 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Workflows and Smells of Leaderboard Operations (LBOps): An Exploratory Study of Foundation Model Leaderboards
Jul 04, 2024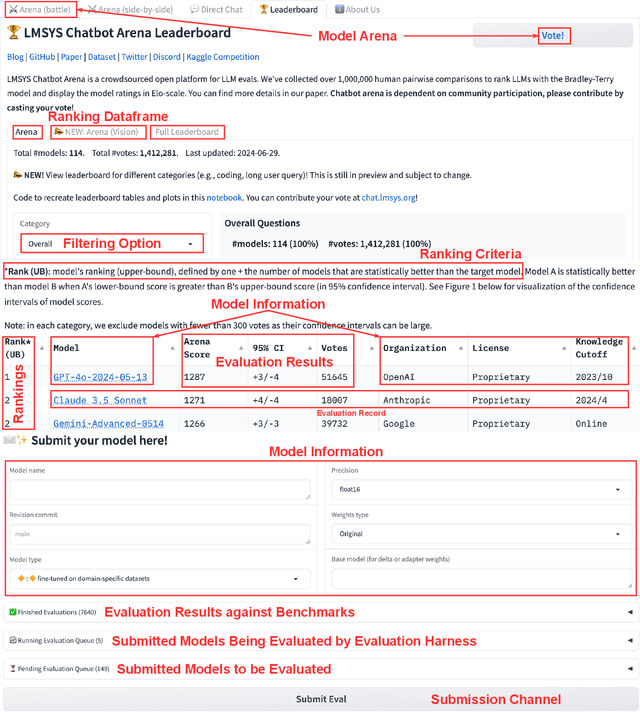
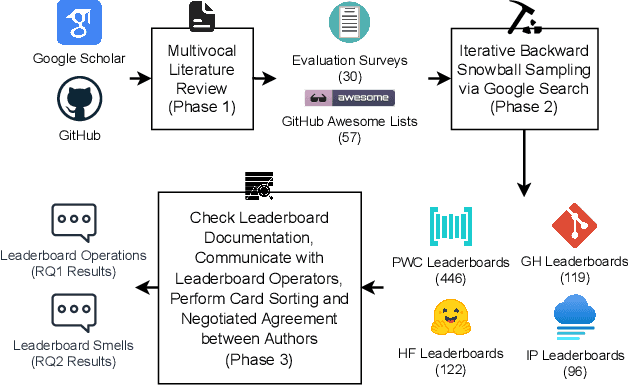
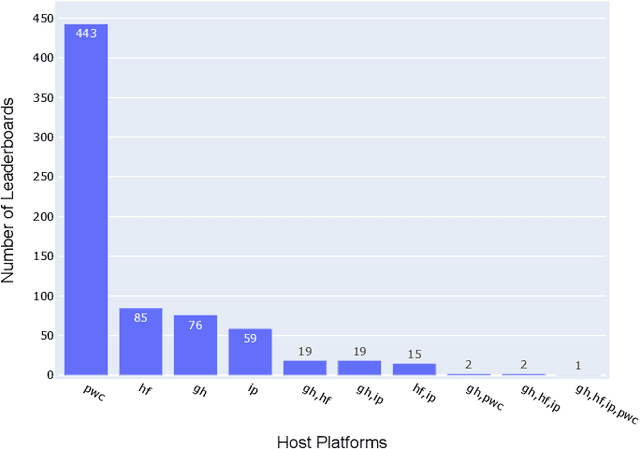
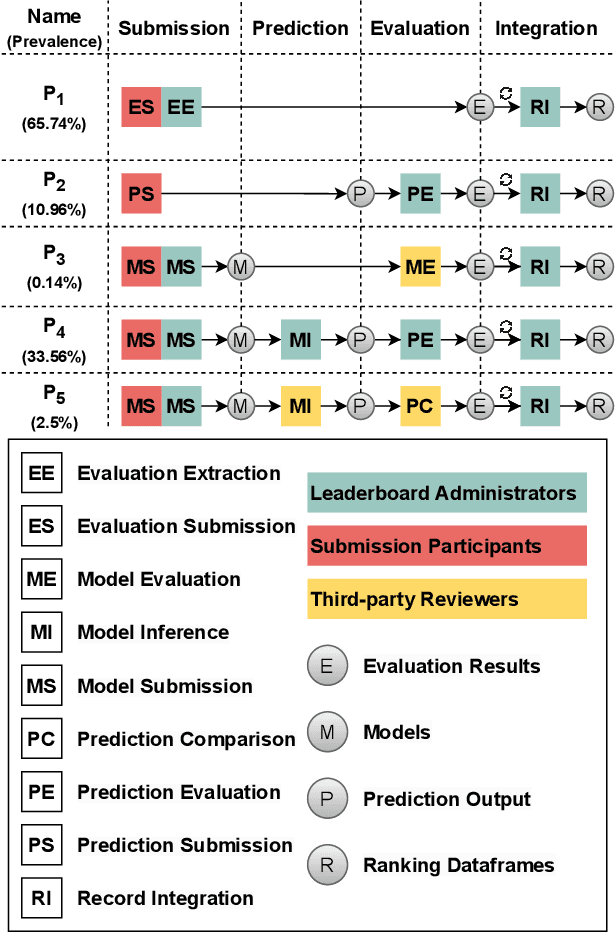
Foundation models (FM), such as large language models (LLMs), which are large-scale machine learning (ML) models, have demonstrated remarkable adaptability in various downstream software engineering (SE) tasks, such as code completion, code understanding, and software development. As a result, FM leaderboards, especially those hosted on cloud platforms, have become essential tools for SE teams to compare and select the best third-party FMs for their specific products and purposes. However, the lack of standardized guidelines for FM evaluation and comparison threatens the transparency of FM leaderboards and limits stakeholders' ability to perform effective FM selection. As a first step towards addressing this challenge, our research focuses on understanding how these FM leaderboards operate in real-world scenarios ("leaderboard operations") and identifying potential leaderboard pitfalls and areas for improvement ("leaderboard smells"). In this regard, we perform a multivocal literature review to collect up to 721 FM leaderboards, after which we examine their documentation and engage in direct communication with leaderboard operators to understand their workflow patterns. Using card sorting and negotiated agreement, we identify 5 unique workflow patterns and develop a domain model that outlines the essential components and their interaction within FM leaderboards. We then identify 8 unique types of leaderboard smells in LBOps. By mitigating these smells, SE teams can improve transparency, accountability, and collaboration in current LBOps practices, fostering a more robust and responsible ecosystem for FM comparison and selection.