 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn modeling vagueness and uncertainty in data-to-text systems through fuzzy sets
Oct 27, 2017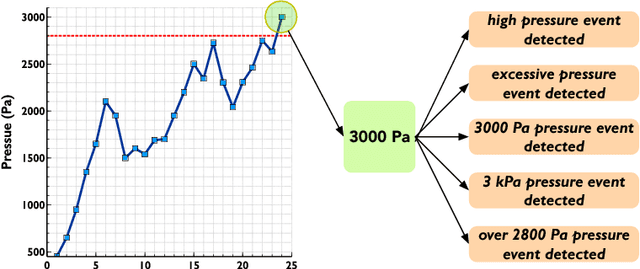
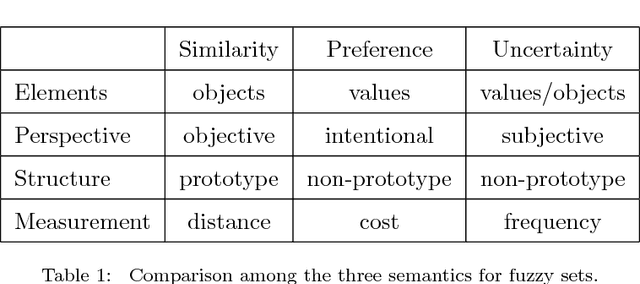
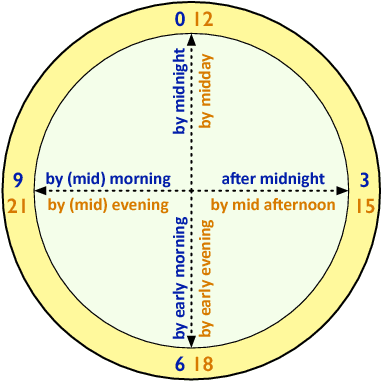
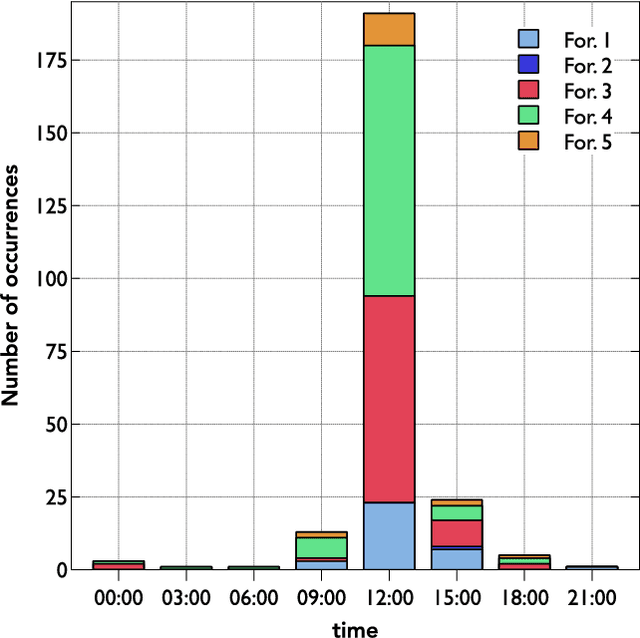
Vagueness and uncertainty management is counted among one of the challenges that remain unresolved in systems that generate texts from non-linguistic data, known as data-to-text systems. In the last decade, work in fuzzy linguistic summarization and description of data has raised the interest of using fuzzy sets to model and manage the imprecision of human language in data-to-text systems. However, despite some research in this direction, there has not been an actual clear discussion and justification on how fuzzy sets can contribute to data-to-text for modeling vagueness and uncertainty in words and expressions. This paper intends to bridge this gap by answering the following questions: What does vagueness mean in fuzzy sets theory? What does vagueness mean in data-to-text contexts? In what ways can fuzzy sets theory contribute to improve data-to-text systems? What are the challenges that researchers from both disciplines need to address for a successful integration of fuzzy sets into data-to-text systems? In what cases should the use of fuzzy sets be avoided in D2T? For this, we review and discuss the state of the art of vagueness modeling in natural language generation and data-to-text, describe potential and actual usages of fuzzy sets in data-to-text contexts, and provide some additional insights about the engineering of data-to-text systems that make use of fuzzy set-based techniques.
