 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE Arena: Benchmarking Software Engineering Chatbots with Iterative Interactions
Feb 03, 2025

Foundation models (FMs), particularly large language models (LLMs), have shown significant promise in various software engineering (SE) tasks, including code generation, debugging, and requirement refinement. Despite these advances, existing evaluation frameworks are insufficient for assessing model performance in iterative, context-rich workflows characteristic of SE activities. To address this limitation, we introduce SE Arena, an interactive platform designed to evaluate SE-focused chatbots. SE Arena provides a transparent, open-source leaderboard, supports multi-round conversational workflows, and enables end-to-end model comparisons. Moreover, SE Arena incorporates a new feature called RepoChat, which automatically injects repository-related context (e.g., issues, commits, pull requests) into the conversation, further aligning evaluations with real-world development processes. This paper outlines the design and capabilities of SE Arena, emphasizing its potential to advance the evaluation and practical application of FMs in software engineering.
On the Workflows and Smells of Leaderboard Operations (LBOps): An Exploratory Study of Foundation Model Leaderboards
Jul 04, 2024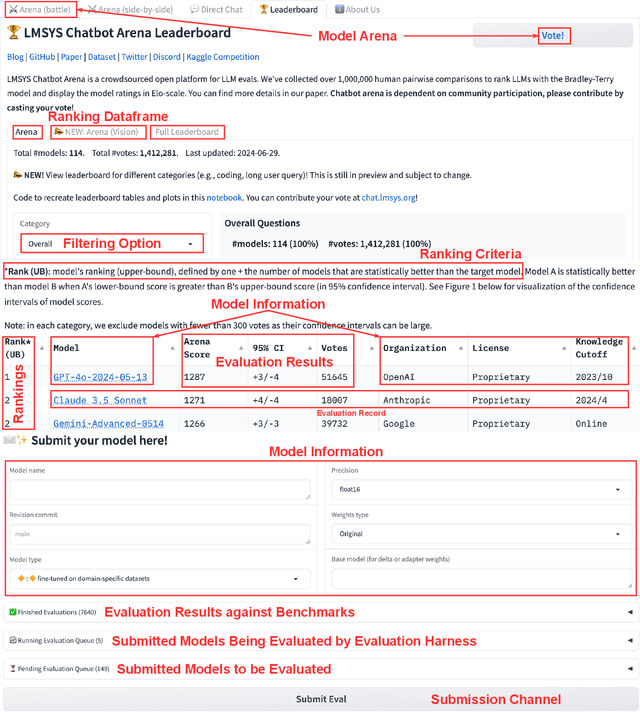
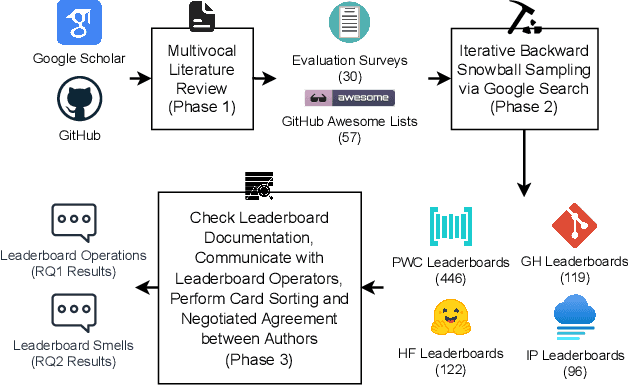
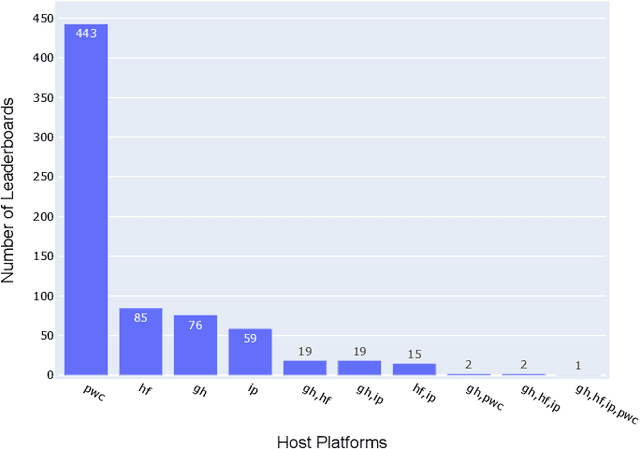
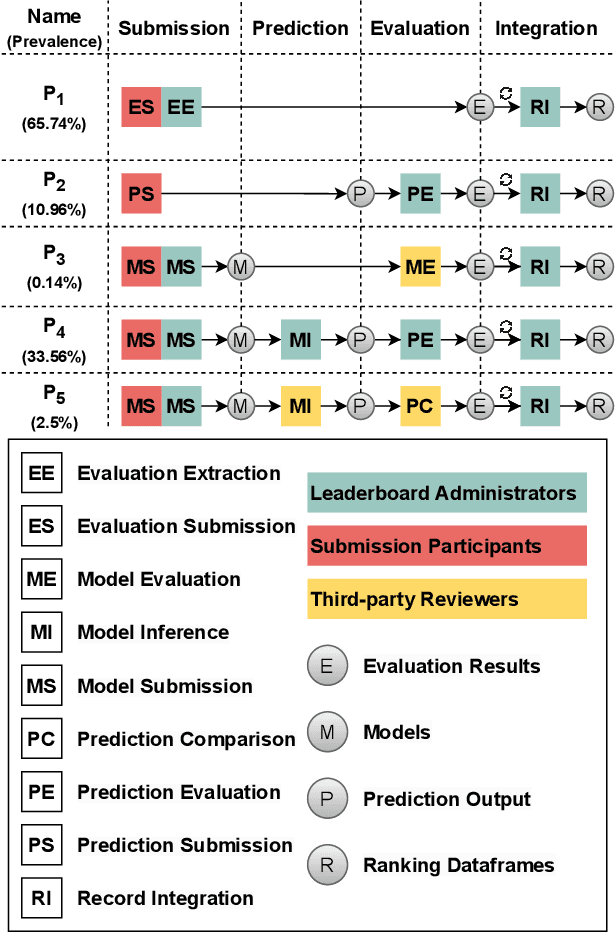
Foundation models (FM), such as large language models (LLMs), which are large-scale machine learning (ML) models, have demonstrated remarkable adaptability in various downstream software engineering (SE) tasks, such as code completion, code understanding, and software development. As a result, FM leaderboards, especially those hosted on cloud platforms, have become essential tools for SE teams to compare and select the best third-party FMs for their specific products and purposes. However, the lack of standardized guidelines for FM evaluation and comparison threatens the transparency of FM leaderboards and limits stakeholders' ability to perform effective FM selection. As a first step towards addressing this challenge, our research focuses on understanding how