 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedECADO: A Dynamical System Model of Federated Learning
Oct 13, 2024Federated learning harnesses the power of distributed optimization to train a unified machine learning model across separate clients. However, heterogeneous data distributions and computational workloads can lead to inconsistent updates and limit model performance. This work tackles these challenges by proposing FedECADO, a new algorithm inspired by a dynamical system representation of the federated learning process. FedECADO addresses non-IID data distribution through an aggregate sensitivity model that reflects the amount of data processed by each client. To tackle heterogeneous computing, we design a multi-rate integration method with adaptive step-size selections that synchronizes active client updates in continuous time. Compared to prominent techniques, including FedProx and FedNova, FedECADO achieves higher classification accuracies in numerous heterogeneous scenarios.
Towards Hyperparameter-Agnostic DNN Training via Dynamical System Insights
Oct 21, 2023We present a stochastic first-order optimization method specialized for deep neural networks (DNNs), ECCO-DNN. This method models the optimization variable trajectory as a dynamical system and develops a discretization algorithm that adaptively selects step sizes based on the trajectory's shape. This provides two key insights: designing the dynamical system for fast continuous-time convergence and developing a time-stepping algorithm to adaptively select step sizes based on principles of numerical integration and neural network structure. The result is an optimizer with performance that is insensitive to hyperparameter variations and that achieves comparable performance to state-of-the-art optimizers including ADAM, SGD, RMSProp, and AdaGrad. We demonstrate this in training DNN models and datasets, including CIFAR-10 and CIFAR-100 using ECCO-DNN and find that ECCO-DNN's single hyperparameter can be changed by three orders of magnitude without affecting the trained models' accuracies. ECCO-DNN's insensitivity reduces the data and computation needed for hyperparameter tuning, making it advantageous for rapid prototyping and for applications with new datasets. To validate the efficacy of our proposed optimizer, we train an LSTM architecture on a household power consumption dataset with ECCO-DNN and achieve an optimal mean-square-error without tuning hyperparameters.
Adversarially Robust Learning for Security-Constrained Optimal Power Flow
Nov 12, 2021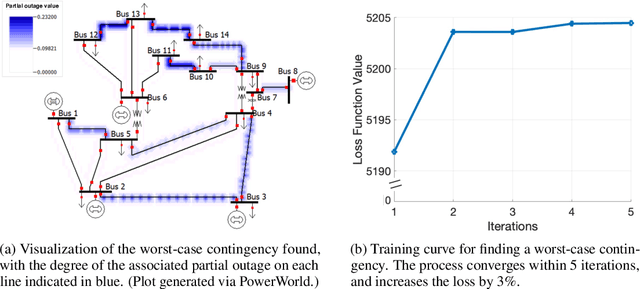

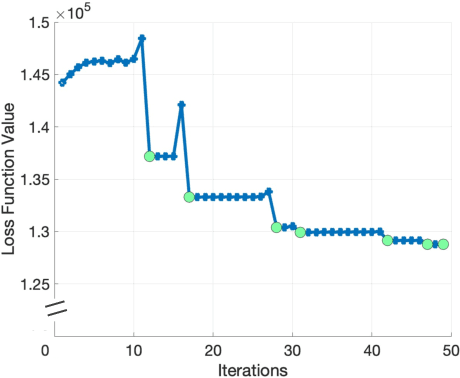
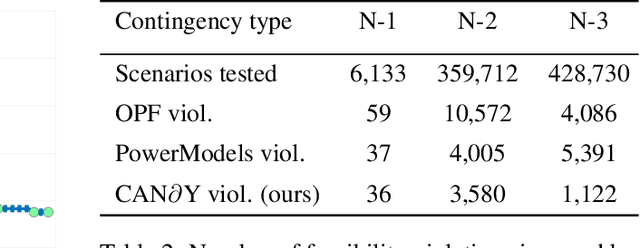
In recent years, the ML community has seen surges of interest in both adversarially robust learning and implicit layers, but connections between these two areas have seldom been explored. In this work, we combine innovations from these areas to tackle the problem of N-k security-constrained optimal power flow (SCOPF). N-k SCOPF is a core problem for the operation of electrical grids, and aims to schedule power generation in a manner that is robust to potentially k simultaneous equipment outages. Inspired by methods in adversarially robust training, we frame N-k SCOPF as a minimax optimization problem - viewing power generation settings as adjustable parameters and equipment outages as (adversarial) attacks - and solve this problem via gradient-based techniques. The loss function of this minimax problem involves resolving implicit equations representing grid physics and operational decisions, which we differentiate through via the implicit function theorem. We demonstrate the efficacy of our framework in solving N-3 SCOPF, which has traditionally been considered as prohibitively expensive to solve given that the problem size depends combinatorially on the number of potential outages.