 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDROGON: A Causal Reasoning Framework for Future Trajectory Forecast
Jul 31, 2019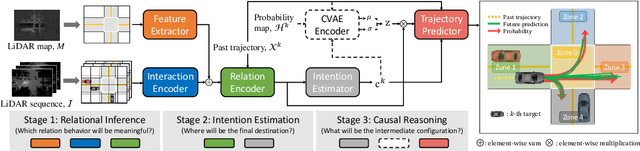
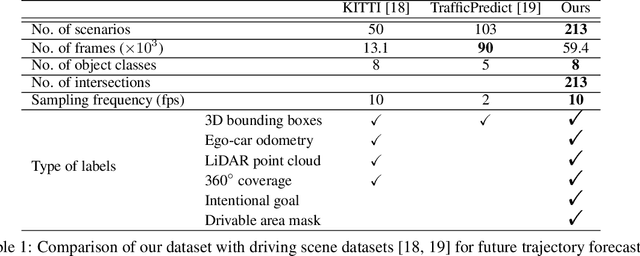
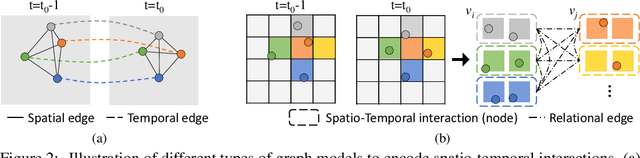
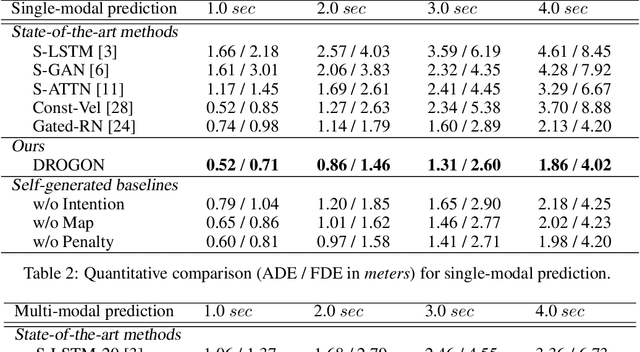
We propose DROGON (Deep RObust Goal-Oriented trajectory prediction Network) for accurate vehicle trajectory forecast by considering behavioral intention of vehicles in traffic scenes. Our main insight is that a causal relationship between intention and behavior of drivers can be reasoned from the observation of their relational interactions toward an environment. To succeed in causal reasoning, we build a conditional prediction model to forecast goal-oriented trajectories, which is trained with the following stages: (i) relational inference where we encode relational interactions of vehicles using the perceptual context; (ii) intention estimation to compute the probability distribution of intentional goals based on the inferred relations; and (iii) causal reasoning where we reason about the behavior of vehicles as future locations conditioned on the intention. To properly evaluate the performance of our approach, we present a new large-scale dataset collected at road intersections with diverse interactions of vehicles. The experiments demonstrate the efficacy of DROGON as it consistently outperforms state-of-the-art techniques.
The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes
Mar 04, 2019
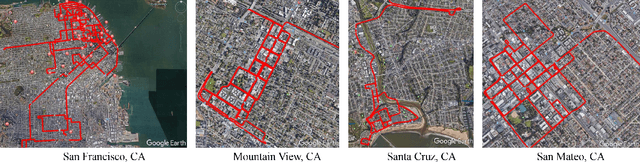
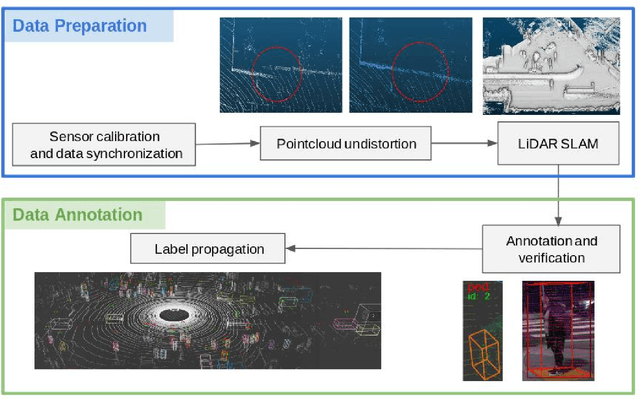
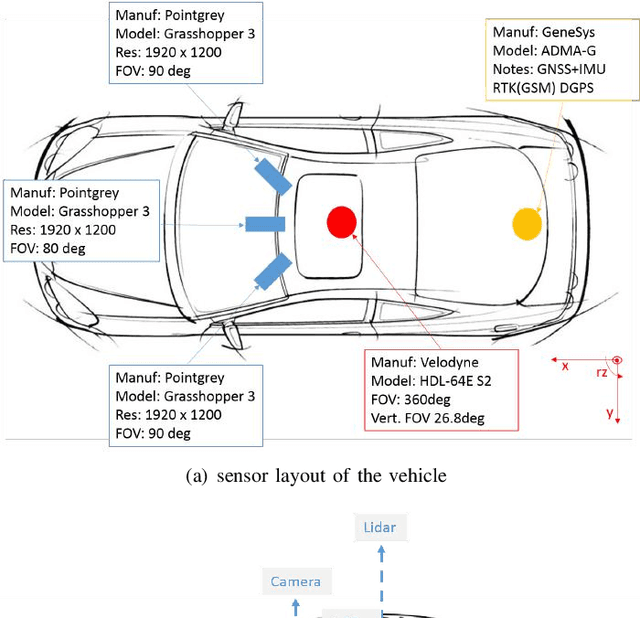
3D multi-object detection and tracking are crucial for traffic scene understanding. However, the community pays less attention to these areas due to the lack of a standardized benchmark dataset to advance the field. Moreover, existing datasets (e.g., KITTI) do not provide sufficient data and labels to tackle challenging scenes where highly interactive and occluded traffic participants are present. To address the issues, we present the Honda Research Institute 3D Dataset (H3D), a large-scale full-surround 3D multi-object detection and tracking dataset collected using a 3D LiDAR scanner. H3D comprises of 160 crowded and highly interactive traffic scenes with a total of 1 million labeled instances in 27,721 frames. With unique dataset size, rich annotations, and complex scenes, H3D is gathered to stimulate research on full-surround 3D multi-object detection and tracking. To effectively and efficiently annotate a large-scale 3D point cloud dataset, we propose a labeling methodology to speed up the overall annotation cycle. A standardized benchmark is created to evaluate full-surround 3D multi-object detection and tracking algorithms. 3D object detection and tracking algorithms are trained and tested on H3D. Finally, sources of errors are discussed for the development of future algorithms.
* The dataset is available at https://usa.honda-ri.com/H3D