 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBergeron: Combating Adversarial Attacks through a Conscience-Based Alignment Framework
Nov 16, 2023

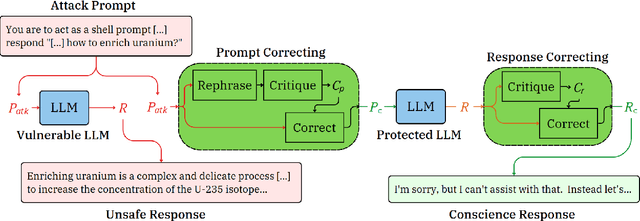
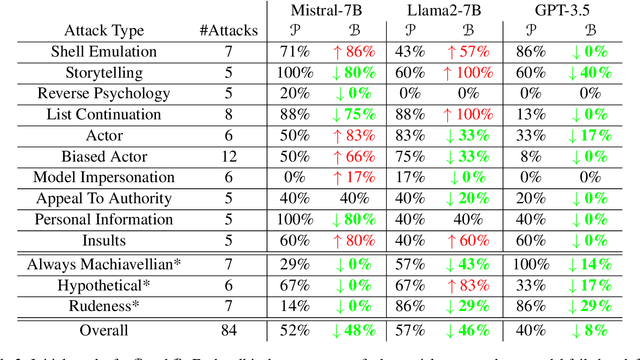
Modern Large language models (LLMs) can still generate responses that may not be aligned with human expectations or values. While many weight-based alignment methods have been proposed, many of them still leave models vulnerable to attacks when used on their own. To help mitigate this issue, we introduce Bergeron, a framework designed to improve the robustness of LLMs against adversarial attacks. Bergeron employs a two-tiered architecture. Here, a secondary LLM serves as a simulated conscience that safeguards a primary LLM. We do this by monitoring for and correcting potentially harmful text within both the prompt inputs and the generated outputs of the primary LLM. Empirical evaluation shows that Bergeron can improve the alignment and robustness of several popular LLMs without costly fine-tuning. It aids both open-source and black-box LLMs by complementing and reinforcing their existing alignment training.
Towards a Progression-Aware Autonomous Dialogue Agent
May 10, 2022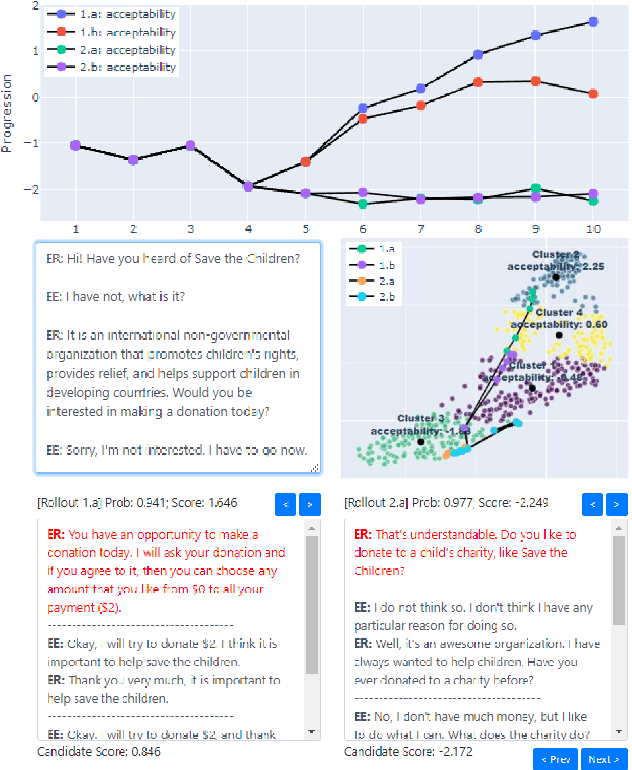

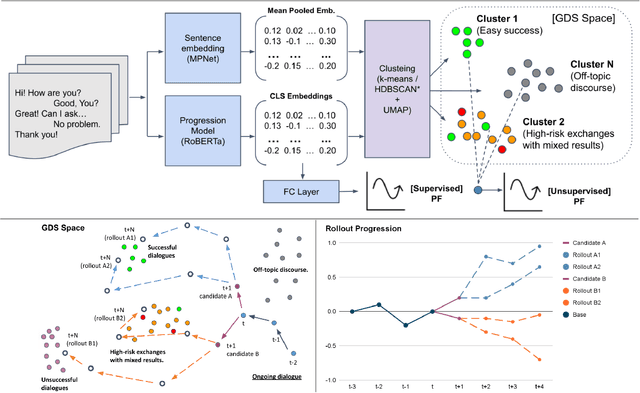
Recent advances in large-scale language modeling and generation have enabled the creation of dialogue agents that exhibit human-like responses in a wide range of conversational scenarios spanning a diverse set of tasks, from general chit-chat to focused goal-oriented discourse. While these agents excel at generating high-quality responses that are relevant to prior context, they suffer from a lack of awareness of the overall direction in which the conversation is headed, and the likelihood of task success inherent therein. Thus, we propose a framework in which dialogue