Fuzzy Sets Across the Natural Language Generation Pipeline
May 17, 2016
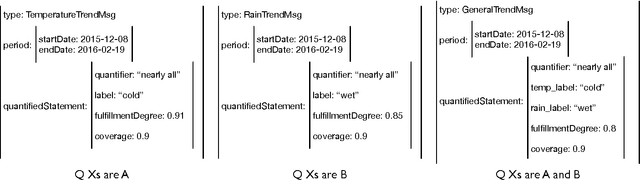


We explore the implications of using fuzzy techniques (mainly those commonly used in the linguistic description/summarization of data discipline) from a natural language generation perspective. For this, we provide an extensive discussion of some general convergence points and an exploration of the relationship between the different tasks involved in the standard NLG system pipeline architecture and the most common fuzzy approaches used in linguistic summarization/description of data, such as fuzzy quantified statements, evaluation criteria or aggregation operators. Each individual discussion is illustrated with a related use case. Recent work made in the context of cross-fertilization of both research fields is also referenced. This paper encompasses general ideas that emerged as part of the PhD thesis "Application of fuzzy sets in data-to-text systems". It does not present a specific application or a formal approach, but rather discusses current high-level issues and potential usages of fuzzy sets (focused on linguistic summarization of data) in natural language generation.
Characterizing Quantifier Fuzzification Mechanisms: a behavioral guide for practical applications
May 11, 2016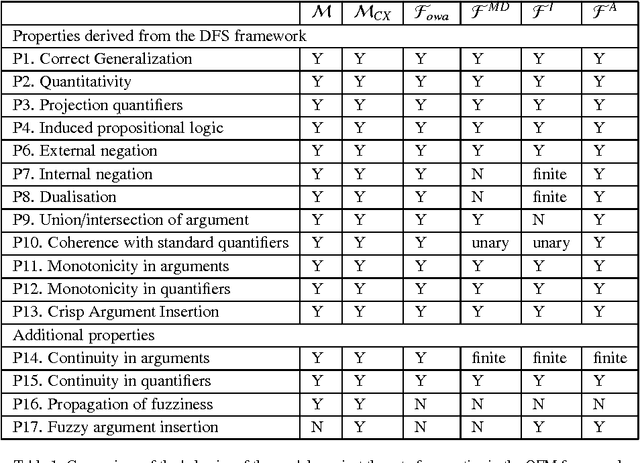

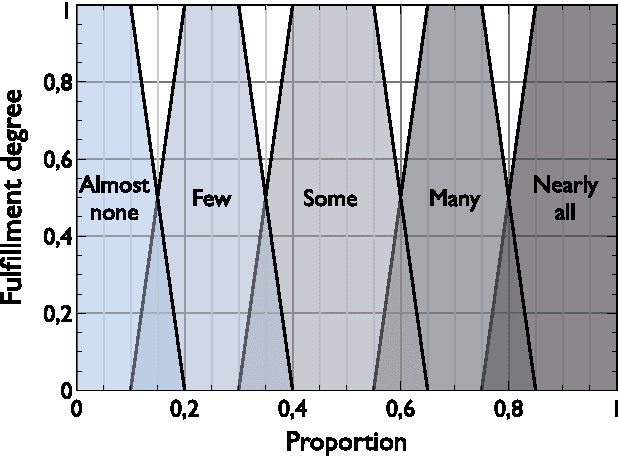

Important advances have been made in the fuzzy quantification field. Nevertheless, some problems remain when we face the decision of selecting the most convenient model for a specific application. In the literature, several desirable adequacy properties have been proposed, but theoretical limits impede quantification models from simultaneously fulfilling every adequacy property that has been defined. Besides, the complexity of model definitions and adequacy properties makes very difficult for real users to understand the particularities of the different models that have been presented. In this work we will present several criteria conceived to help in the process of selecting the most adequate Quantifier Fuzzification Mechanisms for specific practical applications. In addition, some of the best known well-behaved models will be compared against this list of criteria. Based on this analysis, some guidance to choose fuzzy quantification models for practical applications will be provided.
