 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUTR: Curriculum Learning via Unsupervised Task Representation Learning
Oct 19, 2022



Reinforcement Learning (RL) algorithms are often known for sample inefficiency and difficult generalization. Recently, Unsupervised Environment Design (UED) emerged as a new paradigm for zero-shot generalization by simultaneously learning a task distribution and agent policies on the sampled tasks. This is a non-stationary process where the task distribution evolves along with agent policies, creating an instability over time. While past works demonstrated the potential of such approaches, sampling effectively from the task space remains an open challenge, bottlenecking these approaches. To this end, we introduce CLUTR: a novel curriculum learning algorithm that decouples task representation and curriculum learning into a two-stage optimization. It first trains a recurrent variational autoencoder on randomly generated tasks to learn a latent task manifold. Next, a teacher agent creates a curriculum by maximizing a minimax REGRET-based objective on a set of latent tasks sampled from this manifold. By keeping the task manifold fixed, we show that CLUTR successfully overcomes the non-stationarity problem and improves stability. Our experimental results show CLUTR outperforms PAIRED, a principled and popular UED method, in terms of generalization and sample efficiency in the challenging CarRacing and navigation environments: showing an 18x improvement on the F1 CarRacing benchmark. CLUTR also performs comparably to the non-UED state-of-the-art for CarRacing, outperforming it in nine of the 20 tracks. CLUTR also achieves a 33% higher solved rate than PAIRED on a set of 18 out-of-distribution navigation tasks.
Scenic4RL: Programmatic Modeling and Generation of Reinforcement Learning Environments
Jun 18, 2021

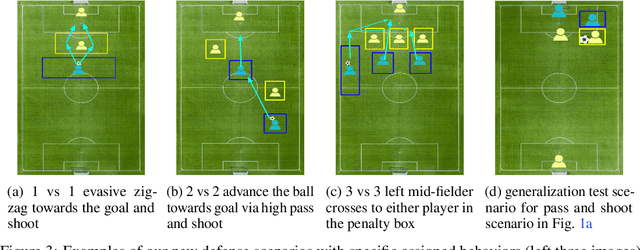
The capability of reinforcement learning (RL) agent directly depends on the diversity of learning scenarios the environment generates and how closely it captures real-world situations. However, existing environments/simulators lack the support to systematically model distributions over initial states and transition dynamics. Furthermore, in complex domains such as soccer, the space of possible scenarios is infinite, which makes it impossible for one research group to provide a comprehensive set of scenarios to train, test, and benchmark RL algorithms. To address this issue, for the first time, we adopt an existing formal scenario specification language, SCENIC, to intuitively model and generate interactive scenarios. We interfaced SCENIC to Google Research Soccer environment to create a platform called SCENIC4RL. Using this platform, we provide a dataset consisting of 36 scenario programs encoded in SCENIC and demonstration data generated from a subset of them. We share our experimental results to show the effectiveness of our dataset and the platform to train, test, and benchmark RL algorithms. More importantly, we open-source our platform to enable RL community to collectively contribute to constructing a comprehensive set of scenarios.