 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Correct 3D Reconstructions from Multiple Views
Paper and Code
Jan 22, 2020

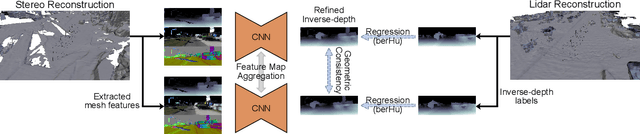
This paper is about reducing the cost of building good large-scale 3D reconstructions post-hoc. We render 2D views of an existing reconstruction and train a convolutional neural network (CNN) that refines inverse-depth to match a higher-quality reconstruction. Since the views that we correct are rendered from the same reconstruction, they share the same geometry, so overlapping views complement each other. We take advantage of that in two ways. Firstly, we impose a loss during training which guides predictions on neighbouring views to have the same geometry and has been shown to improve performance. Secondly, in contrast to previous work, which corrects each view independently, we also make predictions on sets of neighbouring views jointly. This is achieved by warping feature maps between views and thus bypassing memory-intensive 3D computation. We make the observation that features in the feature maps are viewpoint-dependent, and propose a method for transforming features with dynamic filters generated by a multi-layer perceptron from the relative poses between views. In our experiments we show that this last step is necessary for successfully fusing feature maps between views.