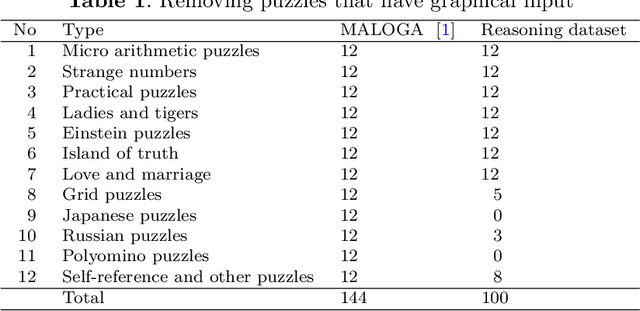


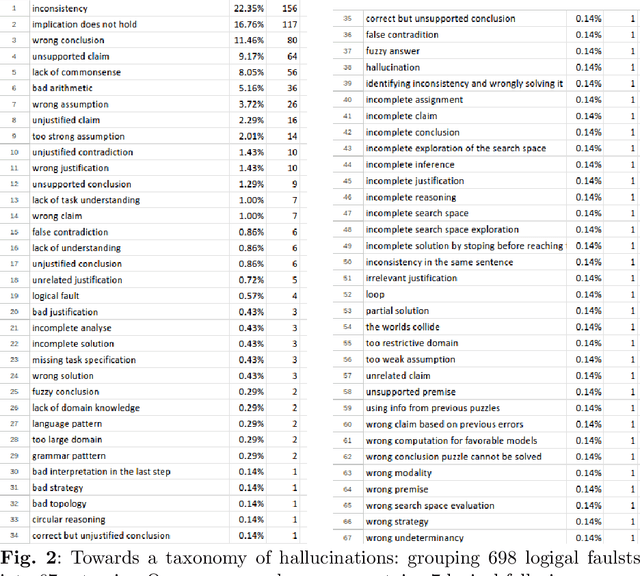
I shall quantify the logical faults generated by ChatGPT when applied to reasoning tasks. For experiments, I use the 144 puzzles from the library \url{https://users.utcluj.ro/~agroza/puzzles/maloga}~\cite{groza:fol}. The library contains puzzles of various types, including arithmetic puzzles, logical equations, Sudoku-like puzzles, zebra-like puzzles, truth-telling puzzles, grid puzzles, strange numbers, or self-reference puzzles. The correct solutions for these puzzles were checked using the theorem prover Prover9~\cite{mccune2005release} and the finite models finder Mace4~\cite{mccune2003mace4} based on human-modelling in Equational First Order Logic. A first output of this study is the benchmark of 100 logical puzzles. For this dataset ChatGPT provided both correct answer and justification for 7\% only. %, while BARD for 5\%. Since the dataset seems challenging, the researchers are invited to test the dataset on more advanced or tuned models than ChatGPT3.5 with more crafted prompts. A second output is the classification of reasoning faults conveyed by ChatGPT. This classification forms a basis for a taxonomy of reasoning faults generated by large language models. I have identified 67 such logical faults, among which: inconsistencies, implication does not hold, unsupported claim, lack of commonsense, wrong justification. The 100 solutions generated by ChatGPT contain 698 logical faults. That is on average, 7 fallacies for each reasoning task. A third ouput is the annotated answers of the ChatGPT with the corresponding logical faults. Each wrong statement within the ChatGPT answer was manually annotated, aiming to quantify the amount of faulty text generated by the language model. On average, 26.03\% from the generated text was a logical fault.
Forest Mixing: investigating the impact of multiple search trees and a shared refinements pool on ontology learning
Sep 29, 2023



We aim at development white-box machine learning algorithms. We focus here on algorithms for learning axioms in description logic. We extend the Class Expression Learning for Ontology Engineering (CELOE) algorithm contained in the DL-Learner tool. The approach uses multiple search trees and a shared pool of refinements in order to split the search space in smaller subspaces. We introduce the conjunction operation of best class expressions from each tree, keeping the results which give the most information. The aim is to foster exploration from a diverse set of starting classes and to streamline the process of finding class expressions in ontologies. %, particularly in large search spaces. The current implementation and settings indicated that the Forest Mixing approach did not outperform the traditional CELOE. Despite these results, the conceptual proposal brought forward by this approach may stimulate future improvements in class expression finding in ontologies. % and influence. % the way we traverse search spaces in general.
