 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Planning and Reinforcement Learning-Driven Control of On-Orbit Free-Flying Multi-Arm Robots
Mar 24, 2026This paper presents a hybrid approach that integrates trajectory optimization (TO) and reinforcement learning (RL) for motion planning and control of free-flying multi-arm robots in on-orbit servicing scenarios. The proposed system integrates TO for generating feasible, efficient paths while accounting for dynamic and kinematic constraints, and RL for adaptive trajectory tracking under uncertainties. The multi-arm robot design, equipped with thrusters for precise body control, enables redundancy and stability in complex space operations. TO optimizes arm motions and thruster forces, reducing reliance on the arms for stabilization and enhancing maneuverability. RL further refines this by leveraging model-free control to adapt to dynamic interactions and disturbances. The experimental results validated through comprehensive simulations demonstrate the effectiveness and robustness of the proposed hybrid approach. Two case studies are explored: surface motion with initial contact and a free-floating scenario requiring surface approximation. In both cases, the hybrid method outperforms traditional strategies. In particular, the thrusters notably enhance motion smoothness, safety, and operational efficiency. The RL policy effectively tracks TO-generated trajectories, handling high-dimensional action spaces and dynamic mismatches. This integration of TO and RL combines the strengths of precise, task-specific planning with robust adaptability, ensuring high performance in the uncertain and dynamic conditions characteristic of space environments. By addressing challenges such as motion coupling, environmental disturbances, and dynamic control requirements, this framework establishes a strong foundation for advancing the autonomy and effectiveness of space robotic systems.
Optimal path planning and weighted control of a four-arm robot in on-orbit servicing
Jun 07, 2024This paper presents a trajectory optimization and control approach for the guidance of an orbital four-arm robot in extravehicular activities. The robot operates near the target spacecraft, enabling its arm's end-effectors to reach the spacecraft's surface. Connections to the target spacecraft can be established by the arms through specific footholds (docking devices). The trajectory optimization allows the robot path planning by computing the docking positions on the target spacecraft surface, along with their timing, the arm trajectories, the six degrees of freedom body motion, and the necessary contact forces during docking. In addition, the paper introduces a controller designed to track the planned trajectories derived from the solution of the nonlinear programming problem. A weighted controller formulated as a convex optimization problem is proposed. The controller is defined as the optimization of an objective function that allows the system to perform a set of tasks simultaneously. Simulation results show the application of the trajectory optimization and control approaches to an on-orbit servicing scenario.
Meta Reinforcement Learning for Optimal Design of Legged Robots
Oct 06, 2022
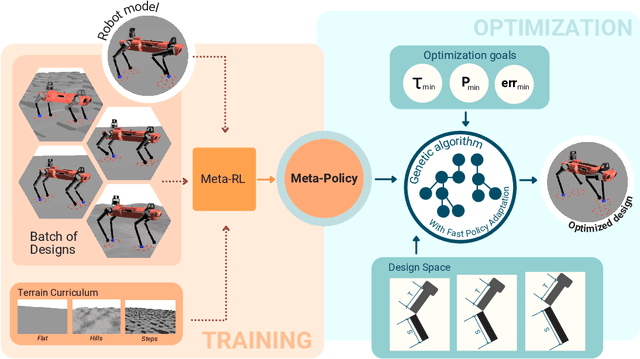
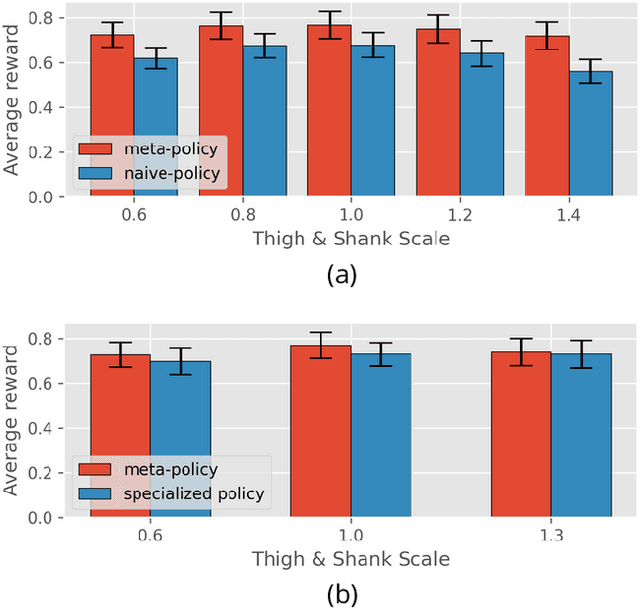

The process of robot design is a complex task and the majority of design decisions are still based on human intuition or tedious manual tuning. A more informed way of facing this task is computational design methods where design parameters are concurrently optimized with corresponding controllers. Existing approaches, however, are strongly influenced by predefined control rules or motion templates and cannot provide end-to-end solutions. In this paper, we present a design optimization framework using model-free meta reinforcement learning, and its application to the optimizing kinematics and actuator parameters of quadrupedal robots. We use meta reinforcement learning to train a locomotion policy that can quickly adapt to different designs. This policy is used to evaluate each design instance during the design optimization. We demonstrate that the policy can control robots of different designs to track random velocity commands over various rough terrains. With controlled experiments, we show that the meta policy achieves close-to-optimal performance for each design instance after adaptation. Lastly, we compare our results against a model-based baseline and show that our approach allows higher performance while not being constrained by predefined motions or gait patterns.