 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBergeron: Combating Adversarial Attacks through a Conscience-Based Alignment Framework
Paper and Code


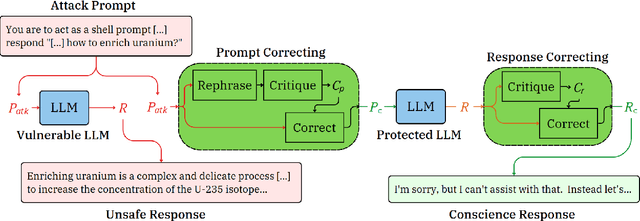
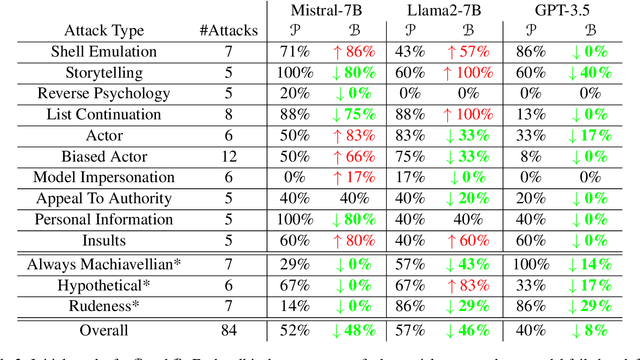
Modern Large language models (LLMs) can still generate responses that may not be aligned with human expectations or values. While many weight-based alignment methods have been proposed, many of them still leave models vulnerable to attacks when used on their own. To help mitigate this issue, we introduce Bergeron, a framework designed to improve the robustness of LLMs against adversarial attacks. Bergeron employs a two-tiered architecture. Here, a secondary LLM serves as a simulated conscience that safeguards a primary LLM. We do this by monitoring for and correcting potentially harmful text within both the prompt inputs and the generated outputs of the primary LLM. Empirical evaluation shows that Bergeron can improve the alignment and robustness of several popular LLMs without costly fine-tuning. It aids both open-source and black-box LLMs by complementing and reinforcing their existing alignment training.