Brave new world: Artificial Intelligence in teaching and learning
Sep 27, 2023
We exemplify how Large Language Models are used in both teaching and learning. We also discuss the AI incidents that have already occurred in the education domain, and we argue for the urgent need to introduce AI policies in universities and for the ongoing strategies to regulate AI. Regarding policy for AI, our view is that each institution should have a policy for AI in teaching and learning. This is important from at least twofolds: (i) to raise awareness on the numerous educational tools that can both positively and negatively affect education; (ii) to minimise the risk of AI incidents in education.
Formalising Natural Language Quantifiers for Human-Robot Interactions
Aug 25, 2023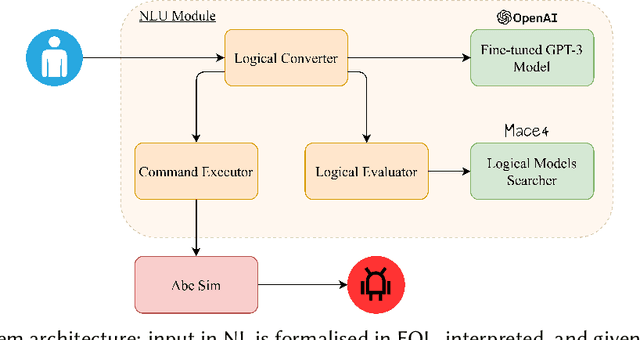


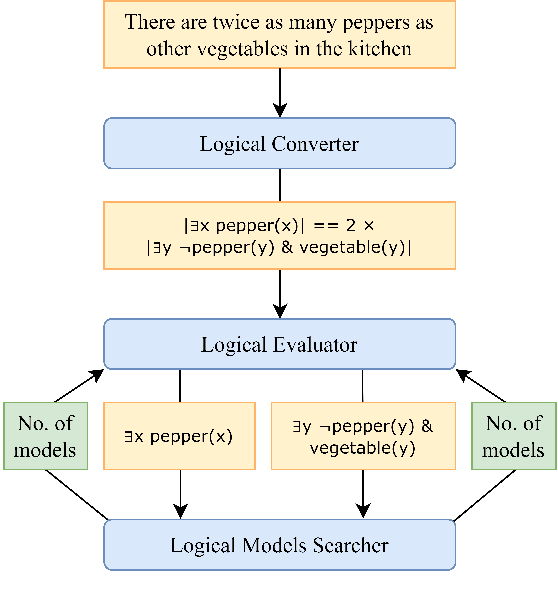
We present a method for formalising quantifiers in natural language in the context of human-robot interactions. The solution is based on first-order logic extended with capabilities to represent the cardinality of variables, operating similarly to generalised quantifiers. To demonstrate the method, we designed an end-to-end system able to receive input as natural language, convert it into a formal logical representation, evaluate it, and return a result or send a command to a simulated robot.
Case Study: Using AI-Assisted Code Generation In Mobile Teams
Aug 09, 2023The aim of this study is to evaluate the performance of AI-assisted programming in actual mobile development teams that are focused on native mobile languages like Kotlin and Swift. The extensive case study involves 16 participants and 2 technical reviewers, from a software development department designed to understand the impact of using LLMs trained for code generation in specific phases of the team, more specifically, technical onboarding and technical stack switch. The study uses technical problems dedicated to each phase and requests solutions from the participants with and without using AI-Code generators. It measures time, correctness, and technical integration using ReviewerScore, a metric specific to the paper and extracted from actual industry standards, the code reviewers of merge requests. The output is converted and analyzed together with feedback from the participants in an attempt to determine if using AI-assisted programming tools will have an impact on getting developers onboard in a project or helping them with a smooth transition between the two native development environments of mobile development, Android and iOS. The study was performed between May and June 2023 with members of the mobile department of a software development company based in Cluj-Napoca, with Romanian ownership and management.