Linguistic Descriptions for Automatic Generation of Textual Short-Term Weather Forecasts on Real Prediction Data
Nov 18, 2014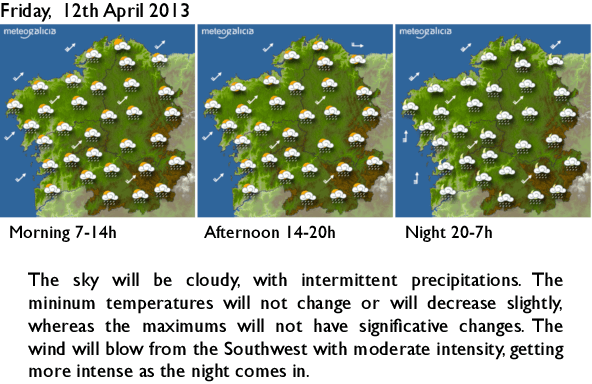
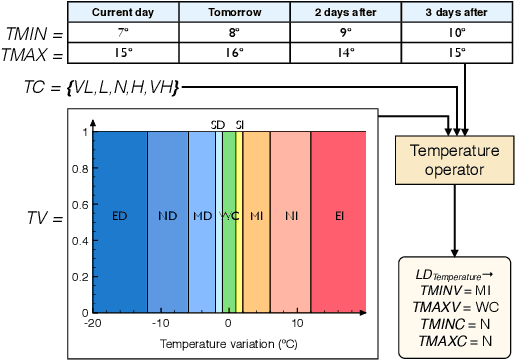

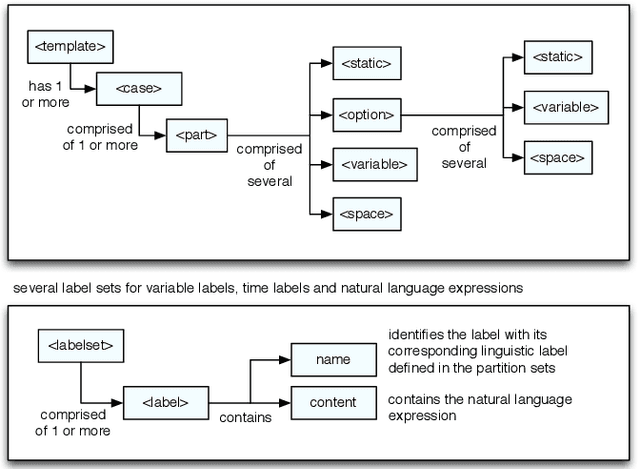
We present in this paper an application which automatically generates textual short-term weather forecasts for every municipality in Galicia (NW Spain), using the real data provided by the Galician Meteorology Agency (MeteoGalicia). This solution combines in an innovative way computing with perceptions techniques and strategies for linguistic description of data together with a natural language generation (NLG) system. The application, named GALiWeather, extracts relevant information from weather forecast input data and encodes it into intermediate descriptions using linguistic variables and temporal references. These descriptions are later translated into natural language texts by the natural language generation system. The obtained forecast results have been thoroughly validated by an expert meteorologist from MeteoGalicia using a quality assessment methodology which covers two key dimensions of a text: the accuracy of its content and the correctness of its form. Following this validation GALiWeather will be released as a real service offering custom forecasts for a wide public.