these FM leaderboards operate in real-world scenarios ("leaderboard operations") and identifying potential leaderboard pitfalls and areas for improvement ("leaderboard smells"). In this regard, we perform a multivocal literature review to collect up to 721 FM leaderboards, after which we examine their documentation and engage in direct communication with leaderboard operators to understand their workflow patterns. Using card sorting and negotiated agreement, we identify 5 unique workflow patterns and develop a domain model that outlines the essential components and their interaction within FM leaderboards. We then identify 8 unique types of leaderboard smells in LBOps. By mitigating these smells, SE teams can improve transparency, accountability, and collaboration in current LBOps practices, fostering a more robust and responsible ecosystem for FM comparison and selection.
An Empirical Study of Challenges in Machine Learning Asset Management
Feb 28, 2024In machine learning (ML), efficient asset management, including ML models, datasets, algorithms, and tools, is vital for resource optimization, consistent performance, and a streamlined development lifecycle. This enables quicker iterations, adaptability, reduced development-to-deployment time, and reliable outputs. Despite existing research, a significant knowledge gap remains in operational challenges like model versioning, data traceability, and collaboration, which are crucial for the success of ML projects. Our study aims to address this gap by analyzing 15,065 posts from developer forums and platforms, employing a mixed-method approach to classify inquiries, extract challenges using BERTopic, and identify solutions through open card sorting and BERTopic clustering. We uncover 133 topics related to asset management challenges, grouped into 16 macro-topics, with software dependency, model deployment, and model training being the most discussed. We also find 79 solution topics, categorized under 18 macro-topics, highlighting software dependency, feature development, and file management as key solutions. This research underscores the need for further exploration of identified pain points and the importance of collaborative efforts across academia, industry, and the research community.