 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKidnapped Radar: Topological Radar Localisation using Rotationally-Invariant Metric Learning
Jan 26, 2020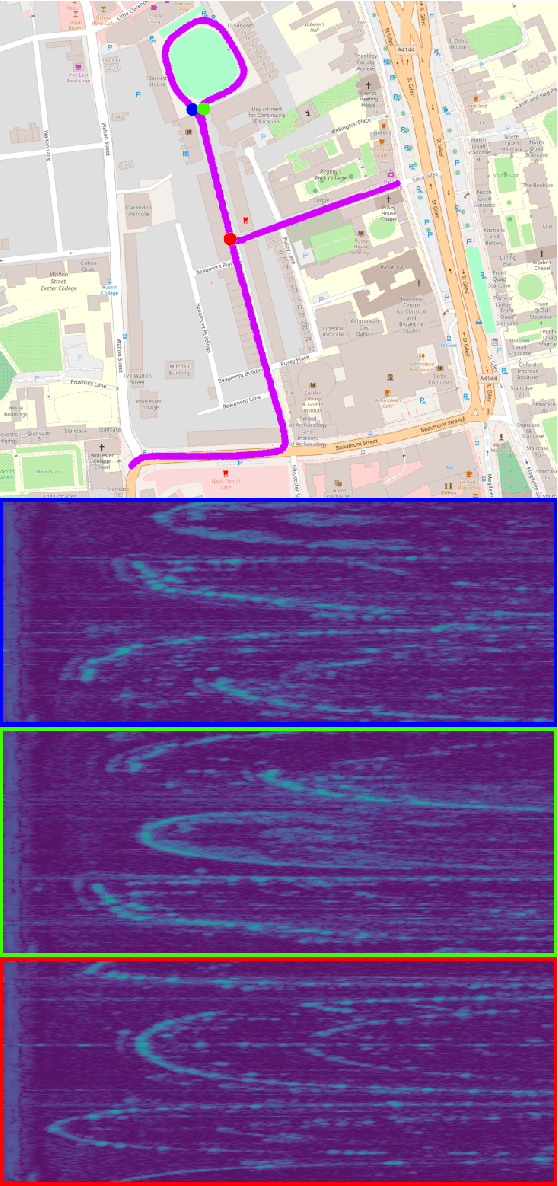
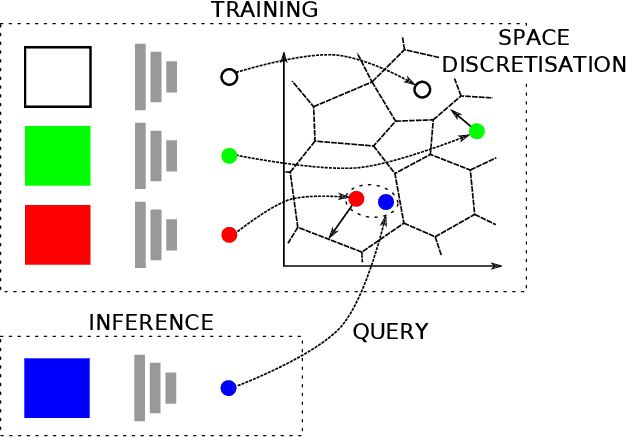

