 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGEMM: Optimizing GEMM for Deep Learning via Compiler-based Techniques
Nov 13, 2019
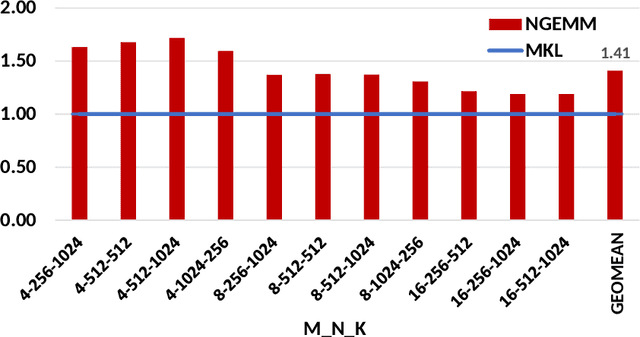
Quantization has emerged to be an effective way to significantly boost the performance of deep neural networks (DNNs) by utilizing low-bit computations. Despite having lower numerical precision, quantized DNNs are able to reduce both memory bandwidth and computation cycles with little losses of accuracy. Integer GEMM (General Matrix Multiplication) is critical to running quantized DNN models efficiently, as GEMM operations often dominate the computations in these models. Various approaches have been developed by leveraging techniques such as vectorization and memory layout to improve the performance of integer GEMM. However, these existing approaches are not fast enough in certain scenarios. We developed NGEMM, a compiler-based GEMM implementation for accelerating lower-precision training and inference. NGEMM has better use of the vector units by avoiding unnecessary vector computation that is introduced during tree reduction. We compared NGEMM's performance with the state-of-art BLAS libraries such as MKL. Our experimental results showed that NGEMM outperformed MKL non-pack and pack version by an average of 1.86x and 1.16x, respectively. We have applied NGEMM to a number of production services in Microsoft.