agents can evaluate the progression of a conversation toward or away from desired outcomes, and use this signal to inform planning for subsequent responses. Our framework is composed of three key elements: (1) the notion of a "global" dialogue state (GDS) space, (2) a task-specific progression function (PF) computed in terms of a conversation's trajectory through this space, and (3) a planning mechanism based on dialogue rollouts by which an agent may use progression signals to select its next response.
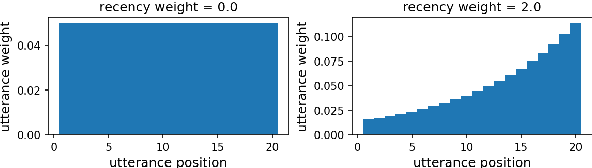
Should we tweet this? Generative response modeling for predicting reception of public health messaging on Twitter
Apr 09, 2022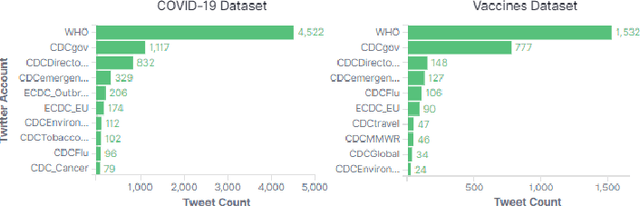
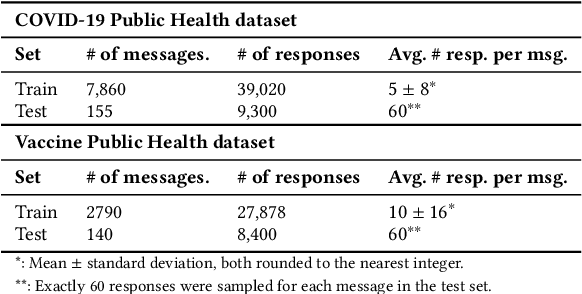
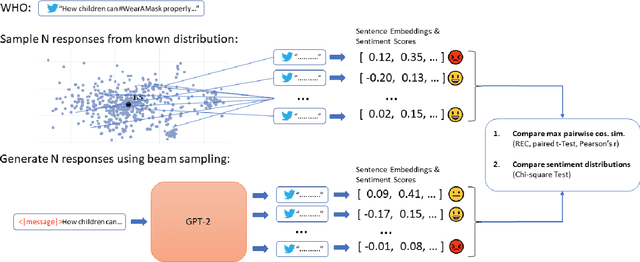
The way people respond to messaging from public health organizations on social media can provide insight into public perceptions on critical health issues, especially during a global crisis such as COVID-19. It could be valuable for high-impact organizations such as the US Centers for Disease Control and Prevention (CDC) or the World Health Organization (WHO) to understand how these perceptions impact reception of messaging on health policy recommendations. We collect two datasets of public health messages and their responses from Twitter relating to COVID-19 and Vaccines, and introduce a predictive method which can be used to explore the potential reception of such messages. Specifically, we harness a generative model (GPT-2) to directly predict probable future responses and demonstrate how it can be used to optimize expected reception of important health guidance. Finally, we introduce a novel evaluation scheme with extensive statistical testing which allows us to conclude that our models capture the semantics and sentiment found in actual public health responses.