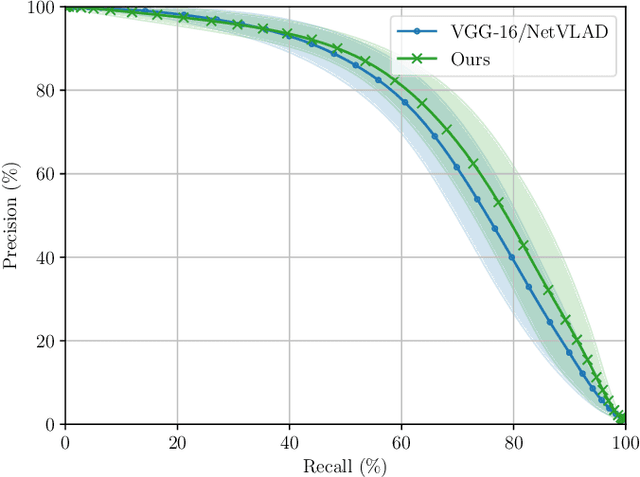
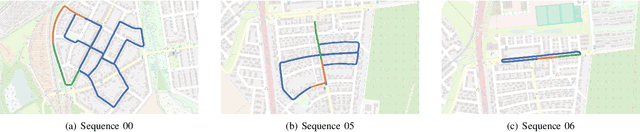
This paper presents a system for robust, large-scale topological localisation using Frequency-Modulated Continuous-Wave (FMCW) scanning radar. We learn a metric space for embedding polar radar scans using CNN and NetVLAD architectures traditionally applied to the visual domain. However, we tailor the feature extraction for more suitability to the polar nature of radar scan formation using cylindrical convolutions, anti-aliasing blurring, and azimuth-wise max-pooling; all in order to bolster the rotational invariance. The enforced metric space is then used to encode a reference trajectory, serving as a map, which is queried for nearest neighbours (NNs) for recognition of places at run-time. We demonstrate the performance of our topological localisation system over the course of many repeat forays using the largest radar-focused mobile autonomy dataset released to date, totalling 280 km of urban driving, a small portion of which we also use to learn the weights of the modified architecture. As this work represents a novel application for FMCW radar, we analyse the utility of the proposed method via a comprehensive set of metrics which provide insight into the efficacy when used in a realistic system, showing improved performance over the root architecture even in the face of random rotational perturbation.
Learning to Correct 3D Reconstructions from Multiple Views
Jan 22, 2020

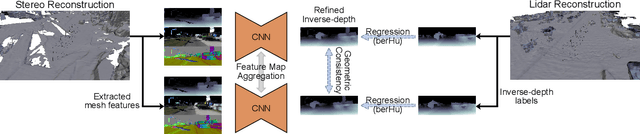
This paper is about reducing the cost of building good large-scale 3D reconstructions post-hoc. We render 2D views of an existing reconstruction and train a convolutional neural network (CNN) that refines inverse-depth to match a higher-quality reconstruction. Since the views that we correct are rendered from the same reconstruction, they share the same geometry, so overlapping views complement each other. We take advantage of that in two ways. Firstly, we impose a loss during training which guides predictions on neighbouring views to have the same geometry and has been shown to improve performance. Secondly, in contrast to previous work, which corrects each view independently, we also make predictions on sets of neighbouring views jointly. This is achieved by warping feature maps between views and thus bypassing memory-intensive 3D computation. We make the observation that features in the feature maps are viewpoint-dependent, and propose a method for transforming features with dynamic filters generated by a multi-layer perceptron from the relative poses between views. In our experiments we show that this last step is necessary for successfully fusing feature maps between views.
Learning Geometrically Consistent Mesh Corrections
Sep 08, 2019


Building good 3D maps is a challenging and expensive task, which requires high-quality sensors and careful, time-consuming scanning. We seek to reduce the cost of building good reconstructions by correcting views of existing low-quality ones in a post-hoc fashion using learnt priors over surfaces and appearance. We train a CNN model to predict the difference in inverse-depth from varying viewpoints of two meshes -- one of low quality that we wish to correct, and one of high-quality that we use as a reference. In contrast to previous work, we pay attention to the problem of excessive smoothing in corrected meshes. We address this with a suitable network architecture, and introduce a loss-weighting mechanism that emphasises edges in the prediction. Furthermore, smooth predictions result in geometrical inconsistencies. To deal with this issue, we present a loss function which penalises re-projection differences that are not due to occlusions. Our model reduces gross errors by 45.3%--77.5%, up to five times more than previous work.