 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Adoption of AI Coding Agents in Open-source Android and iOS Development
Feb 12, 2026AI coding agents are increasingly contributing to software development, yet their impact on mobile development has received little empirical attention. In this paper, we present the first category-level empirical study of agent-generated code in open-source mobile app projects. We analyzed PR acceptance behaviors across mobile platforms, agents, and task categories using 2,901 AI-authored pull requests (PRs) in 193 verified Android and iOS open-source GitHub repositories in the AIDev dataset. We find that Android projects have received 2x more AI-authored PRs and have achieved higher PR acceptance rate (71%) than iOS (63%), with significant agent-level variation on Android. Across task categories, PRs with routine tasks (feature, fix, and ui) achieve the highest acceptance, while structural changes like refactor and build achieve lower success and longer resolution times. Furthermore, our evolution analysis shows improvement in PR resolution time on Android through mid-2025 before it declined again. Our findings offer the first evidence-based characterization of AI agents effects on OSS mobile projects and establish empirical baselines for evaluating agent-generated contributions to design platform aware agentic systems.
Understanding Prompt Management in GitHub Repositories: A Call for Best Practices
Sep 15, 2025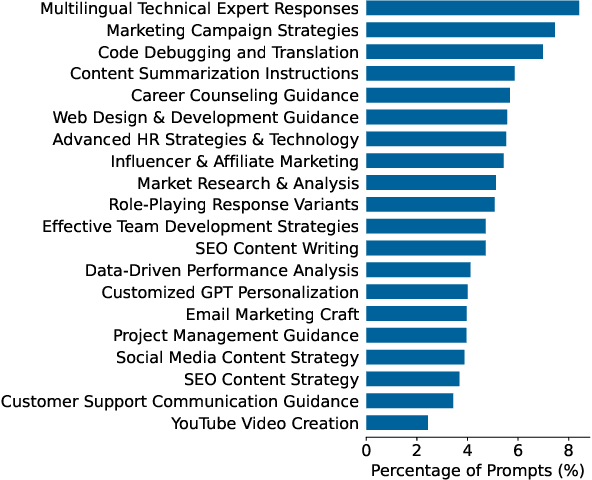
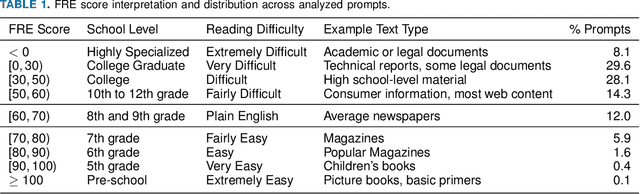
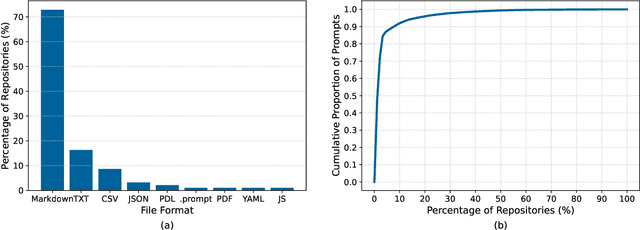

The rapid adoption of foundation models (e.g., large language models) has given rise to promptware, i.e., software built using natural language prompts. Effective management of prompts, such as organization and quality assurance, is essential yet challenging. In this study, we perform an empirical analysis of 24,800 open-source prompts from 92 GitHub repositories to investigate prompt management practices and quality attributes. Our findings reveal critical challenges such as considerable inconsistencies in prompt formatting, substantial internal and external prompt duplication, and frequent readability and spelling issues. Based on these findings, we provide actionable recommendations for developers to enhance the usability and maintainability of open-source prompts within the rapidly evolving promptware ecosystem.
