 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring reasoning capabilities of ChatGPT
Paper and Code
Oct 08, 2023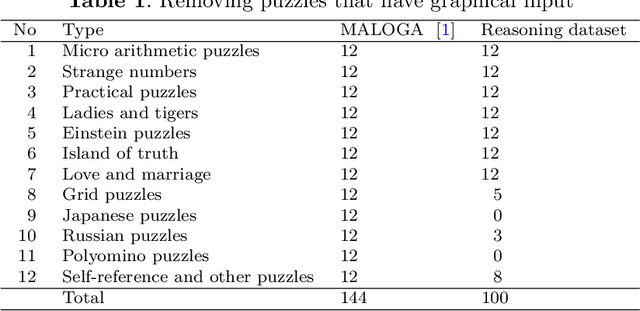


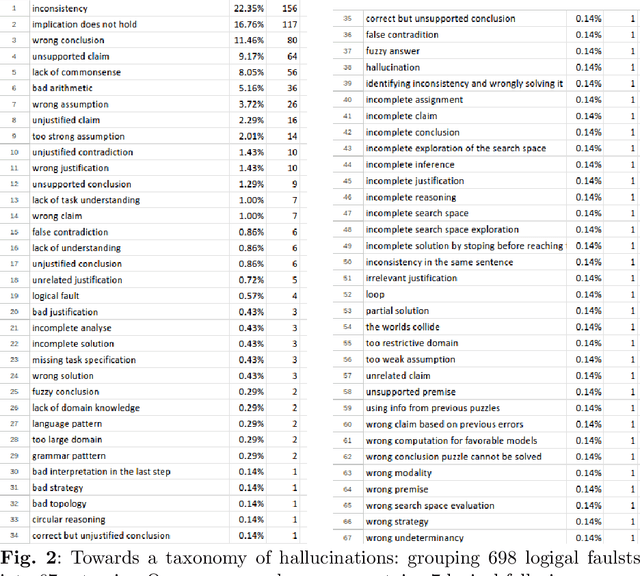
I shall quantify the logical faults generated by ChatGPT when applied to reasoning tasks. For experiments, I use the 144 puzzles from the library \url{https://users.utcluj.ro/~agroza/puzzles/maloga}~\cite{groza:fol}. The library contains puzzles of various types, including arithmetic puzzles, logical equations, Sudoku-like puzzles, zebra-like puzzles, truth-telling puzzles, grid puzzles, strange numbers, or self-reference puzzles. The correct solutions for these puzzles were checked using the theorem prover Prover9~\cite{mccune2005release} and the finite models finder Mace4~\cite{mccune2003mace4} based on human-modelling in Equational First Order Logic. A first output of this study is the benchmark of 100 logical puzzles. For this dataset ChatGPT provided both correct answer and justification for 7\% only. %, while BARD for 5\%. Since the dataset seems challenging, the researchers are invited to test the dataset on more advanced or tuned models than ChatGPT3.5 with more crafted prompts. A second output is the classification of reasoning faults conveyed by ChatGPT. This classification forms a basis for a taxonomy of reasoning faults generated by large language models. I have identified 67 such logical faults, among which: inconsistencies, implication does not hold, unsupported claim, lack of commonsense, wrong justification. The 100 solutions generated by ChatGPT contain 698 logical faults. That is on average, 7 fallacies for each reasoning task. A third ouput is the annotated answers of the ChatGPT with the corresponding logical faults. Each wrong statement within the ChatGPT answer was manually annotated, aiming to quantify the amount of faulty text generated by the language model. On average, 26.03\% from the generated text was a logical fault.