 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Robustness of Collaborative Agents
Jan 14, 2021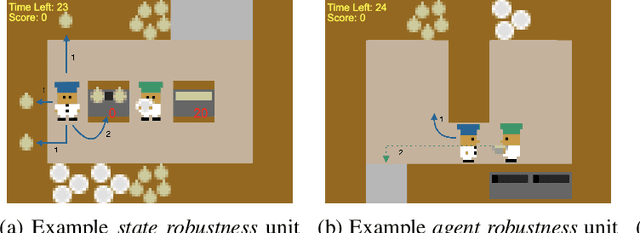
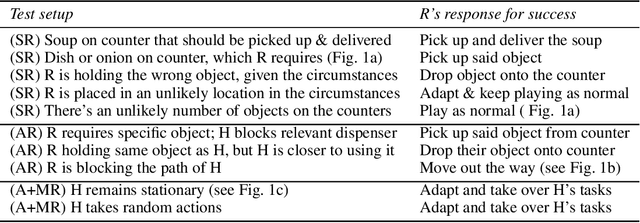


In order for agents trained by deep reinforcement learning to work alongside humans in realistic settings, we will need to ensure that the agents are \emph{robust}. Since the real world is very diverse, and human behavior often changes in response to agent deployment, the agent will likely encounter novel situations that have never been seen during training. This results in an evaluation challenge: if we cannot rely on the average training or validation reward as a metric, then how can we effectively evaluate robustness? We take inspiration from the practice of \emph{unit testing} in software engineering. Specifically, we suggest that when designing AI agents that collaborate with humans, designers should search for potential edge cases in \emph{possible partner behavior} and \emph{possible states encountered}, and write tests which check that the behavior of the agent in these edge cases is reasonable. We apply this methodology to build a suite of unit tests for the Overcooked-AI environment, and use this test suite to evaluate three proposals for improving robustness. We find that the test suite provides significant insight into the effects of these proposals that were generally not revealed by looking solely at the average validation reward.