On the Workflows and Smells of Leaderboard Operations (LBOps): An Exploratory Study of Foundation Model Leaderboards
Jul 04, 2024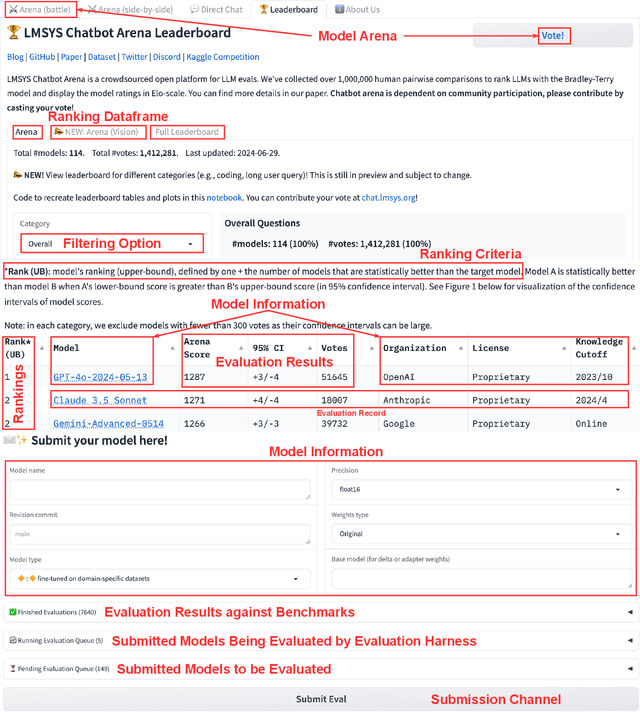
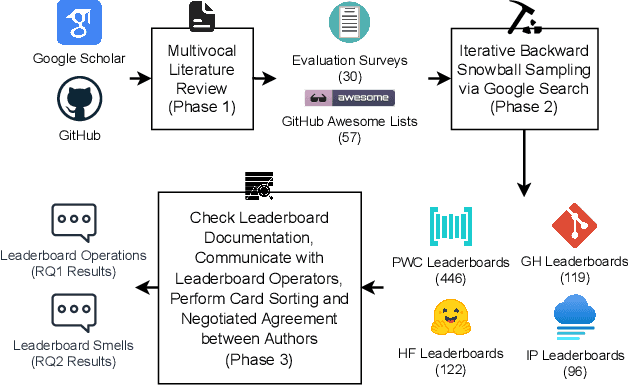
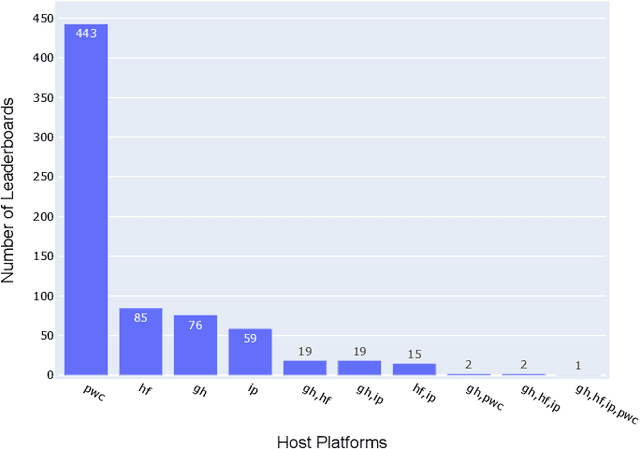
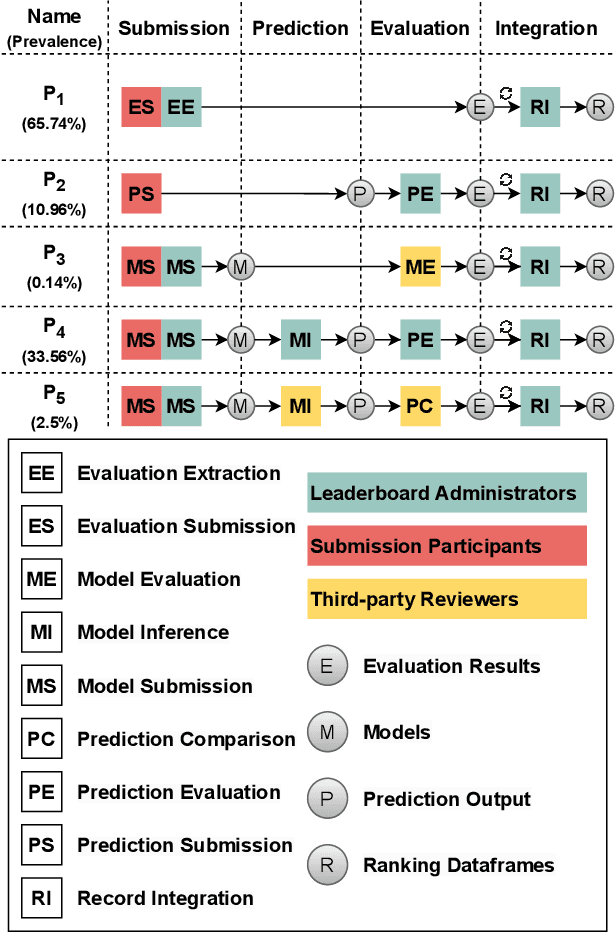
Foundation models (FM), such as large language models (LLMs), which are large-scale machine learning (ML) models, have demonstrated remarkable adaptability in various downstream software engineering (SE) tasks, such as code completion, code understanding, and software development. As a result, FM leaderboards, especially those hosted on cloud platforms, have become essential tools for SE teams to compare and select the best third-party FMs for their specific products and purposes. However, the lack of standardized guidelines for FM evaluation and comparison threatens the transparency of FM leaderboards and limits stakeholders' ability to perform effective FM selection. As a first step towards addressing this challenge, our research focuses on understanding how these FM leaderboards operate in real-world scenarios ("leaderboard operations") and identifying potential leaderboard pitfalls and areas for improvement ("leaderboard smells"). In this regard, we perform a multivocal literature review to collect up to 721 FM leaderboards, after which we examine their documentation and engage in direct communication with leaderboard operators to understand their workflow patterns. Using card sorting and negotiated agreement, we identify 5 unique workflow patterns and develop a domain model that outlines the essential components and their interaction within FM leaderboards. We then identify 8 unique types of leaderboard smells in LBOps. By mitigating these smells, SE teams can improve transparency, accountability, and collaboration in current LBOps practices, fostering a more robust and responsible ecosystem for FM comparison and selection.
An Empirical Study of Challenges in Machine Learning Asset Management