Interleaving GANs with knowledge graphs to support design creativity for book covers
Aug 03, 2023



An attractive book cover is important for the success of a book. In this paper, we apply Generative Adversarial Networks (GANs) to the book covers domain, using different methods for training in order to obtain better generated images. We interleave GANs with knowledge graphs to alter the input title to obtain multiple possible options for any given title, which are then used as an augmented input to the generator. Finally, we use the discriminator obtained during the training phase to select the best images generated with new titles. Our method performed better at generating book covers than previous attempts, and the knowledge graph gives better options to the book author or editor compared to using GANs alone.
Detecting diabetic retinopathy severity through fundus images using an ensemble of classifiers
Jul 31, 2023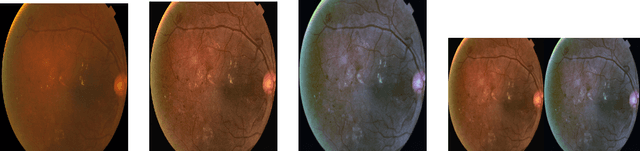
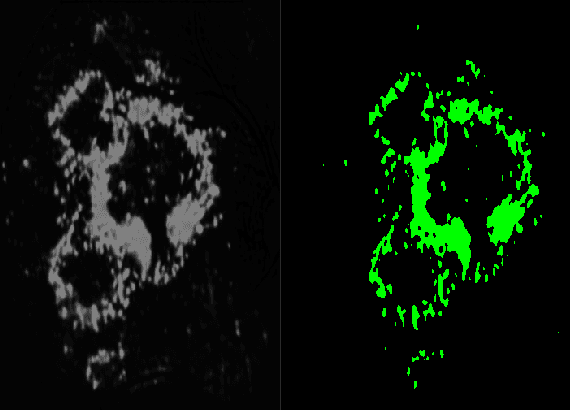
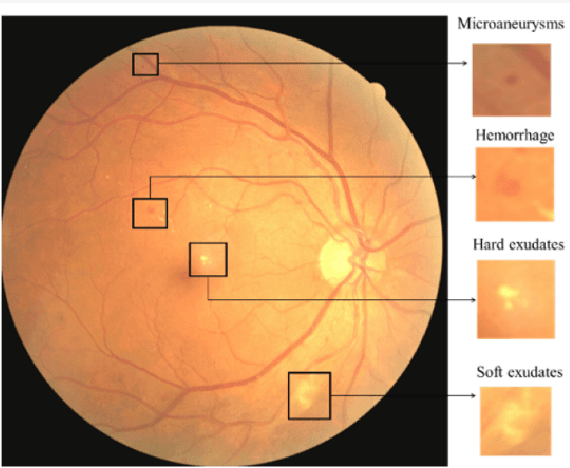
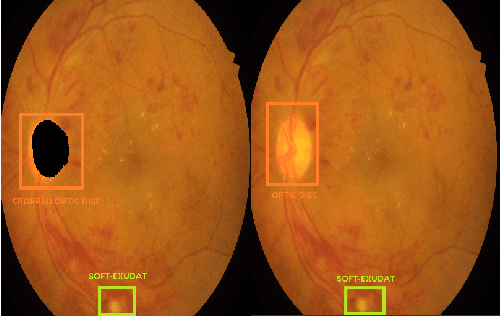
Diabetic retinopathy is an ocular condition that affects individuals with diabetes mellitus. It is a common complication of diabetes that can impact the eyes and lead to vision loss. One method for diagnosing diabetic retinopathy is the examination of the fundus of the eye. An ophthalmologist examines the back part of the eye, including the retina, optic nerve, and the blood vessels that supply the retina. In the case of diabetic retinopathy, the blood vessels in the retina deteriorate and can lead to bleeding, swelling, and other changes that affect vision. We proposed a method for detecting diabetic diabetic severity levels. First, a set of data-prerpocessing is applied to available data: adaptive equalisation, color normalisation, Gaussian filter, removal of the optic disc and blood vessels. Second, we perform image segmentation for relevant markers and extract features from the fundus images. Third, we apply an ensemble of classifiers and we assess the trust in the system.