 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Sets Across the Natural Language Generation Pipeline
Paper and Code
May 17, 2016
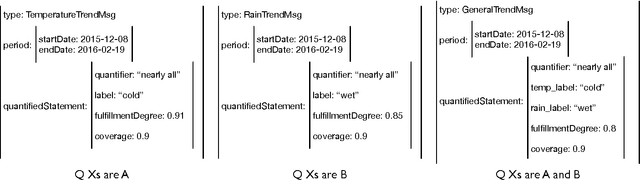


We explore the implications of using fuzzy techniques (mainly those commonly used in the linguistic description/summarization of data discipline) from a natural language generation perspective. For this, we provide an extensive discussion of some general convergence points and an exploration of the relationship between the different tasks involved in the standard NLG system pipeline architecture and the most common fuzzy approaches used in linguistic summarization/description of data, such as fuzzy quantified statements, evaluation criteria or aggregation operators. Each individual discussion is illustrated with a related use case. Recent work made in the context of cross-fertilization of both research fields is also referenced. This paper encompasses general ideas that emerged as part of the PhD thesis "Application of fuzzy sets in data-to-text systems". It does not present a specific application or a formal approach, but rather discusses current high-level issues and potential usages of fuzzy sets (focused on linguistic summarization of data) in natural language generation.