Feb 28, 2024In machine learning (ML), efficient asset management, including ML models, datasets, algorithms, and tools, is vital for resource optimization, consistent performance, and a streamlined development lifecycle. This enables quicker iterations, adaptability, reduced development-to-deployment time, and reliable outputs. Despite existing research, a significant knowledge gap remains in operational challenges like model versioning, data traceability, and collaboration, which are crucial for the success of ML projects. Our study aims to address this gap by analyzing 15,065 posts from developer forums and platforms, employing a mixed-method approach to classify inquiries, extract challenges using BERTopic, and identify solutions through open card sorting and BERTopic clustering. We uncover 133 topics related to asset management challenges, grouped into 16 macro-topics, with software dependency, model deployment, and model training being the most discussed. We also find 79 solution topics, categorized under 18 macro-topics, highlighting software dependency, feature development, and file management as key solutions. This research underscores the need for further exploration of identified pain points and the importance of collaborative efforts across academia, industry, and the research community.
The State of Documentation Practices of Third-party Machine Learning Models and Datasets
Dec 22, 2023Model stores offer third-party ML models and datasets for easy project integration, minimizing coding efforts. One might hope to find detailed specifications of these models and datasets in the documentation, leveraging documentation standards such as model and dataset cards. In this study, we use statistical analysis and hybrid card sorting to assess the state of the practice of documenting model cards and dataset cards in one of the largest model stores in use today--Hugging Face (HF). Our findings show that only 21,902 models (39.62\%) and 1,925 datasets (28.48\%) have documentation. Furthermore, we observe inconsistency in ethics and transparency-related documentation for ML models and datasets.